This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
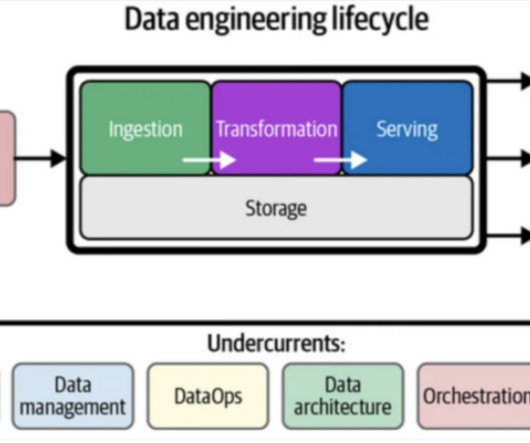
For more than a decade, Cloudera has been an ardent supporter and committee member of Apache NiFi, long recognizing its power and versatility for dataingestion, transformation, and delivery. Now, the era of generative AI (GenAI) demands datapipelines that are not just powerful, but also agile and adaptable.
Leveraging TensorFlow Transform for scaling datapipelines for production environments Photo by Suzanne D. Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. ML Pipeline operations begins with dataingestion and validation, followed by transformation.
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
One of our customers, Commerzbank, has used the CDP Public Cloud trial to prove that they can combine both Google Cloud and CDP to accelerate their migration to Google Cloud without compromising data security or governance. . DataPreparation (Apache Spark and Apache Hive) .
In this episode founder Shayan Mohanty explains how he and his team are bringing software best practices and automation to the world of machine learning datapreparation and how it allows data engineers to be involved in the process. Data stacks are becoming more and more complex. In fact, while only 3.5%
Adaptive , meaning models should have a proper datapipeline for regular dataingestion, validation, and deployment to timely adjust to changes. The typical machine learning scenario data scientists leverage to bring propensity modeling to life involves the following steps: Mapping out a strategy.
Picture this: your data is scattered. Datapipelines originate in multiple places and terminate in various silos across your organization. Your data is inconsistent, ungoverned, inaccessible, and difficult to use. Some of the value companies can generate from data orchestration tools include: Faster time-to-insights.
Data Sourcing: Building pipelines to source data from different company data warehouses is fundamental to the responsibilities of a data engineer. So, work on projects that guide you on how to build end-to-end ETL/ELT datapipelines. Google BigQuery receives the structured data from workers.
Azure Data Engineers use a variety of Azure data services, such as Azure Synapse Analytics, Azure Data Factory, Azure Stream Analytics, and Azure Databricks, to design and implement data solutions that meet the needs of their organization. Gain hands-on experience using Azure data services.
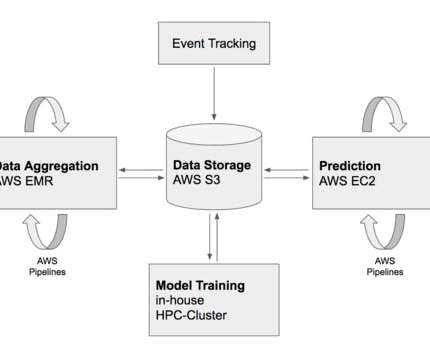
Moving deep-learning machinery into production requires regular data-aggregation-, model-training- and prediction-tasks. DataPreparation Before any machine learning is applied, data has to be gathered and organized to fit the input format of the machine learning model.
Databricks architecture Databricks provides an ecosystem of tools and services covering the entire analytics process — from dataingestion to training and deploying machine learning models. Besides that, it’s fully compatible with various dataingestion and ETL tools. Let’s see what exactly Databricks has to offer.
Data engineering is a field that requires a range of technical skills, including database management, data modeling, and programming. Data engineering tools can help automate many of these processes, allowing data engineers to focus on higher-level tasks like extracting insights and building datapipelines.
Due to the enormous amount of data being generated and used in recent years, there is a high demand for data professionals, such as data engineers, who can perform tasks such as data management, data analysis, datapreparation, etc. This exam can be taken only in the English language.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many data storage, computation, and analytics technologies to develop scalable and robust datapipelines.
Born out of the minds behind Apache Spark, an open-source distributed computing framework, Databricks is designed to simplify and accelerate data processing, data engineering, machine learning, and collaborative analytics tasks. This flexibility allows organizations to ingestdata from virtually anywhere.
It eliminates the cost and complexity around datapreparation, performance tuning and operations, helping to accelerate the movement from batch to real-time analytics. The latest Rockset release, SQL-based rollups, has made real-time analytics on streaming data a lot more affordable and accessible.
Data must be consumed from many sources, translated and stored, and then processed before being presented understandably. However, the benefits might be game-changing: a well-designed big datapipeline can significantly differentiate a company. Preparingdata for analysis is known as extract, transform and load (ETL).
Big Data analytics encompasses the processes of collecting, processing, filtering/cleansing, and analyzing extensive datasets so that organizations can use them to develop, grow, and produce better products. Big Data analytics processes and tools. Dataingestion. Let’s take a closer look at these procedures. Apache Kafka.
There are three steps involved in the deployment of a big data model: DataIngestion: This is the first step in deploying a big data model - Dataingestion, i.e., extracting data from multiple data sources. Explain the datapreparation process. Steps for Datapreparation.
To execute pipelines, beam supports numerous distributed processing back-ends, including Apache Flink, Apache Spark , Apache Samza, Hazelcast Jet, Google Cloud Dataflow, etc. In addition to analytics and data science, RAPIDS focuses on everyday datapreparation tasks.
In Big Data systems, data can be left in its raw form and subsequently filtered and structured as needed for specific analytical needs. In other circumstances, it is preprocessed using data mining methods and datapreparation software to prepare it for ordinary applications. .
Pentaho published a whitepaper titled “Hadoop and the Analytic DataPipeline” that highlights the key categories which need to be focused on - Big DataIngestion, Transformation, Analytics, Solutions.
There are open data platforms in several regions (like data.gov in the U.S.). These open data sets are a fantastic resource if you're working on a personal project for fun. DataPreparation and Cleaning The datapreparation step, which may consume up to 80% of the time allocated to any big data or data engineering project, comes next.
AutoML is essentially a set of automated pipelines, that when triggered, simply try out all the permutations and combinations until they come up with the top results. Having multiple data integration routes helps optimize the operational as well as analytical use of data. Data: Data Engineering PipelinesData is everything.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content