This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many companies looking to migrate to the cloud go from SQL Server to Snowflake. One of the reasons and common benefits was that teams found it far easier to manage that SQL Server and in almost every… Read more The post How To Migrate From SQL Server To Snowflake appeared first on Seattle Data Guy.
Announcements Hello and welcome to the DataEngineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or data lake. Support DataEngineering Podcast
So, we are […] The post How to Normalize Relational Databases With SQL Code? If a corrupted, unorganized, or redundant database is used, the results of the analysis may become inconsistent and highly misleading. appeared first on Analytics Vidhya.
Introduction Dataengineering is the field of study that deals with the design, construction, deployment, and maintenance of data processing systems. The goal of this domain is to collect, store, and process data efficiently and efficiently so that it can be used to support business decisions and power data-driven applications.
Introduction Structured Query Language is a powerful language to manage and manipulate data stored in databases. SQL is widely used in the field of data science and is considered an essential skill to have if you work with data.
Editor’s Note: Launching Data & Gen-AI courses in 2025 I can’t believe DEW will reach almost its 200th edition soon. What I started as a fun hobby has become one of the top-rated newsletters in the dataengineering industry. The blog narrates a few examples of Pipe Syntax in comparison with the SQL queries.
This results in the generation of so much data daily. This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases.
Introduction SQL injection is an attack in which a malicious user can insert arbitrary SQL code into a web application’s query, allowing them to gain unauthorized access to a database. We can use this to steal sensitive information or make unauthorized changes to the data stored in the database.
link] Sponsored: The Ultimate Guide to Apache Airflow® DAGs Download this free 130+ page eBook for everything a dataengineer needs to know to take their DAG writing skills to the next level (+ plenty of example code). link] All rights reserved, ProtoGrowth Inc.,
Introduction SQL is a database programming language created for managing and retrieving data from Relational databases like MySQL, Oracle, and SQL Server. SQL(Structured Query Language) is the common language for all databases. In other terms, SQL is a language that communicates with databases.
5 SQL Visualization Tools for DataEngineers • Free TensorFlow 2.0 Complete Course • The Importance of Probability in Data Science • 4 Ways to Rename Pandas Columns • 5 Statistical Paradoxes Data Scientists Should Know
Introduction Setup SQL tips 1. Handy functions for common data processing scenarios 1.1. STRUCT data types are sorted based on their keys from left to right 1.4. Need to filter on WINDOW function without CTE/Subquery use QUALIFY 1.2. Need the first/last row in a partition, use DISTINCT ON 1.3.
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. Can you describe what RisingWave is and the story behind it?
[link] Jing Ge: Context Matters — The Vision of Data Analytics and Data Science Leveraging MCP and A2A All aspects of software engineering are rapidly being automated with various coding AI tools, as seen in the AI technology radar. Dataengineering is one aspect where I see a few startups starting to disrupt.
Before Hoptimator, Pinot ingestion often required data producers to create and manage separate, Pinot-specific preprocessing jobs to optimize data, such as re-keying, filtering, and pre-aggregating. reducing user friction, operator toil, and resource consumption on Pinot servers, while automating pipeline management.
I was wondering the other day … since Polars now has a SQL context and is getting more popular by the day, do I need DuckDB anymore? You might think […] The post DuckDB vs Polars for DataEngineering. appeared first on Confessions of a Data Guy. These two tools are hot.
I mean you have a problem if you could use Polars Python, and you find yourself using […] The post Polars – Laziness and SQL Context. appeared first on Confessions of a Data Guy. It’s gotten so bad, I’ve started to use it in my Rust code on the side, Polars that is.
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQL Databases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake.
The Critical Role of AI DataEngineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. How does a self-driving car understand a chaotic street scene?
Editor’s Note: A New Series on DataEngineering Tools Evaluation There are plenty of data tools and vendors in the industry. DataEngineering Weekly is launching a new series on software evaluation focused on dataengineering to better guide dataengineering leaders in evaluating data tools.
Save Your Spot → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the dataengineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. link] BVP: Roadmap: Data 3.0
No Python, No SQL Templates, No YAML: Why Your Open Source Data Quality Tool Should Generate 80% Of Your Data Quality Tests Automatically As a dataengineer, ensuring data quality is both essential and overwhelming. Even if dataengineers had the resources, they lacked the full context of data use.
One job that has become increasingly popular across enterprise data teams is the role of the AI dataengineer. Demand for AI dataengineers has grown rapidly in data-driven organizations. But what does an AI dataengineer do? Table of Contents What Does an AI DataEngineer Do?
In that time there have been a number of generational shifts in how dataengineering is done. Materialize’s PostgreSQL-compatible interface lets users leverage the tools they already use, with unsurpassed simplicity enabled by full ANSI SQL support.
[link] Instacart: Data Science Spotlight - Cracking the SQL Interview at Instacart (LLM Edition) Instacart writes about integrating LLM in their interview process and how it helps them identify the right candidates. Swiggy recently wrote about its internal platform, Hermes, a text-to-SQL solution.
