This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. DataStorage : Store validated data in a structured format, facilitating easy access for analysis. A typical dataingestion flow.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
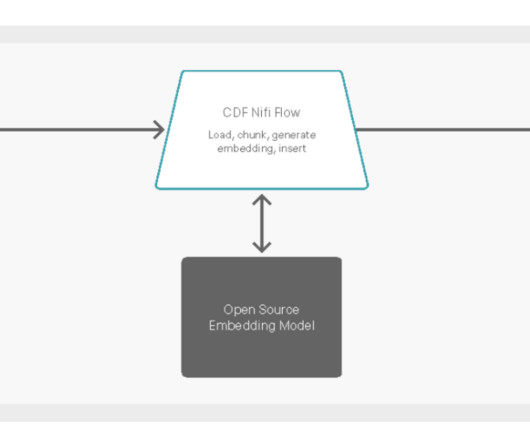
This AMP is built on the foundation of one of our previous AMP s, with the additional enhancement of enabling customers to create a knowledge base from data on their own website using Cloudera DataFlow (CDF) and then augment questions to the chatbot from that same knowledge base in Pinecone.
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
Then here a list of global resources that can help you navigate through the field: The Data Engineer Roadmap — An image with advices and technology names to watch. Reddit r/dataengineering wiki a place where some data eng definitions are written. formats — This is a huge part of data engineering.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like datapipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows. As a result, they can be slow, inefficient, and prone to errors.
From exploratory data analysis (EDA) and data cleansing to data modeling and visualization, the greatest data engineering projects demonstrate the whole data process from start to finish. Datapipeline best practices should be shown in these initiatives.
Azure Data Engineers use a variety of Azure data services, such as Azure Synapse Analytics, Azure Data Factory, Azure Stream Analytics, and Azure Databricks, to design and implement data solutions that meet the needs of their organization. Gain hands-on experience using Azure data services.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable datapipelines, datastorage solutions, and data processing systems.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. The data objects are accessible only through SQL query operations run using Snowflake.
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining datapipelines, datastorage solutions, data processing, and data integration to enable data-driven decision-making inside a company.
An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining data processing systems and solutions on the Microsoft Azure cloud platform. A Data Engineer is responsible for designing the entire architecture of the data flow while taking the needs of the business into account.
To get a better understanding of their responsibilities, we analyzed 41 job postings on LinkedIn and found these key duties: Designing and Implementing DataPipelines: The primary responsibility in 90% of the job postings is creating and managing datapipelines.
To get a better understanding of their responsibilities, we analyzed 41 job postings on LinkedIn and found these key duties: Designing and Implementing DataPipelines: The primary responsibility in 90% of the job postings is creating and managing datapipelines.
Efficient Scheduling and Runtime Increased Adaptability and Scope Faster Analysis and Real-Time Prediction Introduction to the Machine Learning Pipeline Architecture How to Build an End-to-End a Machine Learning Pipeline? Is python suitable for machine learning pipeline design patterns?
A data lake is essentially a vast digital dumping ground where companies toss all their raw data, structured or not. A modern data stack can be built on top of this datastorage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Data engineering is a field that requires a range of technical skills, including database management, data modeling, and programming. Data engineering tools can help automate many of these processes, allowing data engineers to focus on higher-level tasks like extracting insights and building datapipelines.
We’ll cover: What is a data platform? Below, we share what the “basic” data platform looks like and list some hot tools in each space (you’re likely using several of them): The modern data platform is composed of five critical foundation layers. DataStorage and Processing The first layer?
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
An Azure Data Engineer is a professional specializing in designing, implementing, and managing data solutions on the Microsoft Azure cloud platform. They possess expertise in various aspects of data engineering. As an Azure data engineer myself, I was responsible for managing datastorage, processing, and analytics.
An Azure Data Engineer is a professional specializing in designing, implementing, and managing data solutions on the Microsoft Azure cloud platform. They possess expertise in various aspects of data engineering. As an Azure data engineer myself, I was responsible for managing datastorage, processing, and analytics.
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations. Key Features of Databricks 1.
Additionally, for a job in data engineering, candidates should have actual experience with distributed systems, datapipelines, and related database concepts. Let’s understand in detail: Great demand: Azure is one of the most extensively used cloud platforms, and as a result, Azure Data Engineers are in great demand.
Data Engineering Data engineering is a process by which data engineers make data useful. Data engineers design, build, and maintain datapipelines that transform data from a raw state to a useful one, ready for analysis or data science modeling.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. The schematization of data plays a vital role in a data platform.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust datapipelines.
Datastorage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloud storage systems. Amazon S3 for AWS, Azure Blob Storage for Azure, or Google Cloud Storage for GCP) to store the actual data files in micro-partitions.
Batch jobs are often scheduled to load data into the warehouse, while real-time data processing can be achieved using solutions like Apache Kafka and Snowpipe by Snowflake to stream data directly into the cloud warehouse. But this distinction has been blurred with the era of cloud data warehouses.
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including data collection and ingestion, data analytics, datastorage, data warehousing, data processing, and data visualization.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Dataingestion.
Azure Data Engineer Azure Data Engineers are experts in the design and implementation of data solutions on Azure. Using Azure services, they create, manage, and optimize datapipelines, databases, and data warehouses. Experience in data modeling, dataingestion, and data transformation.
To execute pipelines, beam supports numerous distributed processing back-ends, including Apache Flink, Apache Spark , Apache Samza, Hazelcast Jet, Google Cloud Dataflow, etc. It was built from the ground up for interactive analytics and can scale to the size of Facebook while approaching the speed of commercial data warehouses.
Elasticsearch is one tool to which reads can be offloaded, and, because both MongoDB and Elasticsearch are NoSQL in nature and offer similar document structure and data types, Elasticsearch can be a popular choice for this purpose. This blog post will examine the various tools that can be used to sync data between MongoDB and Elasticsearch.
DataIngestion Snowpipe auto-ingest expands to support cross-cloud and cross-platform ingestion – public preview With this release, we are making a few enhancements to Snowpipe auto-ingest to make ingestion easier with Snowflake. Visit our documentation page to learn more.
Data must be consumed from many sources, translated and stored, and then processed before being presented understandably. However, the benefits might be game-changing: a well-designed big datapipeline can significantly differentiate a company. Dataingestion can be divided into two categories: .
For query processing, BigQuery charges $5 per TB of data processed by each query, with the first TB of data per month free. For storage, BigQuery offers up to 10GB of free datastorage per month and $0.02 per additional GB of active storage, making it very economical for storing large amounts of historical data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content