This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether automating a report or setting up retraining pipelines for machine learning models, the idea was always the same: do less manual work and get more consistent results. But automation isnt just for analytics.
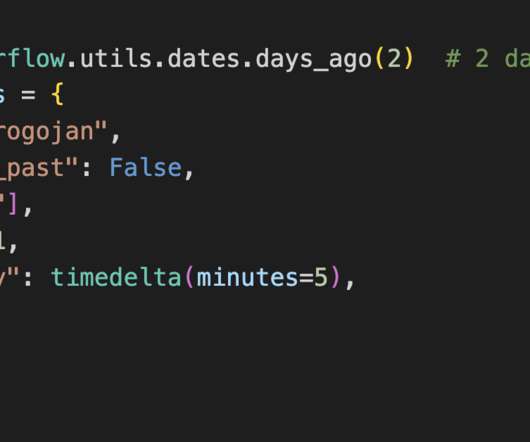
Run DataPipelines 2.1. Batch pipelines 3.3. Stream pipelines 3.4. Event-driven pipelines 3.5. LLM RAG pipelines 4. Introduction Whether you are new to dataengineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up!
In 2023, Talend was acquired by Qlik, combining the two companies data integration and analytics tools under one roof. In January 2024, Talend discontinued Talend Open… Read more The post Alternatives to Talend How To Migrate Away From Talend For Your DataPipelines appeared first on Seattle Data Guy.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers. Nevertheless, setting up a streaming datapipeline to power such dashboards may […] The post DataEngineering for Streaming Data on GCP appeared first on Analytics Vidhya.
In a data-driven world, behind-the-scenes heroes like dataengineers play a crucial role in ensuring smooth data flow. A dataengineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless datapipelines.
Here’s where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024—plus a few predictions of my own. 2025 dataengineering trends incoming. Small data is the future of AI (Tomasz) 7. The lines are blurring for analysts and dataengineers (Barr) 8. Table of Contents 1.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Why Future-Proofing Your DataPipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Resilience and adaptability are the cornerstones of a future-proof datapipeline.
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
We all keep hearing about Arrow this and Arrow that … seems every new tool built today for DataEngineering seems to be at least partly based on Arrow’s in-memory format. So, […] The post PyArrow vs Polars (vs DuckDB) for DataPipelines. appeared first on Confessions of a Data Guy.
This post focuses on practical datapipelines with examples from web-scraping real-estates, uploading them to S3 with MinIO, Spark and Delta Lake, adding some Data Science magic with Jupyter Notebooks, ingesting into Data Warehouse Apache Druid, visualising dashboards with Superset and managing everything with Dagster.
This traditional SQL-centric approach often challenged dataengineers working in a Python environment, requiring context-switching and limiting the full potential of Python’s rich libraries and frameworks. To get started, explore the comprehensive API documentation , which will guide you through every step.
Announcements Hello and welcome to the DataEngineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or data lake. Rudderstack]([link] RudderStack provides all your customer datapipelines in one platform.
Editor’s Note: Launching Data & Gen-AI courses in 2025 I can’t believe DEW will reach almost its 200th edition soon. What I started as a fun hobby has become one of the top-rated newsletters in the dataengineering industry.
Dataengineering can help with it. It is the force behind seamless data flow, enabling everything from AI-driven automation to real-time analytics. Key Trends in DataEngineering for 2025 In the fast-paced world of technology, dataengineering services keep companies that focus on data running.
What is an idempotent function Pre-requisites Why idempotency matters Making your datapipeline idempotent Conclusion Further reading References What is an idempotent function “Idempotence is the property of certain operations in mathematics and computer science whereby they can be applied multiple times without changing the result beyond the (..)
One job that has become increasingly popular across enterprise data teams is the role of the AI dataengineer. Demand for AI dataengineers has grown rapidly in data-driven organizations. But what does an AI dataengineer do? Table of Contents What Does an AI DataEngineer Do?
