This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source dataingestion and processing framework designed to simplify data management complexities.
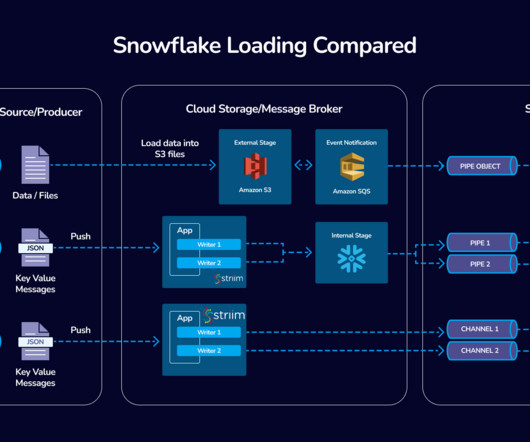
Introduction In the fast-evolving world of dataintegration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Handling Peak Loads : During times of peak data load, it might be beneficial to temporarily adjust the batch policy to handle the increased load more efficiently.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
Conventional batch processing techniques seem incomplete in fulfilling the demand of driving the commercial environment. This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing.
It is important to note that normalization often overlaps with the data cleaning process, as it helps to ensure consistency in data formats, particularly when dealing with different sources or inconsistent units. Data Validation Data validation ensures that the data meets specific criteria before processing.
For your organization’s dataintegration and streaming initiatives to succeed, meeting latency requirements is crucial. Low latency, defined by the rapid transmission of data with minimal delay, is essential for maximizing the effectiveness of your data strategy. Here’s what you need to know.
In today’s fast-paced world, staying ahead of the competition requires making decisions informed by the freshest data available — and quickly. That’s where real-time dataintegration comes into play. What is Real-Time DataIntegration + Why is it Important? Why is Real-Time DataIntegration Important?
On-prem data warehouses can provide lower latency solutions for critical applications that require high performance and low latency. Many companies may choose an on-prem data warehousing solution for quicker dataprocessing to enable business decisions. Dataintegrations and pipelines can also impact latency.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. Snowflake's separate clusters for ETL, reporting and data science eliminated resource contention.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective dataprocessing and analysis.
Streaming and Real-Time DataProcessing As organizations increasingly demand real-time data insights, Open Table Formats offer strong support for streaming dataprocessing, allowing organizations to seamlessly merge real-time and batch data.
Improved data accessibility: By providing self-service data access and analytics, modern data architecture empowers business users and data analysts to analyze and visualize data, enabling faster decision-making and response to regulatory requirements.
Figure 2: Questions answered by precision medicine Snowflake and FAIR in the world of precision medicine and biomedical research Cloud-based big data technologies are not new for large-scale dataprocessing. A conceptual architecture illustrating this is shown in Figure 3.
While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterprises in their IoT initiatives around edge management and edge data collection.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers. Any option can pair well with Apache Kafka.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of dataprocessing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of dataprocessing, computation and storage.
Do ETL and dataintegration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular dataintegration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Each type of tool plays a specific role in the DataOps process, helping organizations manage and optimize their data pipelines more effectively.
The Challenge: High Stakes in the Age of Personalized Data Observability The primary challenge stems from the requirement of Data Consumers for personalized monitoring and alerts based on their unique dataprocessing needs. Data Observability platforms often need to deliver this level of customization.
Similarly , in data, every step of the pipeline, from dataingestion to delivery, plays a pivotal role in delivering impactful results. In this article, we’ll break down the intricacies of an end-to-end data pipeline and highlight its importance in today’s landscape.
Why Striim Stands Out As detailed in the GigaOm Radar Report, Striim’s unified dataintegration and streaming service platform excels due to its distributed, in-memory architecture that extensively utilizes SQL for essential operations such as transforming, filtering, enriching, and aggregating data.
While you can use Snowpipe for straightforward and low-complexity dataingestion into Snowflake, Snowpipe alternatives, like Kafka, Spark, and COPY, provide enhanced capabilities for real-time dataprocessing, scalability, flexibility in data handling, and broader ecosystem integration.
