This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Datagovernance is a term that encompasses a wide range of responsibilities, both technical and process oriented. One of the more complex aspects is that of access control to the data assets that an organization is responsible for managing. What is datagovernance? How is the Immuta platform architected?
These incidents serve as a stark reminder that legacy datagovernance systems, built for a bygone era, are struggling to fend off modern cyber threats. They react too slowly, too rigidly, and cant keep pace with the dynamic, sophisticated attacks occurring today, leaving hackable data exposed.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
Business Intelligence Needs Fresh Insights: Data-driven organizations make strategic decisions based on dashboards, reports, and real-time analytics. If data is delayed, outdated, or missing key details, leaders may act on the wrong assumptions. Poor data management can lead to compliance risks, legal issues, and reputational damage.
Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of data quality tests. They are all in the realm of software, domain-specific language to help you write data quality tests. Download Now Request Demo
The Future of Enterprise AI: Moving from Vision to Reality Successfully integrating GenAI with real-time data streaming requires strategic investments across infrastructure, datagovernance, and AI model development. Sherlock monitors your data streams to identify sensitive information.
Ensure strong datagovernance and auditability. Support time travel queries and rollback capabilities for data recovery or compliance. This setup is particularly beneficial for e-commerce platforms and content providers aiming to enhance user engagement through data-driven decisions. GitHub Repository: tj /iceberg-demo 3.
Are you spending too much time maintaining your datapipeline? Snowplow empowers your business with a real-time event datapipeline running in your own cloud account without the hassle of maintenance. Set up a demo and mention you’re a listener for a special offer!
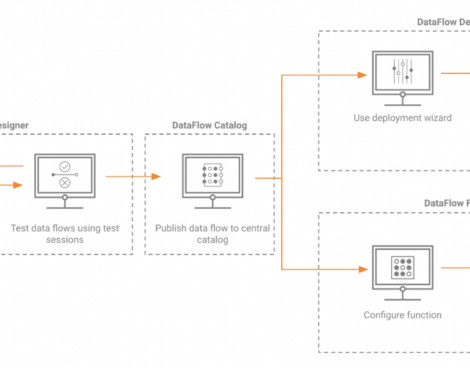
Data leaders will be able to simplify and accelerate the development and deployment of datapipelines, saving time and money by enabling true self service. It is no secret that data leaders are under immense pressure. For more information or to see a demo, go to the DataFlow Product page.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Limited resources: Data management has always been resource intensive, but not all organizations can maintain a full data team. Without suitable resources for company-wide data management, it’s easier to fall behind. Find out how DataOS can help you chip away at your data debt.
This mission culminates in the esteemed recognition of honorable mention in Gartner’s 2023 Magic Quadrant for Data Integration, showcasing commitment to excellence and industry leadership in the data-driven era. Data engineering excellence Modern offers robust solutions for building, managing, and operationalizing datapipelines.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
By omitting the complexity and debt of datapipelines resulting from multiple fragmented tools in the ‘MAD Ecosystem,’ these loops can be efficiently maintained Process Angle : Administering Data Products involves a combination of technology, culture, and process. Read more about our partnership.
This mission culminates in the esteemed recognition of honorable mention in Gartner’s 2023 Magic Quadrant for Data Integration, showcasing commitment to excellence and industry leadership in the data-driven era. Data engineering excellence Modern offers robust solutions for building, managing, and operationalizing datapipelines.
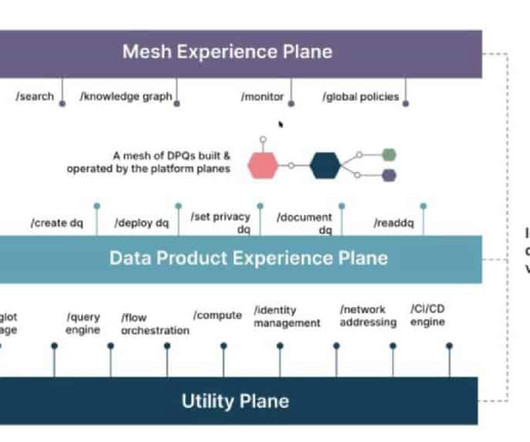
The move to productize data also requires a way to package data products so they are easily and uniformly discoverable and consumed. Data products must be properly designed and organized to be reused across the organization. Then you need to know more about data mesh architecture. Does that align with your business goals?
