This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
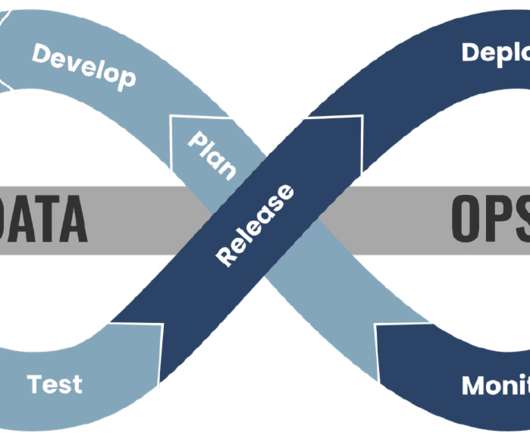
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. How effective are your current dataworkflows?
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. How effective are your current dataworkflows?
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Data lakes are notoriously complex. Data lakes are notoriously complex. Want to see Starburst in action?
A look inside Snowflake Notebooks: A familiar notebook interface, integrated within Snowflake’s secure, scalable platform Keep all your data and development workflows within Snowflake’s security boundary, minimizing the need for data movement. Notebook usage follows the same consumption-based model as Snowflake’s compute engine.
Process Analytics. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, datagovernance, and data security operations. . Reflow — A system for incremental dataprocessing in the cloud.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Accelerated Data Analytics DataOps tools help automate and streamline various dataprocesses, leading to faster and more efficient data analytics.
DataOps practices help organizations establish robust datagovernance policies and procedures, ensuring that data is consistently validated, cleansed, and transformed to meet the needs of various stakeholders. One key aspect of data orchestration is the automation of data pipeline tasks.
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized dataprocessing with their advanced massively parallel processing (MPP) capabilities and SQL support.
It enhances data quality, governance, and optimization, making data retrieval more efficient and enabling powerful automation in data engineering processes. As practitioners using metadata to fuel data teams, we at Ascend understand the critical role it plays in organizing, managing, and optimizing dataworkflows.
Furthermore, Striim also supports real-time data replication and real-time analytics, which are both crucial for your organization to maintain up-to-date insights. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis. Are we using all the data or just a subset?
Evolution of Data Lake Technologies The data lake ecosystem has matured significantly in 2024, particularly in table formats and storage technologies. Despite their "open-source" nature, these catalogs often remain tightly coupled with their respective commercial platforms, challenging the fundamental promise of open table formats.
These experts will need to combine their expertise in dataprocessing, storage, transformation, modeling, visualization, and machine learning algorithms, working together on a unified platform or toolset.
Apache ORC (Optimized Row Columnar) : In 2013, ORC was developed for the Hadoop ecosystem to improve the efficiency of data storage and retrieval. This development was crucial for enabling both batch and streaming dataworkflows in dynamic environments, ensuring consistency and durability in big dataprocessing.
The governance aspect is perhaps even more important and businesses need to be able to understand where the data comes from. Data lineage, personally identifiable information or PPI and metadata all fall under a broad datagovernance banner which is critically important in terms of what needs to be protected and mapped out.
These Azure data engineer projects provide a wonderful opportunity to enhance your data engineering skills, whether you are a beginner, an intermediate-level engineer, or an advanced practitioner. Who is Azure Data Engineer? Azure SQL Database, Azure Data Lake Storage). Azure SQL Database, Azure Data Lake Storage).
Snowflake’s Data Marketplace : Enriches data pipelines with external data sources, providing access to a diverse range of datasets and services that can be seamlessly integrated into your analytics and dataprocessingworkflows. that you can combine to create custom dataworkflows.
Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance. Develop data models, datagovernance policies, and data integration strategies. Experience with Azure services for big dataprocessing and analytics.
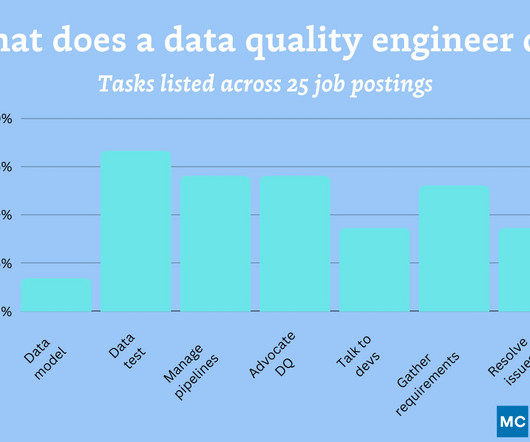
Collaborate with data engineering and development teams to implement data quality best practices and optimize dataworkflows. Document data quality issues, testing procedures, and resolutions for future reference and knowledge sharing. Assist in developing and maintaining datagovernance policies and standards.
Follow Ravit on LinkedIn 5) Priya Krishnan Head of Product Management, Data and AI at IBM Priya is an innovative, customer-focused, data-driven product executive with over 16 years of experience in global product management, strategy, and GTM roles to commercialize and monetize in-demand enterprise solutions.
You can extract data efficiently and once gathered, you can transform this data using built-in or custom transformations, and then load it into your desired destination. And let’s not forget the cherry on top – the ability to reuse code across different Data Factory instances. Now that’s a power couple.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big dataprocessing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
Data Quality and Validation This is one of the trickiest parts of a DataOps strategy and requires a lot of input from those responsible for datagovernance. We recommend identifying sync points that align with your information architecture so that data currency expectations are known at a governance level.
DEW published The State of Data Engineering in 2024: Key Insights and Trends , highlighting the key advancements in the data space in 2024. We witnessed the explosive growth of Generative AI, the maturing of datagovernance practices, and a renewed focus on efficiency and real-time processing.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content