This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
Data lakes are notoriously complex. For data engineers who battle to build and scale high quality dataworkflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data.
Let's delve deeper into the essential responsibilities and skills of a Big Data Developer: Develop and Maintain Data Pipelines using ETL Processes Big Data Developers are responsible for designing and building data pipelines that extract, transform, and load (ETL) data from various sources into the Big Data ecosystem.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, datagovernance, and data security operations. . Airflow — An open-source platform to programmatically author, schedule, and monitor data pipelines.
You can use several datasets in this project covering various healthcare sources such as patient records, medical imaging data, electronic health records (EHRs), and hospital operational data. You will use Python libraries for data processing and transformation.
Their role includes designing data pipelines, integrating data from multiple sources, and setting up databases and data lakes that can support machine learning and analytics workloads. They work with various tools and frameworks, such as Apache Spark, Hadoop , and cloud services, to manage massive amounts of data.
In fact, having a well-rounded understanding of each of these areas can be a valuable asset for data professionals. Datagovernance, orchestration, and monitoring Datagovernance is a crucial component of modern data stacks as it ensures that data is managed appropriately and complies with relevant regulations.
Data Orchestration Data orchestration refers to the coordination and management of dataworkflows, from data ingestion to data processing and analysis. DataOps tools should offer powerful data orchestration capabilities, allowing organizations to build, schedule, and monitor dataworkflows with ease.
The “legacy” table formats The data landscape has evolved so quickly that table formats pioneered within the last 25 years are already achieving “legacy” status. It was designed to support high-volume data exchange and compatibility across different system versions, which is essential for streaming architectures such as Apache Kafka.
Azure Metrics Advisor Automated Data Insights Using Azure Metrics Advisor, create a system that automates the examination of metric data, delivering insights and alerts based on recognized abnormalities or patterns. Learn how to aggregate real-time data using several big data tools like Kafka, Zookeeper, Spark, HBase, and Hadoop.
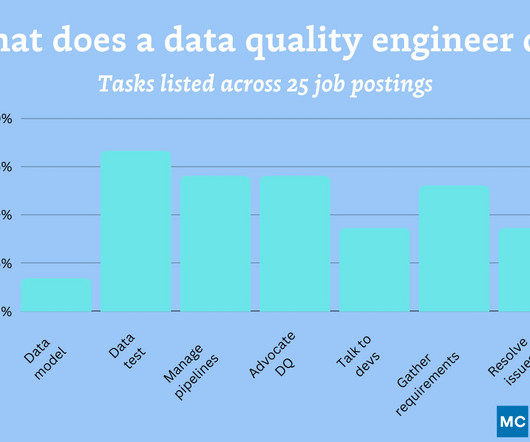
Data quality engineers also need to have experience operating in cloud environments and using many of the modern data stack tools that are utilized in building and maintaining data pipelines. 78% of job postings referenced at least part of their environment was in a modern data warehouse, lake, or lakehouse.
Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance. Develop data models, datagovernance policies, and data integration strategies. Experience with Azure services for big data processing and analytics.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
phData Cloud Foundation is dedicated to machine learning and data analytics, with prebuilt stacks for a range of analytical tools, including AWS EMR, Airflow, AWS Redshift, AWS DMS, Snowflake, Databricks, Cloudera Hadoop, and more. This helps drive requirements and determines the right validation at the right time for the data.
Web Server Log Processing In this project, you'll process web server logs using a combination of Hadoop, Flume, Spark, and Hive on Azure. Starting with setting up an Azure Virtual Machine, you'll install necessary big data tools and configure Flume agents for log data ingestion.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content