This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Every developer who uses Apache Kafka ® has used a Kafka consumer at least once. Although it is the simplest way to subscribe to and access events from Kafka, behind the scenes, Kafka consumers handle tricky distributed systems challenges like data consistency, failover and load balancing. Consistency.
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js
A key challenge, however, is integrating devices and machines to process the data in real time and at scale. Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. Kafka, while not in the top 5 most in demand skills, was still the most requested buffer technology requested which makes it worthwhile to include it. I'll use Python and Spark because they are the top 2 requested skills in Toronto.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Architectural Patterns for Data Quality Now we understand the trade-off between speed & correctness and the difference between data testing and observability. Let’s talk about the dataprocessing types. In the 'Write' stage, we capture the computed data in a log or a staging area.
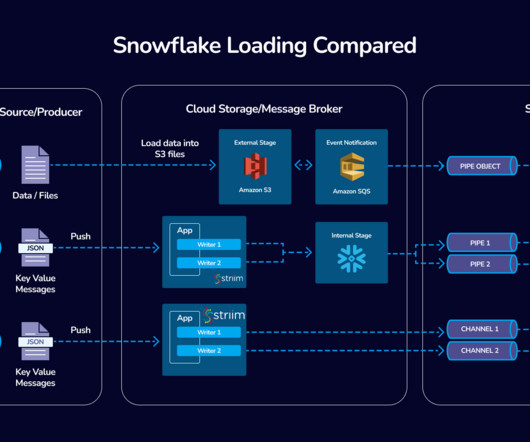
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Striim’s integration with Snowpipe Streaming represents a significant advancement in real-time dataingestion into Snowflake.
Conventional batch processing techniques seem incomplete in fulfilling the demand of driving the commercial environment. This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion?
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. STEP 4: Capture data from Apache Kafka streams.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. Snowflake's separate clusters for ETL, reporting and data science eliminated resource contention.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Druid’s native support for ingestingdata from Apache Kafka allows it to stream data from Cloudera DataFlow to Rill’s fully managed Druid service. Data is made queryable in real time. The Druid native Kafka indexing service features: Pull-based ingestion. Cloudera Data Warehouse).
Our comprehensive data-level security, auditing and de-identification features eliminate the need for time-consuming manual processes and our focus on data and compliance team collaboration empowers you to deliver quick and valuable data analytics on the most sensitive data to unlock the full potential of your cloud data platforms.
He wrote some years ago 3 articles defining data engineering field. Some concepts When doing data engineering you can touch a lot of different concepts. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory.
While you can use Snowpipe for straightforward and low-complexity dataingestion into Snowflake, Snowpipe alternatives, like Kafka, Spark, and COPY, provide enhanced capabilities for real-time dataprocessing, scalability, flexibility in data handling, and broader ecosystem integration.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Stock and Twitter Data Extraction Using Python, Kafka, and Spark 2.
These roles will span various sectors, including data science, AI ethics, machine learning engineering, and AI-related research and development. Real-Time Data — The Missing Link What is Real-Time Data? Misconception: Batch Processing Suffices Objection: Many AI/ML tasks can be handled with batch processing.
Current and up-to-date data helps enhance the efficiency of services, improve customer experiences, and drive innovation. DataIngestionData from different streams, such as applications, sensors, etc., Enabling Data Access Once the dataprocessing is complete, the real-time data is available in the data stream.
But the key point here is if we can shrink the incremental dataprocessing that can fit into a single machine, the greater the cost efficiency of data infrastructure. We need to take these concepts but should rethink to fit the data model to take advantage of both the software and hardware advancements.
This flexibility enables organizations to tailor dataprocessing to their specific needs. More Than a Data Streaming Platform Beyond streaming data, Striim delivers on dataingestion through Change Data Capture (CDC), ELT, ETL, and snapshots.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. As the demand for data engineers grows, having a well-written resume that stands out from the crowd is critical.
These Azure data engineer projects provide a wonderful opportunity to enhance your data engineering skills, whether you are a beginner, an intermediate-level engineer, or an advanced practitioner. Who is Azure Data Engineer? Azure SQL Database, Azure Data Lake Storage). Azure SQL Database, Azure Data Lake Storage).
Big data pipelines must be able to recognize and processdata in various formats, including structured, unstructured, and semi-structured, due to the variety of big data. Over the years, companies primarily depended on batch processing to gain insights. However, it is not straightforward to create data pipelines.
Data Engineering Project for Beginners If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of data engineering project examples below. This big data project discusses IoT architecture with a sample use case.
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? Kafka Stream vs. Spark Streaming What is Spark streaming? live logs, IoT device data, system telemetry data, etc.)
These roles will span various sectors, including data science, AI ethics, machine learning engineering, and AI-related research and development. Real-Time Data — The Missing Link What is Real-Time Data? Rebuttal: “While real-time systems require an investment, the ROI is substantial.
Big Data analytics encompasses the processes of collecting, processing, filtering/cleansing, and analyzing extensive datasets so that organizations can use them to develop, grow, and produce better products. Big Data analytics processes and tools. Dataingestion. Apache Kafka.
Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively. Dataprocessing: Data engineers should know dataprocessing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructured data. Big Query Google’s cloud data warehouse. Flat File A type of database that stores data in a plain text format.
Why is data pipeline architecture important? 5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big dataprocessing capabilities to mainstream organizations. Despite Hadoop’s parallel and distributed processing, compute was a limited resource as well.
These languages are used to write efficient, maintainable code and create scripts for automation and dataprocessing. Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%).
These languages are used to write efficient, maintainable code and create scripts for automation and dataprocessing. Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%).
It relieves the MapReduce engine of scheduling tasks and decouples dataprocessing from resource management. To facilitate dataingestion, there are Apache Flume aggregating log data from multiple servers and Apache Sqoop designed to transport information between Hadoop and relational (SQL) databases.
Examples of unstructured data can range from sensor data in the industrial Internet of Things (IoT) applications, videos and audio streams, images, and social media content like tweets or Facebook posts. DataingestionDataingestion is the process of importing data into the data lake from various sources.
With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big dataprocessing. DataFrames are used by Spark SQL to accommodate structured and semi-structured data. CMAK is developed to help the Kafka community.
As per Apache, “ Apache Spark is a unified analytics engine for large-scale dataprocessing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R. billion (2019 - 2022).
GCP Data Engineer Certification The Google Cloud Certified Professional Data Engineer certification is ideal for data professionals whose jobs generally involve data governance, data handling, dataprocessing, and performing a lot of feature engineering on data to prepare it for modeling.
First, CDC theoretically allows companies to analyze and react to data in real time, as it’s generated. It works with existing streaming systems like Apache Kafka, Amazon Kinesis, and Azure Events Hubs, making it easier than ever to build a real-time data pipeline. This method offers a few enormous advantages over batch updates.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content