


Using Trino And Iceberg As The Foundation Of Your Data Lakehouse
Data Engineering Podcast
FEBRUARY 18, 2024
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Data lakes are notoriously complex. Data lakes are notoriously complex. Go to dataengineeringpodcast.com/dagster today to get started.












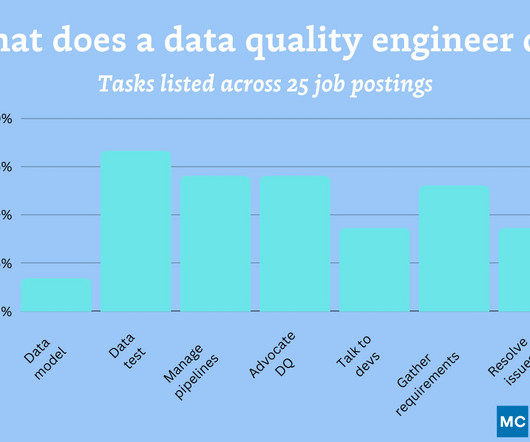
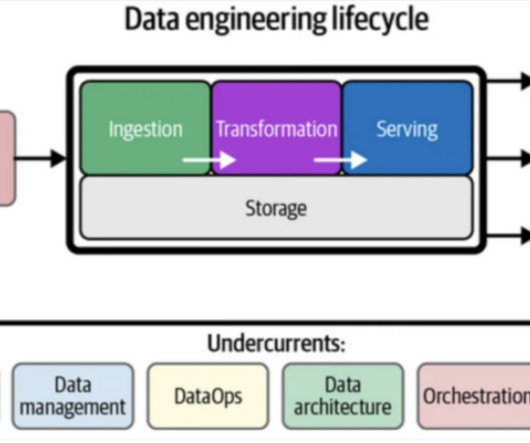
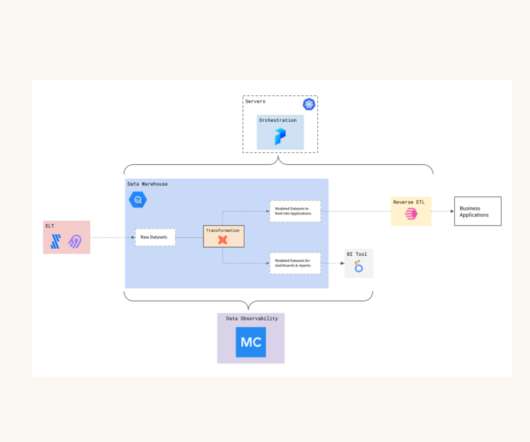








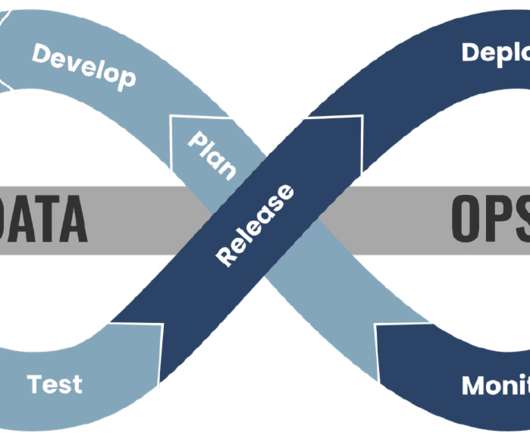







Let's personalize your content