These Azure data engineer projects provide a wonderful opportunity to enhance your data engineering skills, whether you are a beginner, an intermediate-level engineer, or an advanced practitioner. Who is Azure Data Engineer? Azure SQL Database, Azure Data Lake Storage). Azure SQL Database, Azure Data Lake Storage).
At Precisely, we recognize the value and potential of AI to help our customers work faster and smarter, and make more powerful, confident decisions grounded in trusted data – supporting our overall mission of unlocking dataintegrity for organizations of all kinds.
It encompasses data from diverse sources such as social media, sensors, logs, and multimedia content. The key characteristics of big data are commonly described as the three V's: volume (large datasets), velocity (high-speed dataingestion), and variety (data in different formats).
The Essential Six Capabilities To set the stage for impactful and trustworthy data products in your organization, you need to invest in six foundational capabilities. Data pipelines DataintegrityData lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
The data engineering landscape is constantly changing but major trends seem to remain the same. How to Become a Data Engineer As a data engineer, I am tasked to design efficient dataprocesses almost every day. It was created by Spotify to manage massive dataprocessing workloads.
The Five Use Cases in Data Observability: Mastering Data Production (#3) Introduction Managing the production phase of data analytics is a daunting challenge. Overseeing multi-tool, multi-dataset, and multi-hop dataprocesses ensures high-quality outputs. Is the business logic producing correct outcomes?
L1 is usually the raw, unprocessed dataingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes.
The shift towards de-normalization In the realm of database design and management, data normalization and de-normalization are fundamental concepts aimed at optimizing data structures for efficient storage, retrieval, and manipulation. Load data For dataingestion Google Cloud Storage is a pragmatic way to solve the task.
Data Collection and Integration: Data is gathered from various sources, including sensor and IoT data, transportation management systems, transactional systems, and external data sources such as economic indicators or traffic data. That’s where Striim came into play.
Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively. Dataprocessing: Data engineers should know dataprocessing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
Today, we’ll break down the key benefits, best practices, and implementation strategies to enhance your data workflows with Dataops. DataOps, short for Data Operations, is an emerging discipline that combines data engineering, dataintegration, and data quality with agile methodologies and DevOps practices.
Real-Time DataProcessing Businesses are adopting technologies that can process and analyze data instantly due to the need for real-time insights. Real-time data preparation tools allow companies to react quickly to new information, maintaining a competitive edge in fast-paced industries.
Case Study: Accenture’s Experience on Legacy Data Warehouse Migration into Cloudera with a Health Insurance Company . Due to the high storage cost in the legacy EDW solution, 100% source data capture proved cost-prohibitive – this led to continuing and costly change cycles to load incremental source updates as business requirements changed.
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining data pipelines, data storage solutions, dataprocessing, and dataintegration to enable data-driven decision-making inside a company.
Databricks architecture Databricks provides an ecosystem of tools and services covering the entire analytics process — from dataingestion to training and deploying machine learning models. Besides that, it’s fully compatible with various dataingestion and ETL tools. Databricks two-plane infrastructure.
An Azure Data Engineer is responsible for designing, implementing, and maintaining data management and dataprocessing systems on the Microsoft Azure cloud platform. They work with large and complex data sets and are responsible for ensuring that data is stored, processed, and secured efficiently and effectively.
Data Teams and Their Types of Data Journeys In the rapidly evolving landscape of data management and analytics, data teams face various challenges ranging from dataingestion to end-to-end observability. It explores why DataKitchen’s ‘Data Journeys’ capability can solve these challenges.
While legacy ETL has a slow transformation step, modern ETL platforms, like Striim, have evolved to replace disk-based processing with in-memory processing. This advancement allows for real-time data transformation , enrichment, and analysis, providing faster and more efficient dataprocessing.
Big Data vs Small Data: Volume Big Data refers to large volumes of data, typically in the order of terabytes or petabytes. It involves processing and analyzing massive datasets that cannot be managed with traditional dataprocessing techniques. Small Data is collected and processed at a slower pace.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content