[link] Jing Ge: Context Matters — The Vision of Data Analytics and Data Science Leveraging MCP and A2A All aspects of software engineering are rapidly being automated with various coding AI tools, as seen in the AI technology radar. Dataengineering is one aspect where I see a few startups starting to disrupt.
Rust has been on my mind a lot lately, probably because of DataEngineering boredom, watching Spark clusters chug along like some medieval farm worker endlessly trudging through the muck and mire of life. appeared first on Confessions of a Data Guy.
The Critical Role of AI DataEngineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Develop modular, reusable components for end-to-end AI pipelines.
Building datapipelines is a very important skill that you should learn as a dataengineer. A datapipeline is just a series of procedures that transport data from one location to another, frequently changing it along the way.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch datapipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Datapipeline asset management with Dataflow.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
In the vast world of data, it’s not just about gathering and analyzing information anymore; it’s also about ensuring that datapipelines, processes, and platforms run seamlessly and efficiently.
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the dataengineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. These are common LinkedIn requests.
DataEngineering Weekly readers get 15% discount by registering the following link, [link] Gustavo Akashi: Building datapipelines effortlessly with a DAG Builder for Apache Airflow Every code-first data workflow grew into a UI-based or Yaml-based workflow.
Try Astro Free → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the dataengineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. The results? will shape the future of DataOps.
Summary Datapipelines are the core of every data product, ML model, and business intelligence dashboard. The folks at Rivery distilled the seven principles of modern datapipelines that will help you stay out of trouble and be productive with your data.
Get the report → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the dataengineering community. Data Council 2025 is set for April 22-24 in Oakland, CA.
The article summarizes the recent macro trends in AI and dataengineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. As these assistants evolve, they signal a future where scalable, low-latency datapipelines become essential for seamless, intelligent user experiences.
Get the report → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the dataengineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. What we learned?
Learn dataengineering, all the references ( credits ) This is a special edition of the Data News. But right now I'm in holidays finishing a hiking week in Corsica 🥾 So I wrote this special edition about: how to learn dataengineering in 2024. Who are the dataengineers?
It’s unavoidable that as businesses demand that their data teams implement AI, they will also realize that dataengineers are a crucial piece of the datapipeline.
We are excited to announce the availability of datapipelines replication, which is now in public preview. In the event of an outage, this powerful new capability lets you easily replicate and failover your entire data ingestion and transformations pipelines in Snowflake with minimal downtime.
Apache Airflow is a very popular tool that dataengineers rely on. Why do dataengineers like Airflow? What are… Read more The post What Is Apache Airflow – DataEngineering Consulting appeared first on Seattle Data Guy. Also, what does Apache Airflow event do? What is a DAG?
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your datapipelines, and more. Should we term this as an AI product curve of disappointment ?
Building reliable datapipelines is a complex and costly undertaking with many layered requirements. In order to reduce the amount of time and effort required to build pipelines that power critical insights Manish Jethani co-founded Hevo Data. Data stacks are becoming more and more complex.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your datapipelines, and more. As I have shared , its impact on dataengineering is exciting.
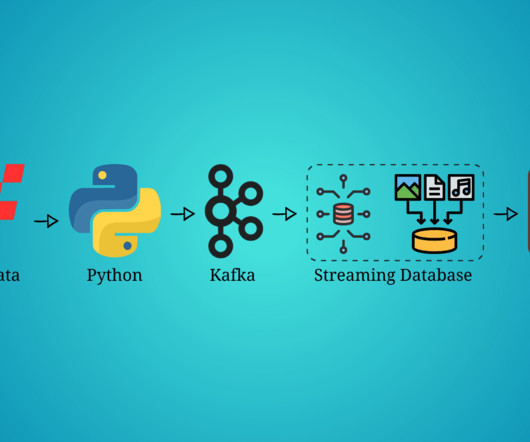
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable DataPipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community! In this video, Sr.
[link] Atlassian: Lithium - elevating ETL with ephemeral and self-hosted pipelines The article introduces Lithium, an ETL++ platform developed by Atlassian for dynamic and ephemeral datapipelines, addressing unique needs like user-initiated migrations and scheduled backups.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content