This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This influx of data and surging demand for fast-moving analytics has had more companies find ways to store and processdata efficiently. This is where Data Engineers shine! The first step in any data engineering project is a successful dataingestion strategy.
According to Bill Gates, “The ability to analyze data in real-time is a game-changer for any business.” ” Thus, don't miss out on the opportunity to revolutionize your business with real-time dataprocessing using Azure Stream Analytics. Table of Contents What is Azure Stream Analytics?
Navigating the complexities of data engineering can be daunting, often leaving data engineers grappling with real-time dataingestion challenges. Our comprehensive guide will explore the real-time dataingestionprocess, enabling you to overcome these hurdles and transform your data into actionable insights.
Tired of wasting hours on repetitive data tasks? Scaling businesses experience complex data pipelines and large volumes of data. From dataingestion, transformation, and storage, ETL workflows can become extensive. Manual workflows don’t fit the bill and are prone to errors and inconsistencies.
Begin Your Big Data Journey with ProjectPro's Project-Based Apache Spark Online Course ! PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. When it comes to dataingestion pipelines, PySpark has a lot of advantages.
Behind the scenes, hundreds of ML engineers iteratively improve a wide range of recommendation engines that power Pinterest, processing petabytes of data and training thousands of models using hundreds of GPUs. In some cases, petabytes of data are streamed into training jobs to train a model.
Tired of wasting hours on repetitive data tasks? Scaling businesses experience complex data pipelines and large volumes of data. From dataingestion, transformation, and storage, ETL workflows can become extensive. Manual workflows don’t fit the bill and are prone to errors and inconsistencies.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source dataingestion and processing framework designed to simplify data management complexities.
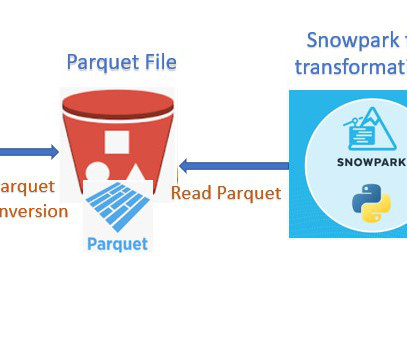
Parquet, columnar storage file format saves both time and space when it comes to big dataprocessing. Snowflake Output Happy 0 0 % Sad 0 0 % Excited 0 0 % Sleepy 0 0 % Angry 0 0 % Surprise 0 0 % The post DataIngestion with Glue and Snowpark appeared first on Cloudyard. Technical Implementation: GLUE Job.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. Store the data in in Google Cloud Storage to ensure scalability and reliability. by ingesting raw data into a cloud storage solution like AWS S3.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processingdata for later use or storage in a database.
A machine learning pipeline helps automate machine learning workflows by processing and integrating data sets into a model, which can then be evaluated and delivered. Increased Adaptability and Scope Although you require different models for different purposes, you can use the same functions/processes to build those models.
Looking for an efficient tool for streamlining and automating your dataprocessing workflows? Let's consider an example of a dataprocessing pipeline that involves ingestingdata from various sources, cleaning it, and then performing analysis. Airflow operators hold the dataprocessing logic.
The journey from raw data to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process. That’s where data pipeline tools come in. What are Data Pipelines? How Do Data Pipelines Work?
However, we found that many of our workloads were bottlenecked by reading multiple terabytes of input data. To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. If greater than one, records in files are processed in parallel.
Source: Microsoft The primary purpose of a data lake is to provide a scalable, cost-effective solution for storing and analyzing diverse datasets. It allows organizations to access and processdata without rigid transformations, serving as a foundation for advanced analytics, real-time processing, and machine learning models.
Building a batch pipeline is essential for processing large volumes of data efficiently and reliably. Are you ready to step into the heart of big data projects and take control of data like a pro? Batch data pipelines are your ticket to the world of efficient dataprocessing.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
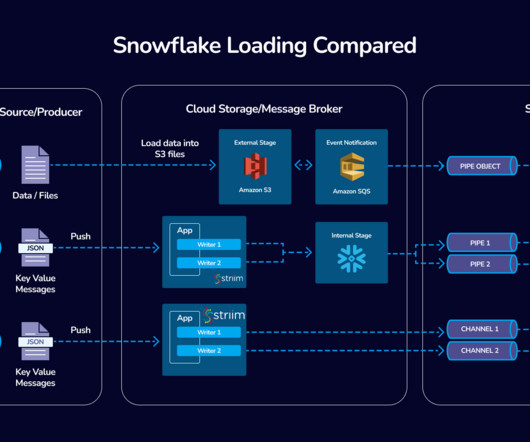
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. As low as 3 seconds P95 latency with 158 gb/hr of Oracle CDC ingest. This method is particularly adept at handling large data sets securely and efficiently.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
With the rapid growth of data in the industry, businesses often deal with several challenges when handling complex processes such as data integration and analytics. This increases the demand for big dataprocessing tools such as AWS Glue.
