This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
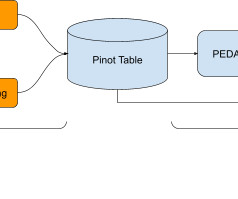
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
transformers) became standardized, ML engineers started to show a growing appetite to iterate on datasets. While such dataset iterations can yield significant gains, we observed that only a handful of such experiments were conducted and productionized in the last six months. As model architecture building blocks (e.g.
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. AvroTensorDataset speeds up data preprocessing by multiple orders of magnitude, enabling us to keep site content as fresh as possible for our members. avro", "part-00001.avro"], Default is zero.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source dataingestion and processing framework designed to simplify data management complexities.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestionprocess.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processingdata for later use or storage in a database.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective dataprocessing and analysis.
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
The data engineering landscape is constantly changing but major trends seem to remain the same. How to Become a Data Engineer As a data engineer, I am tasked to design efficient dataprocesses almost every day. It was created by Spotify to manage massive dataprocessing workloads. Datalake example.
Furthermore, PySpark allows you to interact with Resilient Distributed Datasets (RDDs) in Apache Spark and Python. Because of its interoperability, it is the best framework for processing large datasets. When it comes to dataingestion pipelines, PySpark has a lot of advantages.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their dataprocesses. This growing demand has found a natural synergy with the rise of the data lake. Visualization tools that map out pipeline dependencies are particularly helpful here.
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. Let’s now dig a little bit deeper into Kafka and Rockset for a concrete example of how to enable real-time interactive queries on large datasets, starting with Kafka. Joining with other datasets.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source: Use Stack Overflow Data for Analytic Purposes 4.
An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. We knew that a heavily sampled trace dataset is not reliable for troubleshooting because there is no guarantee that the request you want is in the gathered samples.
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as dataingestion and processing from different sources, using SQL or Python.
The Five Use Cases in Data Observability: Mastering Data Production (#3) Introduction Managing the production phase of data analytics is a daunting challenge. Overseeing multi-tool, multi-dataset, and multi-hop dataprocesses ensures high-quality outputs. Have I Checked The Raw Data And The Integrated Data?
Big Data vs Small Data: Volume Big Data refers to large volumes of data, typically in the order of terabytes or petabytes. It involves processing and analyzing massive datasets that cannot be managed with traditional dataprocessing techniques.
Cost Efficiency : By minimizing the computational resources required for query processing, de-normalization can lead to cost savings, as query costs in BigQuery are based on the amount of dataprocessed. You can change the billing model in the advanced option for your datasets. Also this query comes at 0 costs.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. For analyzing huge datasets, they want to employ familiar Python primitive types.
Google AI: The Data Cards Playbook: A Toolkit for Transparency in Dataset Documentation Google published Data Cards , a dataset documentation framework aimed at increasing transparency across dataset lifecycles. link] The short YouTube video gives a nice overview of the Data Cards.
Pub/Sub Use Cases Here are a few Google Cloud Pub/Sub use cases that will help you understand how to leverage this messaging service- Stream Processing Using Google Pub/Sub as input and output for stream processing systems such Spark, Flink, or Beam can be helpful for real-time dataprocessing and analysis.
Similarly , in data, every step of the pipeline, from dataingestion to delivery, plays a pivotal role in delivering impactful results. In this article, we’ll break down the intricacies of an end-to-end data pipeline and highlight its importance in today’s landscape.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Big data offers several advantages.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
Acting as the core infrastructure, data pipelines include the crucial steps of dataingestion, transformation, and sharing. DataIngestionData in today’s businesses come from an array of sources, including various clouds, APIs, warehouses, and applications.
Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the dataprocessing components up the stream to address these real-time needs. . Faster dataingestion: streaming ingestion pipelines.
Table of Contents The Common Threads: Ingest, Transform, Share Before we explore the differences between the ETL process and a data pipeline , let’s acknowledge their shared DNA. DataIngestionDataingestion is the first step of both ETL and data pipelines.
But behind the scenes, Uber is also a leader in using data for business decisions, thanks to its optimized data lake. Incremental DataProcessing with Apache Hudi : Uber’s data lake uses Apache Hudi to enable incremental ETL processes, processing only new or updated data instead of recomputing everything.
We say that an algorithm is differentially private if any result of the algorithm cannot depend too much on any single data record in a dataset. Hence, differential privacy provides uncertainty for whether or not an individual data record is in the dataset. For data retrieval, we expose multiple Rest.li
DataIngestionDataProcessingData Splitting Model Training Model Evaluation Model Deployment Monitoring Model Performance Machine Learning Pipeline Tools Machine Learning Pipeline Deployment on Different Platforms FAQs What tools exist for managing data science and machine learning pipelines?
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. MQTT Proxy for dataingestion without an MQTT broker.
Data Teams and Their Types of Data Journeys In the rapidly evolving landscape of data management and analytics, data teams face various challenges ranging from dataingestion to end-to-end observability. It explores why DataKitchen’s ‘Data Journeys’ capability can solve these challenges.
Given the complexity of the datasets used to train AI systems, and factoring in the known tendency of generative AI systems to invent non-factual information, this is no small task. Deploy a hybrid data platform. Basic Process Automation. Plan to scale for the future. Formalize ethics and bias testing.
Table of Contents Understanding What Drives Cloud Costs So, what exactly are the primary factors driving cloud costs within a typical dataprocessing environment? Cloud providers usually have associated costs for data movement, which in our reference pipeline network makes up another 30% of the bill. cents per gigabyte.
From dataingestion, data science, to our ad bidding[2], GCP is an accelerant in our development cycle, sometimes reducing time-to-market from months to weeks. DataIngestion and Analytics at Scale Ingestion of performance data, whether generated by a search provider or internally, is a key input for our algorithms.
Databricks architecture Databricks provides an ecosystem of tools and services covering the entire analytics process — from dataingestion to training and deploying machine learning models. Besides that, it’s fully compatible with various dataingestion and ETL tools. Let’s see what exactly Databricks has to offer.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content