This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
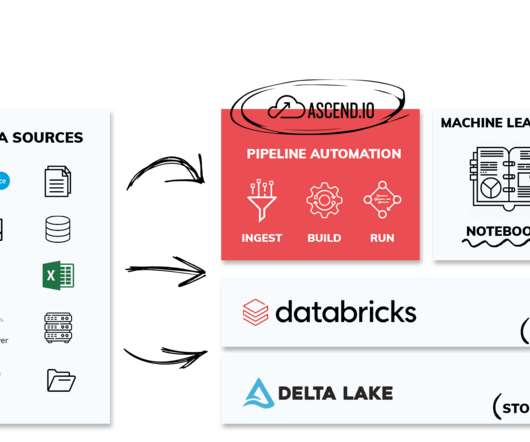
Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 1): Data Collection – dataingestion and monitoring at the edge (whether the edge be industrial sensors or people in a vehicle showroom).
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Data stacks are becoming more and more complex. This brings infinite possibilities for datapipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Data stacks are becoming more and more complex. In fact, while only 3.5% In fact, while only 3.5%
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. What is the workflow for someone getting Sifflet integrated into their data stack?
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for datapipelines. link] Grab: Improving Hugo's stability and addressing oncall challenges through automation.
We hope the real-time demonstrations of Ascend automating datapipelines were a real treat—a long with the special edition T-Shirt designed specifically for the show (picture of our founder and CEO rocking the t-shirt below). Instead, it is a Sankey diagram driven by the same dynamic metadata that runs the Ascend control plane.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. For example, we have a service that stores a movie entity’s metadata or a service that stores metadata about images. In this case it is BOUNDING_BOX.
We all know that data freshness plays a critical role in the performance of Lakehouse. If we can place the metadata, indexing, and recent data files in Express One, we can potentially build a Snowflake-style performant architecture in Lakehouse. Apache Hudi, for example, introduces an indexing technique to Lakehouse.
I won’t bore you with the importance of data quality in the blog. Instead, Let’s examine the current datapipeline architecture and ask why data quality is expensive. Instead of looking at the implementation of the data quality frameworks, Let's examine the architectural patterns of the datapipeline.
The costs of developing and running datapipelines are coming under increasing scrutiny because the bills for infrastructure and data engineering talent are piling up. For data teams, it is time to ask: “How can we have an impact on these runaway costs and still deliver unprecedented business value?”
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted. Finally, imagine yourself in the role of a data platform reliability engineer tasked with providing advanced lead time to datapipeline (ETL) owners by proactively identifying issues upstream to their ETL jobs.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your datapipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
I’d like to discuss some popular Data engineering questions: Modern data engineering (DE). Does your DE work well enough to fuel advanced datapipelines and Business intelligence (BI)? Are your datapipelines efficient? and parallel data processing. What is it? ML model training using Airflow.
In the past year, the Bank of the West has begun using the Cloudera platform to establish a data governance and security framework to manage and protect its customers’ sensitive information. The platform is centralizing the data, data management & governance, and building custom controls for dataingestion into the system.
These engineering functions are almost exclusively concerned with datapipelines, spanning ingestion, transformation, orchestration, and observation — all the way to data product delivery to the business tools and downstream applications. Pipelines need to grow faster than the cost to run them.
These engineering functions are almost exclusively concerned with datapipelines, spanning ingestion, transformation, orchestration, and observation — all the way to data product delivery to the business tools and downstream applications. Pipelines need to grow faster than the cost to run them.
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
Then here a list of global resources that can help you navigate through the field: The Data Engineer Roadmap — An image with advices and technology names to watch. Reddit r/dataengineering wiki a place where some data eng definitions are written. workflows (Airflow, Prefect, Dagster, etc.) Is it really modern?
Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed data lakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. Data Preparation (Apache Spark and Apache Hive) .
Cloudera delivers an enterprise data cloud that enables companies to build end-to-end datapipelines for hybrid cloud, spanning edge devices to public or private cloud, with integrated security and governance underpinning it to protect customers data. Data Science and machine learning workloads using CDSW.
CSP was recently recognized as a leader in the 2022 GigaOm Radar for Streaming Data Platforms report. Faster dataingestion: streaming ingestionpipelines. The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities.
Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), Cloudera customers, such as Teranet , have built open lakehouses to future-proof their data platforms for all their analytical workloads. Only metadata will be regenerated. Data quality using table rollback.
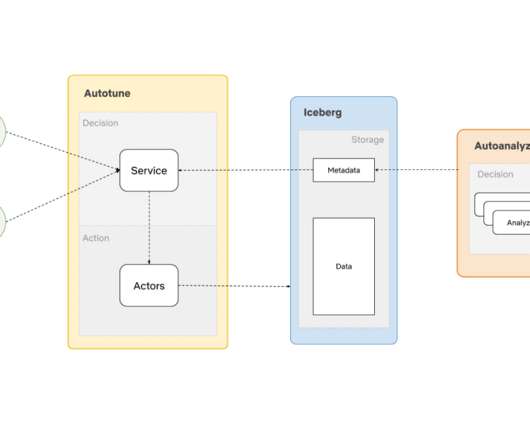
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. Sometimes Data Engineers write downstream ETLs on ingesteddata to optimize the data/metadata layouts to make other ETL processes cheaper and faster.
Data stacks are becoming more and more complex. This brings infinite possibilities for datapipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. What are some of the data management considerations that are introduced by vector databases?
That’s why, in addition to integrating with your central data warehouse , lake , and lakehouse , Monte Carlo also integrates with transformation , orchestration , and now dataingestion tools. Now teams can instantly get full visibility into how these systems may be impacting their data assets, all in a single pane of glass.
Data Flow – is an individual datapipeline. Data Flows include the ingestion of raw data, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the datapipeline workload runs, like Databricks, BigQuery, and Snowflake.
Data Flow – is an individual datapipeline. Data Flows include the ingestion of raw data, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the datapipeline workload runs, like Databricks, BigQuery, and Snowflake.
Leveraging TensorFlow Transform for scaling datapipelines for production environments Photo by Suzanne D. Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. ML Pipeline operations begins with dataingestion and validation, followed by transformation.
Query across your ANN indexes on vector embeddings, and your JSON and geospatial “metadata” fields efficiently. Spin a Virtual Instance for streaming dataingestion. If you know SQL, you already know how to use Rockset. We obsess about efficiency in the cloud. Spin another completely isolated Virtual Instance for your app.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows.
The Solution: ‘Payload’ Data Journeys Traditional Data Observability usually focuses on a ‘process journey,’ tracking the performance and status of datapipelines. ’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of data processes across an organization. These tools help organizations implement DataOps practices by providing a unified platform for data teams to collaborate, share, and manage their data assets.
A true enterprise-grade integration solution calls for source and target connectors that can accommodate: VSAM files COBOL copybooks open standards like JSON modern platforms like Amazon Web Services ( AWS ), Confluent , Databricks , or Snowflake Questions to ask each vendor: Which enterprise data sources and targets do you support?
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
Read Time: 3 Minute, 11 Second This blog post showcases a real-time datapipeline built in Snowflake that leverages Slowly Changing Dimensions (SCD 2) and Finalizer Tasks to ensure your customer data is always fresh, accurate, and reflects historical changes. Snowflake’s Finalizer Tasks come to the rescue!
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
The Essential Six Capabilities To set the stage for impactful and trustworthy data products in your organization, you need to invest in six foundational capabilities. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. How Apache Iceberg tables structure metadata. I think it’s safe to say it’s getting pretty cold in here. Image courtesy of Dremio. So, is Iceberg right for you?
From dataingestion, data science, to our ad bidding[2], GCP is an accelerant in our development cycle, sometimes reducing time-to-market from months to weeks. DataIngestion and Analytics at Scale Ingestion of performance data, whether generated by a search provider or internally, is a key input for our algorithms.
Efficient Scheduling and Runtime Increased Adaptability and Scope Faster Analysis and Real-Time Prediction Introduction to the Machine Learning Pipeline Architecture How to Build an End-to-End a Machine Learning Pipeline? Is python suitable for machine learning pipeline design patterns?
In the case of data products, these are networks of datapipelines, which makes them an integral part of your modern operational machinery. To determine the ROI of any particular data product, you need to attribute the costs of building and running datapipelines.
Data Catalog An organized inventory of data assets relying on metadata to help with data management. Data Engineering Data engineering is a process by which data engineers make data useful. Data Integration Combining data from various, disparate sources into one unified view.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content