How I Optimized Large-Scale Data Ingestion
databricks
SEPTEMBER 6, 2024
Explore being a PM intern at a technical powerhouse like Databricks, learning how to advance data ingestion tools to drive efficiency.
 Data Ingestion Related Topics
Data Ingestion Related Topics 
databricks
SEPTEMBER 6, 2024
Explore being a PM intern at a technical powerhouse like Databricks, learning how to advance data ingestion tools to drive efficiency.

KDnuggets
APRIL 6, 2022
Learn tricks on importing various data formats using Pandas with a few lines of code. We will be learning to import SQL databases, Excel sheets, HTML tables, CSV, and JSON files with examples.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
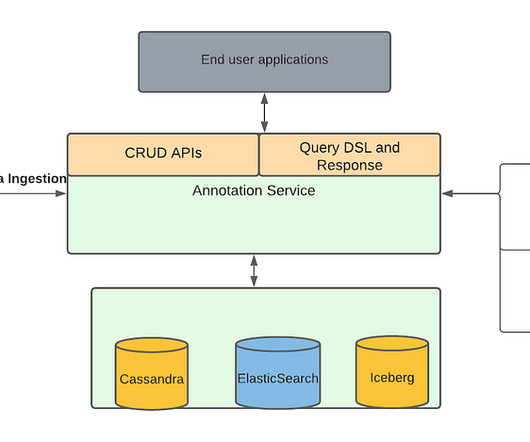
Netflix Tech
MARCH 7, 2023
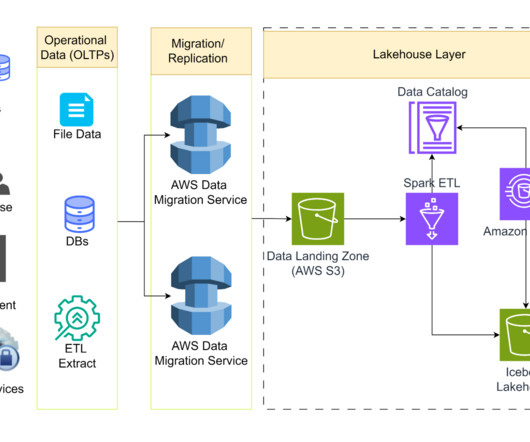
Data ingestion pipeline with Operation Management was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story. For example, they can store the annotations in a blob storage like S3 and give us a link to the file as part of the single API.

Scribd Technology
JANUARY 14, 2025
In a recent session with the Delta Lake project I was able to share the work led Kuntal Basu and a number of other people to dramatically improve the efficiency and reliability of our online data ingestion pipeline. as they take you behind the scenes of Scribds data ingestion setup.
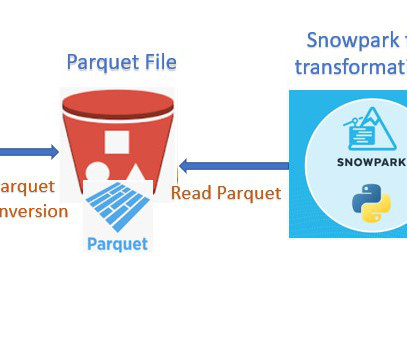
Cloudyard
JUNE 6, 2023
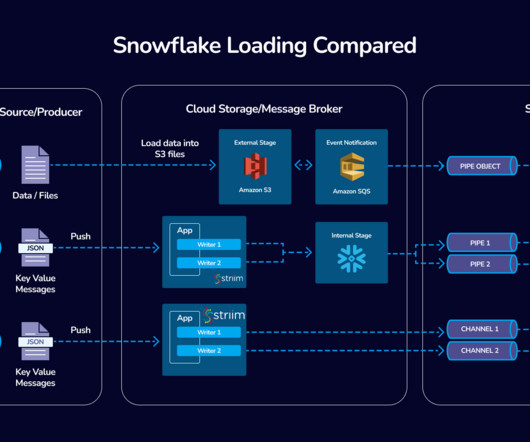
Snowflake Output Happy 0 0 % Sad 0 0 % Excited 0 0 % Sleepy 0 0 % Angry 0 0 % Surprise 0 0 % The post Data Ingestion with Glue and Snowpark appeared first on Cloudyard. Technical Implementation: GLUE Job.

Hevo
FEBRUARY 23, 2025
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (Unstructured Data). Organizations need data ingestion and integration to realize the complete value of their data assets.

Hevo
FEBRUARY 23, 2025
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (Unstructured Data). Organizations need data ingestion and integration to realize the complete value of their data assets.

Expert insights. Personalized for you.
































Let's personalize your content