This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Modern businesses aspire to be data driven, and technologists enjoy working through the challenge of building data systems to support that goal. Datagovernance is the binding force between these two parts of the organization. At what point does a lack of an explicit governance policy become a liability?
Summary Datagovernance is a term that encompasses a wide range of responsibilities, both technical and process oriented. One of the more complex aspects is that of access control to the data assets that an organization is responsible for managing. What is datagovernance? How is the Immuta platform architected?
Summary Datagovernance is a phrase that means many different things to many different people. This is because it is actually a concept that encompasses the entire lifecycle of data, across all of the people in an organization who interact with it. RudderStack’s smart customer datapipeline is warehouse-first.
These incidents serve as a stark reminder that legacy datagovernance systems, built for a bygone era, are struggling to fend off modern cyber threats. They react too slowly, too rigidly, and cant keep pace with the dynamic, sophisticated attacks occurring today, leaving hackable data exposed.
Snowflake’s new Python API (GA soon) simplifies datapipelines and is readily available through pip install snowflake. Additionally, Dynamic Tables are a new table type that you can use at every stage of your processing pipeline. Interact with Snowflake objects directly in Python. Automate or code, the choice is yours.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
In this blog, we’ll highlight the key CDP aspects that provide datagovernance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Sketch of the end-to-end datapipeline. Apache Atlas as a fundamental part of SDX. Assets: Files. RDBMS Database Table.
AI data engineers are data engineers that are responsible for developing and managing datapipelines that support AI and GenAI data products. Essential Skills for AI Data Engineers Expertise in DataPipelines and ETL Processes A foundational skill for data engineers?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
How does the focus on data assets/data products shift your approach to observability as compared to a table/pipeline centric approach? With the focus on sharing ownership beyond the boundaries on the data team there is a strong correlation with datagovernance principles. Want to see Starburst in action?
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. The anticipated growth in datapipelines presents both challenges and opportunities.
The data generated was as varied as the departments relying on these applications. Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex datagovernance processes and costly datapipeline maintenance.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
[Starburst Logo]([link] This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
Key Takeaways Data quality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Data observability continuously monitors datapipelines and alerts you to errors and anomalies. stored: where is it located?
Datagovernance refers to the set of policies, procedures, mix of people and standards that organisations put in place to manage their data assets. It involves establishing a framework for data management that ensures data quality, privacy, security, and compliance with regulatory requirements.
Business Intelligence Needs Fresh Insights: Data-driven organizations make strategic decisions based on dashboards, reports, and real-time analytics. If data is delayed, outdated, or missing key details, leaders may act on the wrong assumptions. Poor data management can lead to compliance risks, legal issues, and reputational damage.
To finish the trilogy (Dataops, MLops), let’s talk about DataGovOps or how you can support your DataGovernance initiative. Last part, it was added the data security and privacy part. Every datagovernance policy about this topic must be read by a code to act in your data platform (access management, masking, etc.)
[Starburst Logo]([link] This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality datapipelines on the data lake. Want to see Starburst in action? Want to see Starburst in action?
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. The anticipated growth in datapipelines presents both challenges and opportunities.
Dagster offers a new approach to building and running data platforms and datapipelines. Starburst Logo]([link] This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ? We want interoperability for any data stored versus we have to think how to store the data in a specific node to optimize the processing.
[Starburst Logo]([link] This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality datapipelines on the data lake. Want to see Starburst in action? Want to see Starburst in action?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
The Recommendation Platform (RecP) leverages a structured pipeline approach to standardize the resolution of machine learning challenges, allowing for component reusability across various use cases and enabling customers to define complex recommendation logic.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Dagster offers a new approach to building and running data platforms and datapipelines. Starburst Logo]([link] This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
Dagster offers a new approach to building and running data platforms and datapipelines. Starburst Logo]([link] This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
[Starburst Logo]([link] This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality datapipelines on the data lake. Want to see Starburst in action? Want to see Starburst in action?
Data is among your company’s most valuable commodities, but only if you know how to manage it. More data, more access to data, and more regulations mean datagovernance has become a higher-stakes game. DataGovernance Trends The biggest datagovernance trend isn’t really a trend at all—rather, it’s a state of mind.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, datagovernance, and data security operations. . Airflow — An open-source platform to programmatically author, schedule, and monitor datapipelines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
[Starburst Logo]([link] This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality datapipelines on the data lake. Want to see Starburst in action? Want to see Starburst in action?
The organizations that win in 2025 wont be the ones with the biggest AI modelstheyll be the ones with real-time, AI-ready data infrastructures that enable continuous learning, adaptive decision-making, and assist regulatory compliance at scale. Static AI models trained on stale data will deliver poor outcomes. Whats changing?
Dagster offers a new approach to building and running data platforms and datapipelines. Starburst Logo]([link] This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
[Starburst Logo]([link] This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
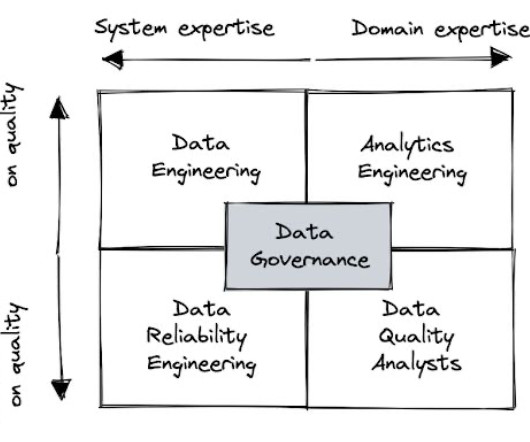
This post will focus on the most common team ownership models including: data engineering, data reliability engineering, analytics engineering, data quality analysts, and datagovernance teams. Why is data quality ownership important? The governance team treats every team output as a data product.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines.
We were excited to sit down with Skyscanner’s Principal Software Engineer JM Laplante and Director of Engineering Michael Ewins — fresh off his inspiring presentation at Big Data London — to learn how their teams are harnessing data lineage and observability to enable datagovernance at scale.
We were excited to sit down with Skyscanner’s Principal Software Engineer JM Laplante and Director of Engineering Michael Ewins — fresh off his inspiring presentation at Big Data London — to learn how their teams are harnessing data lineage and observability to enable datagovernance at scale.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content