

How to learn data engineering
Christophe Blefari
JANUARY 20, 2024
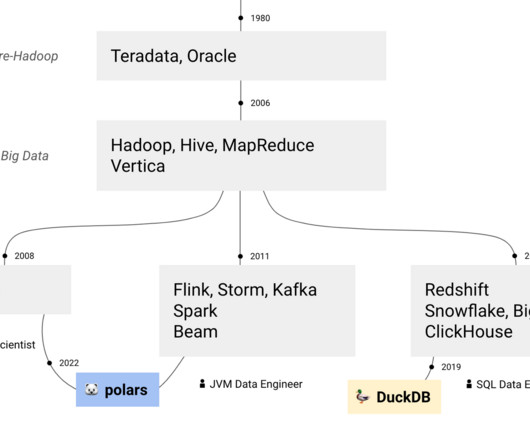
Learn data engineering, all the references ( credits ) This is a special edition of the Data News. But right now I'm in holidays finishing a hiking week in Corsica 🥾 So I wrote this special edition about: how to learn data engineering in 2024. What is Hadoop? Who are the data engineers?
















































Let's personalize your content