This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To achieve accurate and reliable results, businesses need to ensure their data is clean, consistent, and relevant. This proves especially difficult when dealing with large volumes of high-velocity data from various sources. Here are the critical steps enterprises should take to turn this vision into a tangible, scalable solution.
Process Analytics. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, datagovernance, and data security operations. . Reflow — A system for incremental dataprocessing in the cloud.
Running an entire app within the brand’s Snowflake account For many brands, sharing access to data with third parties, even if the data resides within their data platform, presents security and datagovernance concerns that can take months to overcome or prevent an organization from adopting the technology.
Thoughtworks: Measuring the Value of a Data Catalog The cost & effort value proportion for a Data Catalog implementation is always questionable in a large-scale data infrastructure. Thoughtworks, in combination with Adevinta, published a three-phase approach to measure the value of a data catalog.
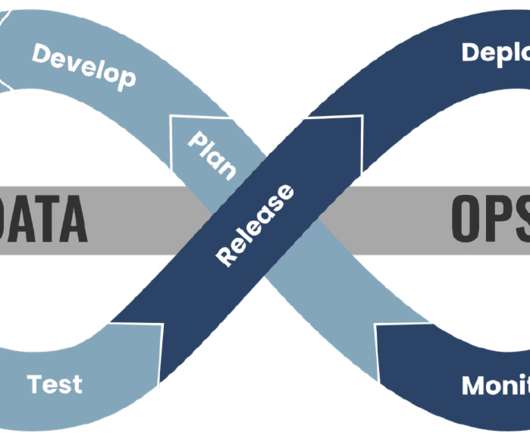
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Accelerated Data Analytics DataOps tools help automate and streamline various dataprocesses, leading to faster and more efficient data analytics.
Challenges of Legacy Data Architectures Some of the main challenges associated with legacy data architectures include: Lack of flexibility: Traditional data architectures are often rigid and inflexible, making it difficult to adapt to changing business needs and incorporate new data sources or technologies.
Whether it is intended for analytics purposes, application development, or machine learning, the aim of data ingestion is to ensure that data is accurate, consistent, and ready to be utilized. It is a crucial step in the dataprocessing pipeline, and without it, we’d be lost in a sea of unusable data.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. Datagovernance also involves implementing data lineage and data cataloging.
What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional dataprocessing methods. The real-time or near-real-time nature of Big Data poses challenges in capturing and processingdata rapidly.
DataOps practices help organizations establish robust datagovernance policies and procedures, ensuring that data is consistently validated, cleansed, and transformed to meet the needs of various stakeholders. One key aspect of datagovernance is data quality management.
Data Quality Rules Data quality rules are predefined criteria that your data must meet to ensure its accuracy, completeness, consistency, and reliability. These rules are essential for maintaining high-quality data and can be enforced using datavalidation, transformation, or cleansing processes.
These processes are prone to errors, and poor-quality data can lead to delays in order processing and a host of downstream shipping and invoicing problems that put your customer relationships at risk. It’s clear that automation transforms the way we work, in SAP customer master dataprocesses and beyond.
These experts will need to combine their expertise in dataprocessing, storage, transformation, modeling, visualization, and machine learning algorithms, working together on a unified platform or toolset.
Data Integration and Transformation, A good understanding of various data integration and transformation techniques, like normalization, data cleansing, datavalidation, and data mapping, is necessary to become an ETL developer. DataGovernance Know-how of data security, compliance, and privacy.
While a traditional Data Quality Analyst works to ensure that data supporting all pipelines across a data organization are reliable and accurate, an AI Data Quality Analyst is primarily focused on data that serves AI and GenAI models. Attention to Detail : Critical for identifying data anomalies.
By identifying bottlenecks, inefficiencies, and performance issues, data testing methods enable businesses to optimize their data systems and applications to deliver optimal performance. This results in faster, more efficient dataprocessing, cost savings, and improved user experience.
With this module, you’ll be able to: Leverage capabilities from across our data portfolio – meaning access to solutions you already know and rely on in a SaaS-based design infrastructure. Design in the cloud, deploy anywhere – with an array of deployment options for complex dataprocesses.
Design and maintain pipelines: Bring to life the robust architectures of pipelines with efficient dataprocessing and testing. Collaborate with Management: Management shall collaborate, understanding the objectives while aligning data strategies.
Data products are designed to be accurate and dependable, providing users with trustworthy insights and information. How exactly are Data Products different from Datasets? This scalability ensures that data products can adapt to growing data needs and evolving business requirements without requiring constant redevelopment.
This allows us to create new versions of our data sets, populate them with data, validate our data, and then redeploy our views on top of that data to use the new version of our data. This proactive approach to datavalidation allows you to minimize risks and get ahead of the issue.
By evaluating the current state of your data ecosystem and establishing explicit objectives, you set the stage for a successful automation transition. Additionally, considerations around datagovernance and initial workflow design ensure that when you do move forward, you do so with confidence and direction.
Data lineage can also be used for compliance, auditing, and datagovernance purposes. DataOps Observability Five on data lineage: Data lineage traces data’s origin, history, and movement through various processing, storage, and analysis stages. What is missing in data lineage?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content