This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The most complicated part of data engineering is the effort involved in making the raw data fit into the narrative of the business. Master DataManagement (MDM) is the process of building consensus around what the information actually means in the context of the business and then shaping the data to match those semantics.
At Isima they decided to reimagine the entire ecosystem from the ground up and built a single unified platform to allow end-to-end self service workflows from dataingestion through to analysis. What was your motivation for creating a new platform for data applications? What is the story behind the name?
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Together, we discussed how Hudi drives innovation, the state of open standards, and what lies ahead for data lakehouses in 2025 and beyond. This foundational concept addresses a key challenge for enterprises: building scalable, high-performing data platforms that can support the complexity of modern data ecosystems.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern datamanagement workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. Project Idea : Build a data pipeline to ingestdata from APIs like CoinGecko or Kaggle’s crypto datasets.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
While the Iceberg itself simplifies some aspects of datamanagement, the surrounding ecosystem introduces new challenges: Small File Problem (Revisited): Like Hadoop, Iceberg can suffer from small file problems. Dataingestion tools often create numerous small files, which can degrade performance during query execution.
In this episode CEO and founder Salma Bakouk shares her views on the causes and impacts of "data entropy" and how you can tame it before it leads to failures. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. In fact, while only 3.5%
Here’s the breakdown of the core layers - DataIngestion: The ingestion layer handles transferring data from various sources into the data lake. It supports batch processing for large amounts of data and real-time streaming for continuous data. into Azure Data Lake Storage.
Sherloq Datamanagement is critical when building internal gen AI applications, but it remains a challenge for most companies: Creating a verified source of truth and keeping it up to date with the latest documentation is a highly manual, high-effort task.
It ensures swift and intuitive access to all data within Fabric, empowering business owners to make informed decisions based on data insights. Microsoft Fabric Architecture Microsoft Fabric architecture is a comprehensive framework designed to empower organizations with advanced datamanagement and analytics capabilities.
This same principle holds true in datamanagement. You require a comprehensive solution that addresses every facet, from ingestion and transformation to orchestration and reverse ETL. Defense: Saving Money with Intelligent Data Refresh In football, a solid defense does more than just stop goals.
With Snowflake, organizations get the simplicity of datamanagement with the power of scaled-out data and distributed processing. Although Snowflake is great at querying massive amounts of data, the database still needs to ingest this data. Dataingestion must be performant to handle large amounts of data.
A data warehouse acts as a single source of truth for an organization’s data, providing a unified view of its operations and enabling data-driven decision-making. A data warehouse enables advanced analytics, reporting, and business intelligence. Data integrations and pipelines can also impact latency.
In this episode she shares the story behind the project, the details of how it is implemented, and how you can use it for your own data projects. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. In fact, while only 3.5% That’s where our friends at Ascend.io
With Hybrid Tables’ fast, high-concurrency point operations, you can store application and workflow state directly in Snowflake, serve data without reverse ETL and build lightweight transactional apps while maintaining a single governance and security model for both transactional and analytical data — all on one platform.
In this episode he explains how investing in high performance and operationally simplified streaming with a familiar API can yield significant benefits for software and data teams together. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles.
In this episode Rod Christensen shares the story behind Aparavi and how you can use it to cut costs and gain value for the long tail of your unstructured data. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. In fact, while only 3.5% In fact, while only 3.5%
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity.
Adding more wires and throwing more compute hardware to the problem is simply not viable considering the cost and complexities of today’s connected cars or the additional demands designed into electric cars (like battery management systems and eco-trip planning).
Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Delayed dataingestion : Batch processing delays insights, making real-time decision-making impossible. If data is delayed, outdated, or missing key details, leaders may act on the wrong assumptions.
This article gives information about Snowflake master datamanagement, which you can use to enhance your business revenue. What is Master DataManagement? Master datamanagement (MDM) uses various tools and techniques to organize and structure master data in a standardized format.
When we started Rockset, we envisioned building a powerful cloud datamanagement system that was really easy to use. Making the data stack simpler is fundamental to making data usable by developers and data scientists. The datamanagement should feel limitless.
