

Low Friction Data Governance With Immuta
Data Engineering Podcast
DECEMBER 21, 2020
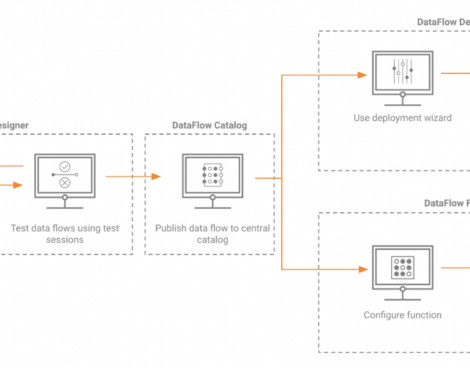
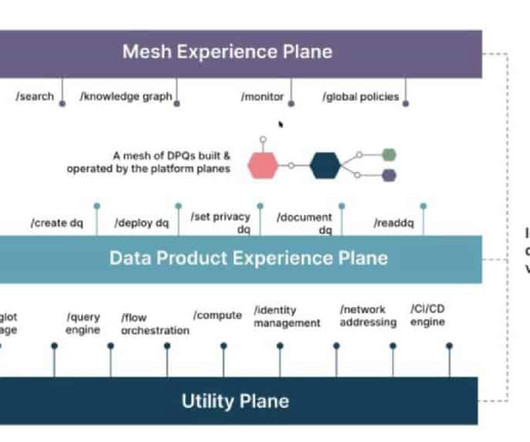
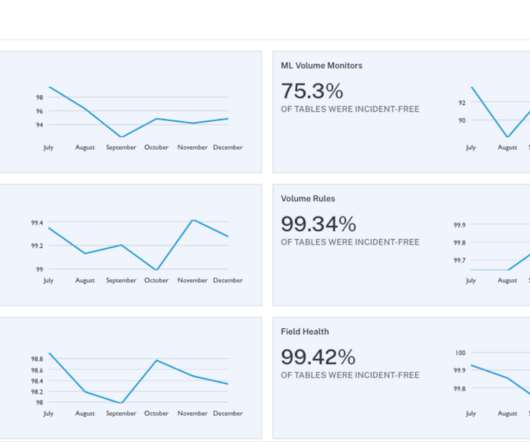
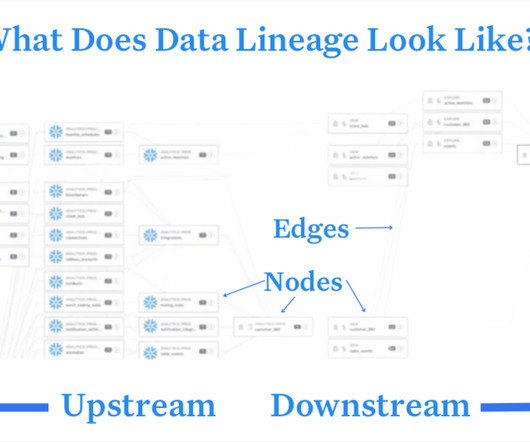
Summary Data governance is a term that encompasses a wide range of responsibilities, both technical and process oriented. One of the more complex aspects is that of access control to the data assets that an organization is responsible for managing. What is data governance? How is the Immuta platform architected?







































Let's personalize your content