By enabling advanced analytics and centralized document management, Digityze AI helps pharmaceutical manufacturers eliminate data silos and accelerate data sharing. KAWA Analytics Digital transformation is an admirable goal, but legacy systems and inefficient processes hold back many companies efforts.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion?
Conventional batch processing techniques seem incomplete in fulfilling the demand of driving the commercial environment. This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestionprocess.
Did you know “ According to Google, Cloud Dataflow has processed over 1 exabyte of data to date.” The challenges of managing big data are well-known to anyone who has ever worked with it. These needs include event-time ordering, windowing by data attributes, and the demand for immediate answers.
With the ability to handle streaming dataingestion rates of up to millions of events per second, Amazon Kinesis has become a popular choice for high-volume dataprocessing applications. Ready to take your data streaming to the next level? Look no further than Amazon Kinesis!
The architecture dynamically incorporates real-time, enterprise-specific data to enrich its outputs, which is unlike standard LLMs that rely only on pre-trained knowledge. Let us understand how the RAG LLM architecture works: First, enterprise data—such as documents, tables, or media—is processed.
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. With careful consideration and learning about your market, the choices you need to make become narrower and more clear. I'll use Python and Spark because they are the top 2 requested skills in Toronto.
This is why companies turn to data pipeline solutions, which can extract, transform, and store data into centralized repositories for generating actionable business insight. These automated processes allow data scientists and analysts to focus on their work rather than worrying about poorly modeled, seldom updated, or unavailable data.
Data engineering is gradually becoming the backbone of companies looking forward to leveraging data to improve business processes. This blog will discover how Python has become an integral part of implementing data engineering methods by exploring how to use Python for data engineering.
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. This is crucial for maintaining data integrity and quality.
With over 10 million active subscriptions, 50 million active topics, and a trillion messages processed per day, Google Cloud Pub/Sub makes it easy to build and manage complex event-driven systems. Google Cloud Pub/Sub is a global, cloud-based messaging framework that has become increasingly popular among data engineers over recent years.
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. RDD uses a key to partition data into smaller chunks.
For many businesses, gathering compliance data means manually collecting PDFs and screenshots. That’s a slow and laborious process, but anecdotes AI streamlines compliance and eliminates redundant work with its advanced compliance data infrastructure. The Data Cloud unlocks massive go-to-market opportunities.”
In 2023, more than 5140 businesses worldwide have started using AWS Glue as a big data tool. For e.g., Finaccel, a leading tech company in Indonesia, leverages AWS Glue to easily load, process, and transform their enterprise data for further processing. AWS Glue automates several processes as well.
These tools are responsible for making the day-to-day tasks of a data engineer easier in various ways. Dataingestion systems such as Kafka , for example, offer a seamless and quick dataingestionprocess while also allowing data engineers to locate appropriate data sources, analyze them, and ingestdata for further processing.
Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment.
What industry is big data developer in? What is a Big Data Developer? A Big Data Developer is a specialized IT professional responsible for designing, implementing, and managing large-scale dataprocessing systems that handle vast amounts of information, often called "big data." Billion by 2026.
Data is often referred to as the new oil, and just like oil requires refining to become useful fuel, data also needs a similar transformation to unlock its true value. This transformation is where data warehousing tools come into play, acting as the refining process for your data. Standard SQL support for querying.
Enter Azure Databricks – the game-changing platform that empowers data professionals to streamline their workflows and unlock the limitless potential of their data. With Azure Databricks, managing and analyzing large volumes of data becomes effortlessly seamless. What is Azure Databricks Used for?
If you are willing to gain hands-on experience with Google BigQuery , you must explore the GCP Project to Learn using BigQuery for Exploring Data. Google Cloud Dataproc Dataproc is a fully-managed and scalable Spark and Hadoop Service that supports batch processing, querying, streaming, and machine learning. PREVIOUS NEXT <
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content