Learn dataengineering, all the references ( credits ) This is a special edition of the Data News. But right now I'm in holidays finishing a hiking week in Corsica 🥾 So I wrote this special edition about: how to learn dataengineering in 2024. Who are the dataengineers?
As dataengineers, understanding the intricacies of your Databricks environment is important. But raw system data can be tricky to navigate, and sometimes you just need a quick answer to that burning question. Wow the team with insights in your Jobs, SQL warehouses, APC clusters, and DLT usage.
In today’s data-driven world, developer productivity is essential for organizations to build effective and reliable products, accelerate time to value, and fuel ongoing innovation. While the Python API connector remains available for specific SQL use cases, the new API is designed to be your go-to solution.
In this episode Razi Raziuddin shares how dataengineering teams can support the machine learning workflow through the development and support of systems that empower data scientists and ML engineers to build and maintain their own features. What is the role of the dataengineer in supporting those interfaces?
Announcements Hello and welcome to the DataEngineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team.
GetInData writes an excellent summary of adding data quality checks in a Flink streaming pipeline. link] Fernando Borretti: Composable SQL One of the biggest challenges in SQL is the unit testing. The author highlights three key challenges in SQL.
New SQL Practice Problems I’m trying something new. I get a lot of questions from folks about getting into the DataEngineering space, how to get better, grow, learn, etc. SQL Practice Problems. Some moons ago I wrote a DataEngineering Practice repo on GitHub for free, and some 1.2K
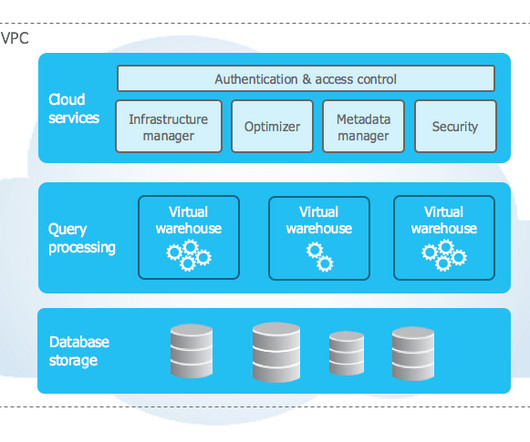
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Data lakes are notoriously complex. Visit: dataengineeringpodcast.com/data-council today. Your first 30 days are free!
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. As I have shared , its impact on dataengineering is exciting.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community! In this video, Sr.
SQL and Python Interview Questions for Data Analysts • 5 SQL Visualization Tools for DataEngineers • 5 Free Tools For Detecting ChatGPT, GPT3, and GPT2 • Top Free Resources To Learn ChatGPT • Free TensorFlow 2.0
dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. In the ELT, the load is done before the transform part without any alteration of the data leaving the raw data ready to be transformed in the data warehouse. dbt Labs also popularised the analytics engineer role.
Context and Motivation dbt (Data Build Tool): A popular open-source framework that organizes SQL transformations in a modular, version-controlled, and testable way. Databricks: A platform that unifies dataengineering and data science pipelines, typically with Spark (PySpark, Scala) or SparkSQL.
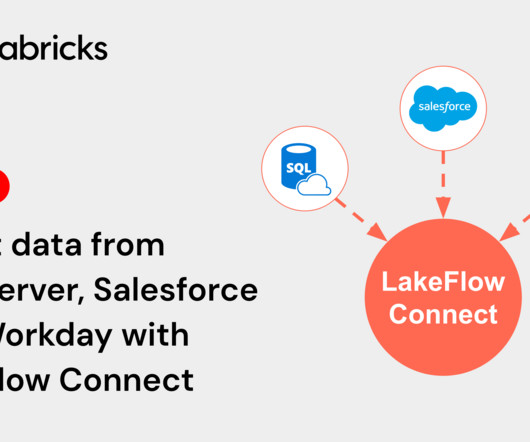
We’re excited to announce the Public Preview of LakeFlow Connect for SQL Server, Salesforce, and Workday. These ingestion connectors enable simple and efficient.
Thinking about and contemplating life and dataengineering … something flitted across my […] The post Datafusion SQL CLI – Look Ma, I made a new ETL tool. appeared first on Confessions of a Data Guy.
With dbt, you can apply software engineering practices to SQL development. Managing your SQL patrimony has never been easier. So, yes, dbt is cool but there is a common pattern with it: you accumulate SQL queries. Fast forward to 2 years later, you find yourself with hundreds or thousands of SQL queries.
In the world of dataengineering, Maxime Beauchemin is someone who needs no introduction. Currently, Maxime is CEO and co-founder of Preset , a fast-growing startup that’s paving the way forward for AI-enabled data visualization for modern companies. Enter, the dataengineer. What is a dataengineer today?
In this article, we will discuss use cases and methods for using ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes along with SQL to integrate data from various sources.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content