This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We are excited to announce the availability of datapipelines replication, which is now in public preview. In the event of an outage, this powerful new capability lets you easily replicate and failover your entire dataingestion and transformations pipelines in Snowflake with minimal downtime.
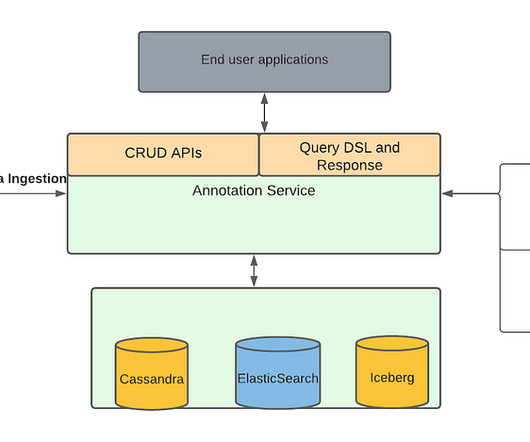
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. Similarly, client teams don’t have to worry about when or how the data is written. in a video file.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. With careful consideration and learning about your market, the choices you need to make become narrower and more clear.
For more than a decade, Cloudera has been an ardent supporter and committee member of Apache NiFi, long recognizing its power and versatility for dataingestion, transformation, and delivery. Now, the era of generative AI (GenAI) demands datapipelines that are not just powerful, but also agile and adaptable.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
Building reliable datapipelines is a complex and costly undertaking with many layered requirements. In order to reduce the amount of time and effort required to build pipelines that power critical insights Manish Jethani co-founded Hevo Data. Data stacks are becoming more and more complex. In fact, while only 3.5%
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable datapipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems.
Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 1): Data Collection – dataingestion and monitoring at the edge (whether the edge be industrial sensors or people in a vehicle showroom).
Rather than collecting every single event and analyzing later, it would make sense to identify the important data as it is being collected. Let’s transform the first mile of the datapipeline. By modernizing the data flow, the enterprise got better insights into the business. What product can help collect events only?
Snowflake’s new Python API (GA soon) simplifies datapipelines and is readily available through pip install snowflake. Additionally, Dynamic Tables are a new table type that you can use at every stage of your processing pipeline. Interact with Snowflake objects directly in Python. Automate or code, the choice is yours.
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
When data reaches the Gold layer, it is highly curated and structured, offering a single version of the truth for decision-makers across the organization. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Datapipeline to OneLake and Microsoft Fabric.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
Managing vast data volumes is a necessity for organizations in the current data-driven economy. To accommodate lengthy processes on such data, companies turn toward DataPipelines which tend to automate the work of extracting data, transforming it and storing it in the desired location.
Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Delayed dataingestion : Batch processing delays insights, making real-time decision-making impossible. Enabling AI & ML with Adaptive DataPipelines AI models require ongoing updates to stay relevant.
Introduction Azure data factory (ADF) is a cloud-based dataingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
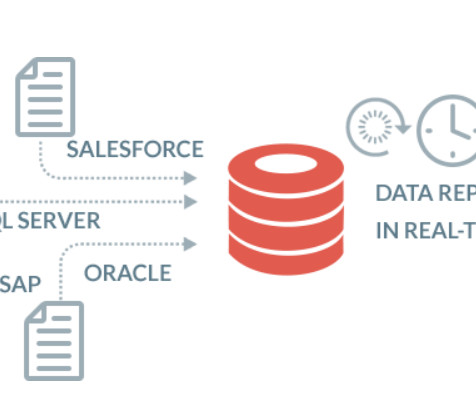
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Visualize data through charts and graphs and compile reports for stakeholders. A typical dataingestion flow.
SoFlo Solar SoFlo Solars SolarSync platform uses real-time AI data analytics and ML to transform underperforming residential solar systems into high-uptime clean energy assets, providing homeowners with savings while creating a virtual power plant network that delivers measurable value to utilities and grid operators.
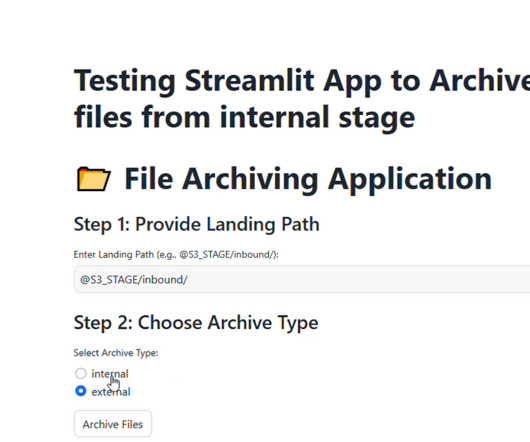
Read Time: 2 Minute, 38 Second In data-driven organizations, File Archival in Snowflake: A Snowpark-Powered Solutionhas become a game-changer. Handling feed files in datapipelines is a critical task for many organizations.
