This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated datagovernance.
Summary Datagovernance is a practice that requires a high degree of flexibility and collaboration at the organizational and technical levels. The growing prominence of cloud and hybrid environments in data management adds additional stress to an already complex endeavor.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. What are the other systems that feed into and rely on the Trino/Iceberg service?
Implement better datagovernance by easily tracking and handling sensitive data The Lineage Visualization Interface (public preview) allows customers to easily track the flow of data and ML assets with an interactive interface in Snowsight.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
In an effort to better understand where datagovernance is heading, we spoke with top executives from IT, healthcare, and finance to hear their thoughts on the biggest trends, key challenges, and what insights they would recommend. Get the Trendbook What is the Impact of DataGovernance on GenAI?
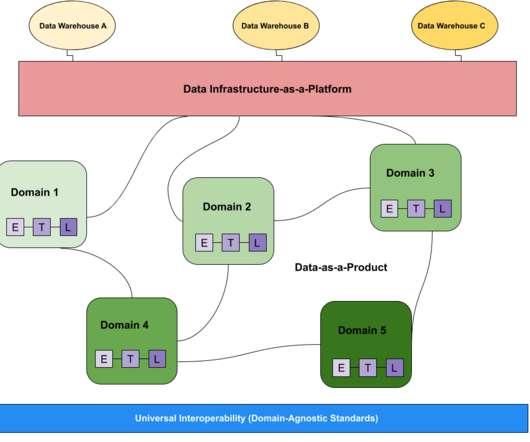
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ? Data As Code is a very strong choice : we do not want any UI because it is an heritage of the ETL period.
And if data security tops IT concerns, datagovernance should be their second priority. Not only is it critical to protect data, but datagovernance is also the foundation for data-driven businesses and maximizing value from data analytics. But it’s still not easy. But it’s still not easy.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
The Precisely team recently had the privilege of hosting a luncheon at the Gartner Data & Analytics Summit in London. It was an engaging gathering of industry leaders from various sectors, who exchanged valuable insights into crucial aspects of datagovernance, strategy, and innovation.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
Using the metaphor of a museum curator carefully managing the precious resources on display and in the vaults, he discusses the various layers of an enterprise data strategy. In terms of infrastructure, what are the components of a modern data architecture and how has that changed over the years?
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. How Apache Iceberg tables structure metadata. Is your datalake a good fit for Iceberg? Limited data type support. Image courtesy of Dremio.
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
It means defining that data by documenting relationships between creator and context (like customers and their orders), establishing clear business definitions (what exactly counts as an “active user”?), and maintaining metadata about data freshness, quality, and lineage (more on that in a moment).
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x.
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
This includes pipelines and transformations with Snowpark, Streams, Tasks and Dynamic Tables (public preview soon); extending AI and ML to Iceberg with Snowflake Cortex AI; performing storage maintenance with capabilities like automatic clustering and compaction; as well as securely collaborating on live data shares.
At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files. Table formats incorporate aspects like columns, rows, data types, and relationships, but can also include information about the structure of the data itself.
The table information (such as schema, partition) is stored as part of the metadata (manifest) file separately, making it easier for applications to quickly integrate with the tables and the storage formats of their choice. Enterprise grade security and datagovernance – centralized data authorization to lineage and auditing.
Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata. As data grows exponentially, so do the complexities of managing and leveraging it to fuel AI and analytics.
Whether you’re a data scientist, data engineer, or business analyst, keeping track of your data’s origin, transformation, and movement is crucial for maintaining transparency, enforcing datagovernance, and ensuring data quality. The Spark datalake lineage example is helpful for context here.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud data warehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Best Practice 2. Best Practice 3.
The cloud is especially well-suited to large-scale storage and big data analytics, due in part to its capacity to handle intensive computing requirements at scale. BI platforms and data warehouses have been replaced by modern datalakes and cloud analytics solutions. Secure data exchange takes on much greater importance.
If the transformation step comes after loading (for example, when data is consolidated in a datalake or a data lakehouse ), the process is known as ELT. You can learn more about how such data pipelines are built in our video about data engineering. Abstraction layer.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Below we’ll cover the basics of data lineage, why it is important, and how Magpie enables teams to trust their data with this important new release. What is Data Lineage? Data lineage refers to the entire lifecycle of a dataset from its sources of origin all the way to its current state.
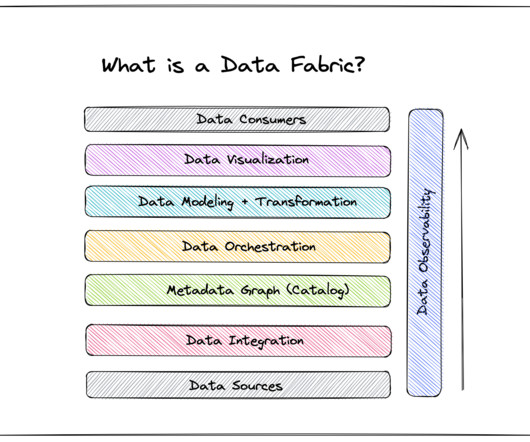
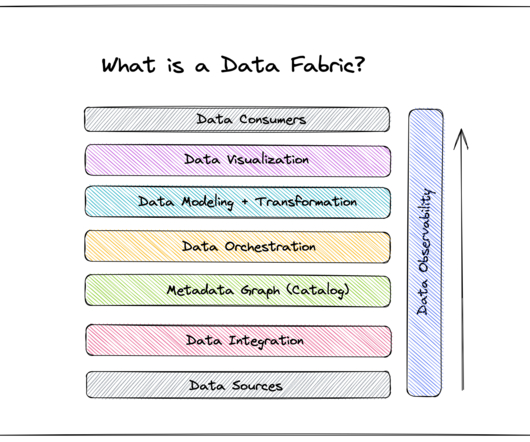
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , datalakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
The group kicked off the session by exchanging ideas about what it means to have a modern data architecture. Atif Salam noted that as recently as a year ago, the primary focus in many organizations was on ingesting data and building datalakes.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake. See below. .
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – datalakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, datalakes, frontends, and pipelines/ETL. pipelines, Azure Data Bricks.
Data fabric is a centralized platform architecture originating from a curated metadata layer that sits on top of an organization’s data infrastructure. Every time a new data source is added, the metadata layer is updated to define how and when that data should be used. Increasing speed.
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, datalakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
In this post, we’ll discuss what, exactly, a data fabric is, how other companies have used it, and how you can build one at your company. Table of Contents What is a data fabric? A data fabric infuses datagovernance and security across all forms of data, no matter its origin or destination within the organization.
In this post, we’ll discuss what, exactly, a data fabric is, how other companies have used it, and how you can build one at your company. Table of Contents What is a data fabric? A data fabric infuses datagovernance and security across all forms of data, no matter its origin or destination within the organization.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
In this very simplified example, we can see an ELT: Some pipeline tasks, probably running by Airflow , are scraping external data sources and collecting data from there. Those tasks are saving the extracted data in the datalake (or warehouse or lakehouse). This technique focuses directly on the data (vs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content