This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What if your datalake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data. Vinoth also stressed the need for solutions that ensure longevity and adaptability.
Data stewards can also set up Request for Access (private preview) by setting a new visibility property on objects along with contact details so the right person can easily be reached to grant access. Simplify bronze and silver pipelines for Apache Iceberg We are making it even easier to use Iceberg tables with Snowflake at every stage.
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. RudderStack helps you build a customer data platform on your warehouse or datalake. runs natively on datalakes and warehouses and in AWS, Google Cloud and Microsoft Azure.
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
A datalake is essentially a vast digital dumping ground where companies toss all their raw data, structured or not. A modern data stack can be built on top of this data storage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Imagine being in charge of creating an intelligent data universe where collaboration, analytics, and artificial intelligence all work together harmoniously. Programming Languages: Hands-on experience with SQL, Kusto Query Language (KQL), and Data Analysis Expressions ( DAX ). That’s what a Microsoft Fabric Engineer does.
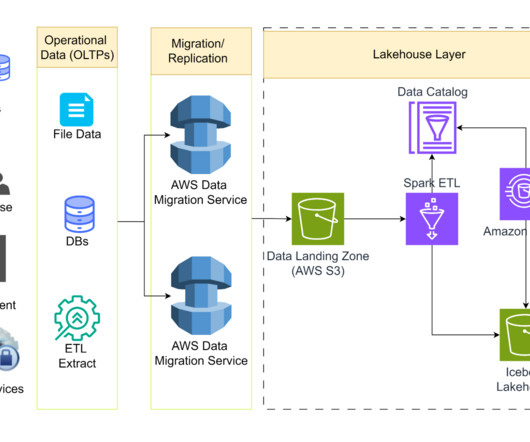
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a datalake. Data scientists also benefited from a scalable environment to build machine learning models without fear of system crashes.
Every data-centric organization uses a datalake, warehouse, or both data architectures to meet its data needs. DataLakes bring flexibility and accessibility, whereas warehouses bring structure and performance to the data architecture.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
Learn how we build datalake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Learn More → Notion: Building and scaling Notion’s datalake Notion writes about scaling the datalake by bringing critical dataingestion operations in-house. Hudi seems to be a de facto choice for CDC datalake features.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
In this blog, we’ll compare and contrast how Elasticsearch and Rockset handle dataingestion as well as provide practical techniques for using these systems for real-time analytics. That’s because Elasticsearch can only write data to one index.
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as dataingestion and processing from different sources, using SQL or Python. Use VDK to build a datalake and merge multiple sources.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the datalake. As a result, monitoring data in real time was often an afterthought.
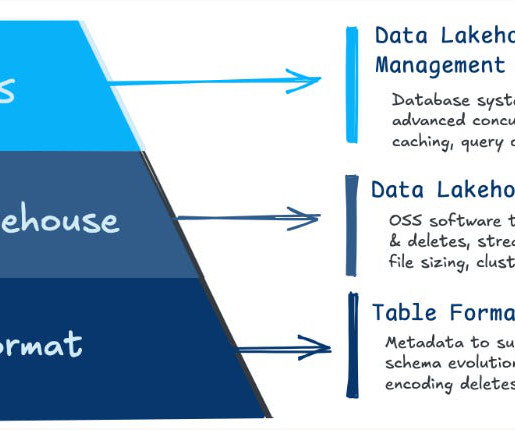
In this piece, we break down popular Iceberg use cases, advantages and disadvantages, and its impact on data quality so you can make the table format decision that’s right for your team. Is your datalake a good fit for Iceberg? Let’s dive in.
Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructured data, most enterprises manage and deliver data to the datalake and leverage various applications like ETL tools, search engines, and databases for analysis.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. In fact, while only 3.5% That’s where our friends at Ascend.io
Modak’s Nabu is a born in the cloud, cloud-neutral integrated data engineering platform designed to accelerate the journey of enterprises to the cloud. The platform converges data cataloging, dataingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata.
This includes pipelines and transformations with Snowpark, Streams, Tasks and Dynamic Tables (public preview soon); extending AI and ML to Iceberg with Snowflake Cortex AI; performing storage maintenance with capabilities like automatic clustering and compaction; as well as securely collaborating on live data shares.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. In fact, while only 3.5%
Summary The "data lakehouse" architecture balances the scalability and flexibility of datalakes with the ease of use and transaction support of data warehouses. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. In fact, while only 3.5% That’s where our friends at Ascend.io
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission-critical, large-scale data analytics and AI use cases—including enterprise data warehouses.
Apache Ozone is one of the major innovations introduced in CDP, which provides the next generation storage architecture for Big Data applications, where data blocks are organized in storage containers for larger scale and to handle small objects. Apache Ozone brings the best of both HDFS and Object Store: Overcomes HDFS limitations.
Unbound by the limitations of a legacy on-premises solution, its multi-cluster shared data architecture separates compute from storage, allowing data teams to easily scale up and down based on their needs. Now, the team is on an ongoing mission to use Snowflake’s data platform to simplify the complexity of its tech stack.
With Snowflake, organizations get the simplicity of data management with the power of scaled-out data and distributed processing. Although Snowflake is great at querying massive amounts of data, the database still needs to ingest this data. Dataingestion must be performant to handle large amounts of data.
Then, the company used Cloudera’s Data Platform as a foundation to build its own Network Real-time Analytics Platform (NRAP) and created the proper infrastructure to collect and analyze large-scale big data in real-time. . For this, the RTA transformed its dataingestion and management processes. .
The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory. In this category I recommend also to have a look at dataingestion (Airbyte, Fivetran, etc.), workflows (Airflow, Prefect, Dagster, etc.)
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. In fact, while only 3.5%
DataIngestion. The raw data is in a series of CSV files. We will firstly convert this to parquet format as most datalakes exist as object stores full of parquet files. RAPIDS is only supported on Pascal or newer NVIDIA GPUs. For AWS this means at least P3 instances. P2 GPU instances are not supported.
Dataingestion pipeline with Operation Management — At Netflix they annotate video which can lead to thousand of annotation but they need to manage the annotation lifecycle each time the annotation algorithm runs. Some company also call it a lakehouse or a datalake, but the word shift is enough interesting to notice.
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. In fact, while only 3.5%
Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed datalakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. Data Preparation (Apache Spark and Apache Hive) .
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. In fact, while only 3.5%
All of these happen continuously and repetitively on a daily basis, amounting to petabytes worth of information and data. This requires massive amounts of dataingestion, messaging, and processing within a data-in-motion context. From a dataingestion standpoint, NiFi is designed for this purpose.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content