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
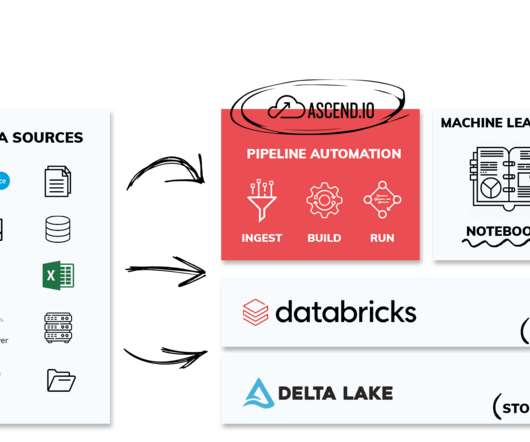
We hope the real-time demonstrations of Ascend automating datapipelines were a real treat—a long with the special edition T-Shirt designed specifically for the show (picture of our founder and CEO rocking the t-shirt below). Thank you to the hundreds of AWS re:Invent attendees who stopped by our booth!
Systems must be capable of handling high-velocity data without bottlenecks. Addressing these challenges demands an end-to-end approach that integrates dataingestion, streaming analytics, AI governance, and security in a cohesive pipeline. As you can see, theres a lot to consider in adopting real-time AI.
Dataingestion When we think about the flow of data in a pipeline, dataingestion is where the data first enters our platform. Dataingestion When we think about the flow of data in a pipeline, dataingestion is where the data first enters our platform.
A well-executed datapipeline can make or break your company’s ability to leverage real-time insights and stay competitive. Thriving in today’s world requires building modern datapipelines that make moving data and extracting valuable insights quick and simple. What is a DataPipeline?
[link] Alibaba: Xiaomi's Real-Time Lakehouse Implementation - Best Practices with Apache Paimon As Iceberg is getting growing adoption, I also noticed some of its weaknesses popping up around the real-time dataingestion, upsert operations, and incremental data processing.
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a datapipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
Programming Languages: Hands-on experience with SQL, Kusto Query Language (KQL), and Data Analysis Expressions ( DAX ). DataIngestion and Management: Good practices for dataingestion and management within the Fabric environment.
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. DataIngestionDataingestion is the first step of both ETL and datapipelines.
A star-studded baseball team is analogous to an optimized “end-to-end datapipeline” — both require strategy, precision, and skill to achieve success. Just as every play and position in baseball is key to a win, each component of a datapipeline is integral to effective data management.
The costs of developing and running datapipelines are coming under increasing scrutiny because the bills for infrastructure and data engineering talent are piling up. For data teams, it is time to ask: “How can we have an impact on these runaway costs and still deliver unprecedented business value?”
These engineering functions are almost exclusively concerned with datapipelines, spanning ingestion, transformation, orchestration, and observation — all the way to data product delivery to the business tools and downstream applications. Pipelines need to grow faster than the cost to run them.
These engineering functions are almost exclusively concerned with datapipelines, spanning ingestion, transformation, orchestration, and observation — all the way to data product delivery to the business tools and downstream applications. Pipelines need to grow faster than the cost to run them.
A fundamental requirement for any data-driven organization is to have a streamlined data delivery mechanism. With organizations collecting data at a rate like never before, devising datapipelines for adequate flow of information for analytics and Machine Learning tasks becomes crucial for businesses.
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. And don’t forget to thank them for their continued support of this show!
Datapipelines are integral to business operations, regardless of whether they are meticulously built in-house or assembled using various tools. As companies become more data-driven, the scope and complexity of datapipelines inevitably expand. Ready to fortify your data management practice?
Data cloud integration: This comprehensive solution begins with the Snowflake Data Cloud as a persistent data layer, which makes data more accessible for organizations to get started with the platform. Dataingestion: Hakkoda leads the entire dataingestion process.
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
Datapipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a DataPipeline? The Importance of a DataPipeline What is an ETL DataPipeline?
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for datapipelines. link] Grab: Improving Hugo's stability and addressing oncall challenges through automation.
Faster, easier AI/ML and data engineering workflows Explore, analyze and visualize data using Python and SQL. Discover valuable business insights through exploratory data analysis. Develop scalable datapipelines and transformations for data engineering.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content