This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
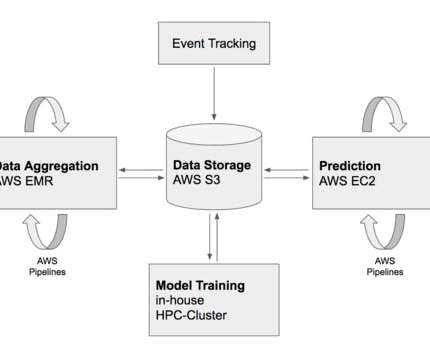
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Visualize data through charts and graphs and compile reports for stakeholders. A typical dataingestion flow.
Faster, easier AI/ML and data engineering workflows Explore, analyze and visualize data using Python and SQL. Discover valuable business insights through exploratory data analysis. Develop scalable datapipelines and transformations for data engineering.
Dataingestion When we think about the flow of data in a pipeline, dataingestion is where the data first enters our platform. Dataingestion When we think about the flow of data in a pipeline, dataingestion is where the data first enters our platform.
A star-studded baseball team is analogous to an optimized “end-to-end datapipeline” — both require strategy, precision, and skill to achieve success. Just as every play and position in baseball is key to a win, each component of a datapipeline is integral to effective data management.
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
We have simplified this journey into five discrete steps with a common sixth step speaking to data security and governance. The six steps are: Data Collection – dataingestion and monitoring at the edge (whether the edge be industrial sensors or people in a brick and mortar retail store). Conclusion.
Datapipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a DataPipeline? The Importance of a DataPipeline What is an ETL DataPipeline?
Datapipelines are integral to business operations, regardless of whether they are meticulously built in-house or assembled using various tools. As companies become more data-driven, the scope and complexity of datapipelines inevitably expand. Ready to fortify your data management practice?
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Your newly mimicked datasets are safe to share with developers, QA, data scientists—heck, even distributed teams around the world. In fact, while only 3.5% In fact, while only 3.5%
Data Flow – is an individual datapipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the datapipeline workload runs, like Databricks, BigQuery, and Snowflake.
Data Flow – is an individual datapipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the datapipeline workload runs, like Databricks, BigQuery, and Snowflake.
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as dataingestion and processing from different sources, using SQL or Python. Join the #versatile-data-kit channel.
You require a comprehensive solution that addresses every facet, from ingestion and transformation to orchestration and reverse ETL. It’s no surprise, then, that the quest for Fivetran alternatives is on the rise as organizations set their sights on a more holistic data approach. Moreover, rawdata often requires refinement.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows.
The client needed to build its own internal datapipeline with enough flexibility to meet the business requirements for a job market analysis platform & dashboard. The client intends to build on and improve this datapipeline by moving towards a more serverless architecture and adding DevOps tools & workflows.
The client needed to build its own internal datapipeline with enough flexibility to meet the business requirements for a job market analysis platform & dashboard. The client intends to build on and improve this datapipeline by moving towards a more serverless architecture and adding DevOps tools & workflows.
The Third of Five Use Cases in Data Observability Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures data quality from the onset. Examples include regular loading of CRM data and anomaly detection.
If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructured data on their models or analysis. For example, an industrial analytics team wants to use the logs from rawdata. The Data Warehouse(s) facilitates dataingestion and enables easy access for end-users.
The intention of Dynamic Tables is to apply incremental transformations on near real-time dataingestion that Snowflake now supports with Snowpipe Streaming. Data enters Snowflake in its raw operational form (event data) and Dynamic Tables transforms that rawdata into a form that serves analytical value.
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
In the contemporary data landscape, data teams commonly utilize data warehouses or lakes to arrange their data into L1, L2, and L3 layers. The current landscape of Data Observability Tools shows a marked focus on “Data in Place,” leaving a significant gap in the “Data in Use.”
Instead, we can focus on building a flexible and versatile model that can be easily extended to new types of input data and applied to a variety of prediction tasks. In general, learning from rawdata can help to avoid limitations when placing too much confidence in human domain modeling.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable datapipelines, data storage solutions, and data processing systems.
Architecture designed to empower more clients Gem’s cybersecurity platform starts with rawdataingestion from its clients’ cloud environments. Gem uses the fully-managed Snowpipe service, allowing it to stream and process source data in near-real time. Pushing and scaling are super smooth.
A data lake is essentially a vast digital dumping ground where companies toss all their rawdata, structured or not. A modern data stack can be built on top of this data storage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Data teams are tasked with the crucial responsibility of transforming rawdata into valuable insights, a process that directly influences business outcomes. Data Chaos: 100’s or 1,000’s of Pipelines / Duplicate Pipelines In many organizations, data teams manage an overwhelming number of datapipelines.
This continuous adaptation ensures that your data management stays effective and compliant with current standards. The goal is to ensure your organization has the capability to process and prepare data effectively for your AI models. Your datapipeline platform should excel in collecting data from a wide array of sources.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Video explaining how data streaming works.
For this reason, your data platform becomes the foundation for your AI initiatives. Robust DataIngestion AI systems thrive on diverse data sources. Your platform should be equipped with robust mechanisms for dataingestion and integration, enabling seamless flow of data from various sources into the system.
Data incompleteness: Corrupted, incomplete, or data missing from your tables, such as dataingested without all the required fields or data damaged due to human or technical errors.
Efficient Scheduling and Runtime Increased Adaptability and Scope Faster Analysis and Real-Time Prediction Introduction to the Machine Learning Pipeline Architecture How to Build an End-to-End a Machine Learning Pipeline? Is python suitable for machine learning pipeline design patterns?
Data storage The tools mentioned in the previous section are instrumental in moving data to a centralized location for storage, usually, a cloud data warehouse, although data lakes are also a popular option. But this distinction has been blurred with the era of cloud data warehouses.
All data will be indexed in real-time , and Rockset’s distributed SQL engine will leverage the indexes and provide sub-second query response times. But until this release, all these data sources involved indexing the incoming rawdata on a record by record basis. That is sufficient for some use cases.
There’s also some static reference data that is published on web pages. ?After Wrangling the data. With the rawdata in Kafka, we can now start to process it. Since we’re using Kafka, we are working on streams of data. After we scrape these manually, they are produced directly into a Kafka topic.
We’ll cover: What is a data platform? Databricks – Databricks, the Apache Spark-as-a-service platform, has pioneered the data lakehouse, giving users the options to leverage both structured and unstructured data and offers the low-cost storage features of a data lake.
Already operating at capacity, data teams often find themselves repeating efforts, rebuilding similar datapipelines and models for each new project. The consequences of these challenges are stark: the journey from rawdata to actionable insights has become excruciatingly long.
Data collection vs data integration vs dataingestionData collection is often confused with dataingestion and data integration — other important processes within the data management strategy. While all three are about data acquisition, they have distinct differences.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role. This big data project discusses IoT architecture with a sample use case.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of rawdata.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content