But is there more to generative AI than a fancy demo on Twitter? And how will it impact data? How generative AI will disrupt data With the advent of OpenAI’s DALL-E and ChatGPT, large language models became much more useful to the vast majority of humans. Request a demo today. Let’s assess. Will you join us?
Respondents averaged 642 tables across their data lake, lakehouse, or warehouse environments. Respondents averaged 290 manually-written tests across their datapipelines. Check out the full report , including commentary and reactions from nearly a dozen industry-leading data executives.
Of course, there were plenty of flashy generative demos (like Shutterstock AI)—not to mention a couple of live snafus—but these were merely a light palette cleanser between keynotes as these events hurdled toward the real star of the shows—data enablement. Look, we’ve all been told there’s data in the LLM hills.
We’re also excited to announce Monte Carlo’s participation in the Alation Open Data Quality Initiative , a program designed to give Alation customers the freedom to choose the data quality or observability solution of their choice to expand data trust in the Alation platform. See you there!
Strong datagovernance is essential Risks and challenges associated with using customer data–such as concerns around privacy and security–can derail insights. ABAC governance enables flexible and scalable policies that adapt to changing or new compliance regulations.
Strong datagovernance is essential Risks and challenges associated with using customer data–such as concerns around privacy and security–can derail insights. ABAC governance enables flexible and scalable policies that adapt to changing or new compliance regulations.
Strong datagovernance is essential Risks and challenges associated with using customer data–such as concerns around privacy and security–can derail insights. ABAC governance enables flexible and scalable policies that adapt to changing or new compliance regulations.
The learning goes back to the fundamentals of pipeline design principles. Regularly review if pipelines are still required. Minimize the data used in pipelines, aka do incremental datapipeline design. Optimize pipeline schedules. Filter data effectively to make sure the query uses partition pruning.
Simultaneously, Monte Carlo provides CDOs and other data stakeholders with a holistic view of their company’s data health and reliability across critical business use cases. We are delighted to partner with Monte Carlo for their data observability capabilities,” said Tarik Dwiek, Director of Technology Alliances at Snowflake.
Long-term usability Data should be structured in a way that makes sense not just for todays teams but for future employees, too. Your datapipelines need regular monitoring, too. Lets look into building responsible and long-lasting data practices. Just clean, accurate, and sustainable data that you can trust.
Integrated Security & Governance Features Ensuring that your data is protected and secure is one of our top priorities. We’ve designed Magpie to keep you from putting out fires like broken datapipelines with the built-in features mentioned above. The time to identify more insights out of huge sets of data.
Besides these categories, specialized solutions tailored specifically for particular domains or use cases also exist, such as extract, transform and load (ETL) tools for managing datapipelines, data integration tools for combining information from disparate sources or systems and more.
Key Responsibilities of Data Owners The primary responsibility of a data owner is ensuring the quality, accuracy, and integrity of their assigned data assets. Career advancement: As organizations become more data-centric, your role as a data owner offers opportunities for career growth.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Join Monte Carlo for a deep dive session into how datagovernance leaders can take their data quality strategies to the next level with end-to-end data observability.
Common Challenges in Data Versioning While data versioning offers many benefits, it also comes with its own set of challenges: Versioning Large Datasets : Managing multiple versions of large datasets can be challenging due to additional storage and performance requirements. Don’t just version your data – observe it.
By omitting the complexity and debt of datapipelines resulting from multiple fragmented tools in the ‘MAD Ecosystem,’ these loops can be efficiently maintained. Process Angle : Administering Data Products involves a combination of technology, culture, and process.
By omitting the complexity and debt of datapipelines resulting from multiple fragmented tools in the ‘MAD Ecosystem,’ these loops can be efficiently maintained. Process Angle : Administering Data Products involves a combination of technology, culture, and process.
In addition, a CDP owned and controlled by the marketing department may not get the full attention of already overwhelmed IT engineers, becoming an afterthought regarding datagovernance. As a result, CDPs may be less secure than other data stores even though they hold a lot of customer PII.
