This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
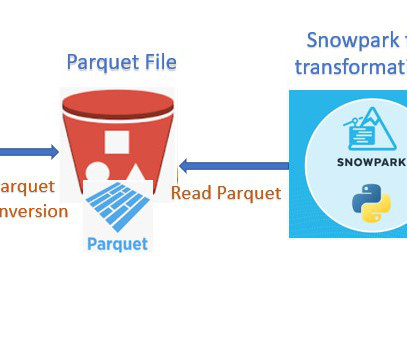
Parquet, columnar storage file format saves both time and space when it comes to big dataprocessing. Snowflake Output Happy 0 0 % Sad 0 0 % Excited 0 0 % Sleepy 0 0 % Angry 0 0 % Surprise 0 0 % The post DataIngestion with Glue and Snowpark appeared first on Cloudyard. Technical Implementation: GLUE Job.
Since it takes so long to iterate on workflows, some ML engineers started to perform dataprocessing directly inside training jobs. This is what we commonly refer to as Last Mile DataProcessing. Last Mile processing can boost ML engineers’ velocity as they can write code in Python, directly using PyTorch.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source dataingestion and processing framework designed to simplify data management complexities.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
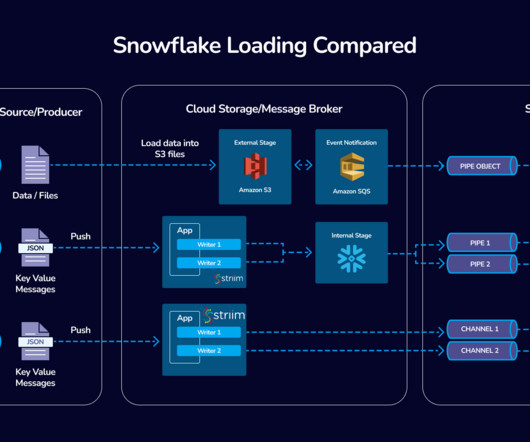
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Striim’s integration with Snowpipe Streaming represents a significant advancement in real-time dataingestion into Snowflake.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion?
Conventional batch processing techniques seem incomplete in fulfilling the demand of driving the commercial environment. This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processingdata for later use or storage in a database.
It employs Snowpark Container Services to build scalable AI/ML models for satellite dataprocessing and Snowflake AI/ML functions to enable advanced analytics and predictive insights for satellite operators.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. With careful consideration and learning about your market, the choices you need to make become narrower and more clear. I'll use Python and Spark because they are the top 2 requested skills in Toronto.
The author emphasizes the importance of mastering state management, understanding "local first" dataprocessing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. link] Grab: Improving Hugo's stability and addressing oncall challenges through automation.
On-prem data warehouses can provide lower latency solutions for critical applications that require high performance and low latency. Many companies may choose an on-prem data warehousing solution for quicker dataprocessing to enable business decisions. Data integrations and pipelines can also impact latency.
Customers can process changed data once or twice a day — or at whatever cadence they prefer — to the main table. SNP has been able to provide customers with a 10x cost reduction in Snowflake dataprocessing associated with SAP dataingestion.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. Core Digital Media’s BI team began evaluating infrastructure enhancements.
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a data pipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective dataprocessing and analysis.
Summary Real-time dataprocessing has steadily been gaining adoption due to advances in the accessibility of the technologies involved. To bring streaming data in reach of application engineers Matteo Pelati helped to create Dozer. To bring streaming data in reach of application engineers Matteo Pelati helped to create Dozer.
Data infrastructure that makes light work of complex tasks Built as a connected application from day one, the anecdotes Compliance OS uses the Snowflake Data Cloud for dataingestion and modeling, including a single cybersecurity data lake where all data can be analyzed within Snowflake.
Architectural Patterns for Data Quality Now we understand the trade-off between speed & correctness and the difference between data testing and observability. Let’s talk about the dataprocessing types. In the 'Write' stage, we capture the computed data in a log or a staging area.
While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange. Dataingestion through ‘s3’. Ozone Namespace Overview.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
Streaming and Real-Time DataProcessing As organizations increasingly demand real-time data insights, Open Table Formats offer strong support for streaming dataprocessing, allowing organizations to seamlessly merge real-time and batch data.
Figure 2: Questions answered by precision medicine Snowflake and FAIR in the world of precision medicine and biomedical research Cloud-based big data technologies are not new for large-scale dataprocessing. A conceptual architecture illustrating this is shown in Figure 3.
Easy Processing- PySpark enables us to processdata rapidly, around 100 times quicker in memory and ten times faster on storage. When it comes to dataingestion pipelines, PySpark has a lot of advantages. PySpark allows you to processdata from Hadoop HDFS , AWS S3, and various other file systems.
While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterprises in their IoT initiatives around edge management and edge data collection.
Here’s what implementing an open data lakehouse with Cloudera delivers: Integration of Data Lake and Data Warehouse : An open data lakehouse brings together the best of both worlds by integrating the storage flexibility of a data lake with the query performance and structured querying capabilities of a data warehouse.
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig.
Schedule dataingestion, processing, model training and insight generation to enhance efficiency and consistency in your dataprocesses. Connect your preferred platform (GitHub, GitLab, Bitbucket, Azure DevOps) to manage and track changes for collaborative development.
Data integration and ingestion: With robust data integration capabilities, a modern data architecture makes real-time dataingestion from various sources—including structured, unstructured, and streaming data, as well as external data feeds—a reality.
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve dataprocessing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production.
This flexibility allows tracer libraries to record 100% traces in our mission-critical streaming microservices while collecting minimal traces from auxiliary systems like offline batch dataprocessing. The next challenge was to stream large amounts of traces via a scalable dataprocessing platform.
Our comprehensive data-level security, auditing and de-identification features eliminate the need for time-consuming manual processes and our focus on data and compliance team collaboration empowers you to deliver quick and valuable data analytics on the most sensitive data to unlock the full potential of your cloud data platforms.
He wrote some years ago 3 articles defining data engineering field. Some concepts When doing data engineering you can touch a lot of different concepts. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory.
Finally, Tasks Backfill (PrPr) automates historical dataprocessing within Task Graphs. Additionally, Dynamic Tables are a new table type that you can use at every stage of your processing pipeline. Follow this quickstart to test-drive Dynamic Tables yourself. Snowflake integrates with GitHub, GitLab, Azure DevOps and Bitbucket.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows.
While you can use Snowpipe for straightforward and low-complexity dataingestion into Snowflake, Snowpipe alternatives, like Kafka, Spark, and COPY, provide enhanced capabilities for real-time dataprocessing, scalability, flexibility in data handling, and broader ecosystem integration.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their dataprocesses. This growing demand has found a natural synergy with the rise of the data lake.
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as dataingestion and processing from different sources, using SQL or Python.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content