These businesses need data engineers who can use technologies for handling data quickly and effectively since they have to manage potentially profitable real-time data. These platforms facilitate effective datamanagement and other crucial Data Engineering activities. PREVIOUS NEXT <
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
The significant roadblocks leading to data warehousing project failures include disconnected data silos, delayed data warehouse loading, time-consuming data preparation processes, a need for additional automation of core datamanagement tasks, inadequate communication between Business Units and Tech Team, etc.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are datamanagement and storage solutions designed to meet different needs in data analytics, integration, and processing. See it in action and schedule a demo with one of our data experts today.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are datamanagement and storage solutions designed to meet different needs in data analytics, integration, and processing. See it in action and schedule a demo with one of our data experts today.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are datamanagement and storage solutions designed to meet different needs in data analytics, integration, and processing.
Using a scalable datamanagement and analytics platform built on Cloudera Enterprise, Sikorsky can process and store data in a reliable way, and analyze full data sets across entire fleets. images, video, text, spectral data) or other input such as thermographic or acoustic signals. .
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
Let's consider an example of a data processing pipeline that involves ingestingdata from various sources, cleaning it, and then performing analysis. The workflow can be broken down into individual tasks such as dataingestion, data cleaning, data transformation, and data analysis.
Data Governance DataManagementData Lineage Fabric allows users to track the origin and transformation path of any data asset by automatically tracking data movement across pipelines, transformations, and reports.
In this episode he shares his journey from building a consumer product to launching a data pipeline service and how his frustrations as a product owner have informed his work at Hevo Data. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months.
Data engineering tools are specialized applications that make building data pipelines and designing algorithms easier and more efficient. These tools are responsible for making the day-to-day tasks of a data engineer easier in various ways. It's one of the fastest platforms for datamanagement and stream processing.
This guide is your go-to resource for understanding the NiFi's role in Big Data projects. We'll also walk you through NiFi's architecture and user-friendly features, helping you understand its role in simplifying datamanagement. What is NiFi used for? PREVIOUS NEXT <
Imagine being able to seamlessly handle and analyze massive datasets in a cloud-native environment, making data engineering tasks smoother. That's exactly what Snowflake Data Warehouse enables you to do! Mastering Snowflake DataWarehouse can significantly enhance your datamanagement and analytics skills.
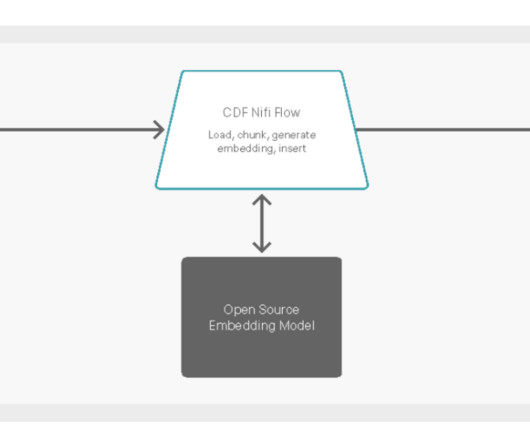
The connector makes it easy to update the LLM context by loading, chunking, generating embeddings, and inserting them into the Pinecone database as soon as new data is available. High-level overview of real-time dataingest with Cloudera DataFlow to Pinecone vector database.
For many agencies, 80 percent of the work in support of anomaly detection and fraud prevention goes into routine tasks around datamanagement. Inordinate time and effort are devoted to cleaning and preparing data, resulting in data bottlenecks that impede effective use of anomaly detection tools.
This article will explore the top seven data warehousing tools that simplify the complexities of data storage, making it more efficient and accessible. So, read on to discover these essential tools for your datamanagement needs. Table of Contents What are Data Warehousing Tools? Why Choose a Data Warehousing Tool?
In this episode Joe Reis, founder of Ternary Data and co-author of "Fundamentals of Data Engineering", turns the tables and interviews the host, Tobias Macey, about his journey into podcasting, how he runs the show behind the scenes, and the other things that occupy his time. In fact, while only 3.5% Links Podcast.__init__
In this episode Shruti Bhat gives her view on the state of the ecosystem for real-time data and the work that she and her team at Rockset is doing to make it easier for engineers to build those experiences. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content