With the monolithic architectures most organizations have today, business users are stuck, constantly waiting for new datapipelines to be built or amended based on their requests. Data engineers aren’t huge fans of this paradigm either. But they’re living in what is essentially the opposite of their fantasy.
You may even want to set data SLAs for your most important tables with specific data freshness and overall uptime targets. Datagovernance frameworks can be implemented to define roles, responsibilities, and processes for managing data quality across the organization. Request a demo of Monte Carlo now.
Our intelligent datapipelines detect and respond to changes, ensure data quality, and efficiently use cloud resources—so you can spend less time on implementing your data mesh architecture and more time reaping the benefits. Ready to take a look?
Source: The Data Team’s Guide to the Databricks Lakehouse Platform Integrating with Apache Spark and other analytics engines, Delta Lake supports both batch and stream data processing. Besides that, it’s fully compatible with various data ingestion and ETL tools.
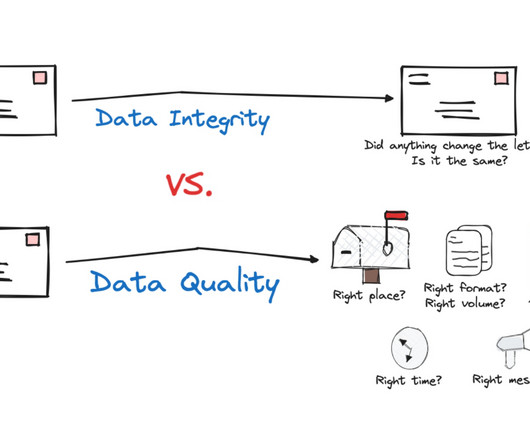
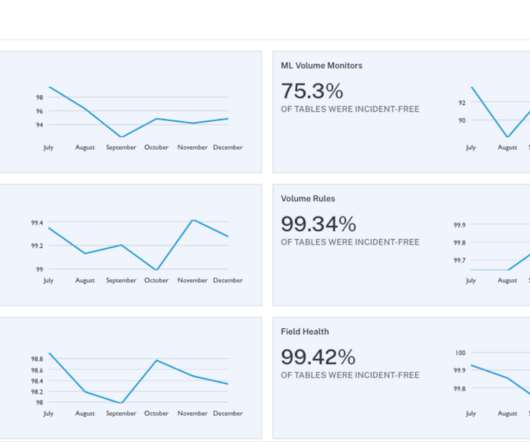
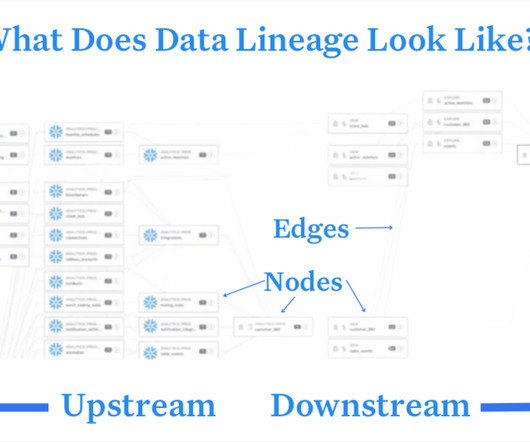
Data lineage , an automated visualization of the relationships for how data flows across tables and other data assets, is a must-have in the data engineering toolbox. Not only is it helpful for datagovernance and compliance use cases, it also plays a starring role as one of the 5 pillars of data observability.
To make a more informed decision, enquire about demos and do your own in-depth research. Oracle Data Integrator, IBM InfoSphere, Snaplogic, Xplenty, and. The platform’s main capabilities comprise data integration, data quality assurance, and datagovernance. Here, we’ll be comparing such vendors as.
Data lineage helps ensure you have clear lines of accountability that data team structure–centralized, center of excellence , data mesh– you use or however your datapipelines evolve. DataGovernance and Compliance The only things propagating faster than data are data regulations.
Data Warehouse Security Best Practices Datagovernance is critical to the protection of both internal and customer data. Before you begin any data warehouse migration, take the time to thoroughly review your data security protocols. Send us a note or check out our demo below!
In the same conference a lot of other talks took place here a few selection you should check out: How to pivot your data team from a service team to a value-generator — Very often data teams struggle in delivering value or in finding what's their real identity.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content