This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized datastorage. Flume is a tool that is very dependable, distributed, and customizable.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. DataStorage : Store validated data in a structured format, facilitating easy access for analysis. A typical dataingestion flow.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics. Contact phData Today!
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud datastorage capacity.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
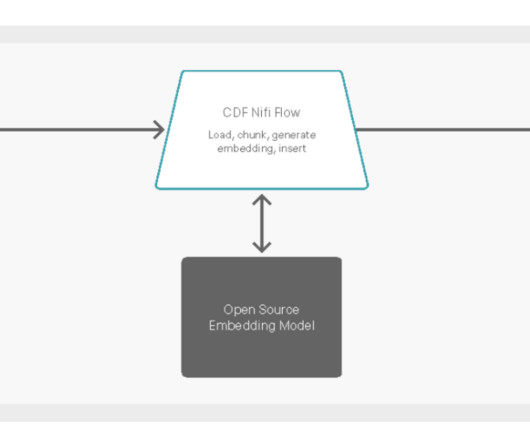
The connector makes it easy to update the LLM context by loading, chunking, generating embeddings, and inserting them into the Pinecone database as soon as new data is available. High-level overview of real-time dataingest with Cloudera DataFlow to Pinecone vector database.
For example, the datastorage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. A conceptual architecture illustrating this is shown in Figure 3.
Future connected vehicles will rely upon a complete data lifecycle approach to implement enterprise-level advanced analytics and machine learning enabling these advanced use cases that will ultimately lead to fully autonomous drive.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
formats — This is a huge part of data engineering. Picking the right format for your datastorage. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory. workflows (Airflow, Prefect, Dagster, etc.)
As data volumes grow and analytical needs evolve, organizations can seamlessly scale their infrastructure horizontally to accommodate increased dataingestion, processing, and storage demands.
The organization was locked into a legacy data warehouse with high operational costs and inability to perform exploratory analytics. With more than 25TB of dataingested from over 200 different sources, Telkomsel recognized that to best serve its customers it had to get to grips with its data. .
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like data pipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
Storage — Snowflake Snowflake, a cloud-based data warehouse tailored for analytical needs, will serve as our datastorage solution. The data volume we will deal with is small, so we will not try to overkill with data partitioning, time travel, Snowpark, and other Snowflake advanced capabilities.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows. As a result, they can be slow, inefficient, and prone to errors.
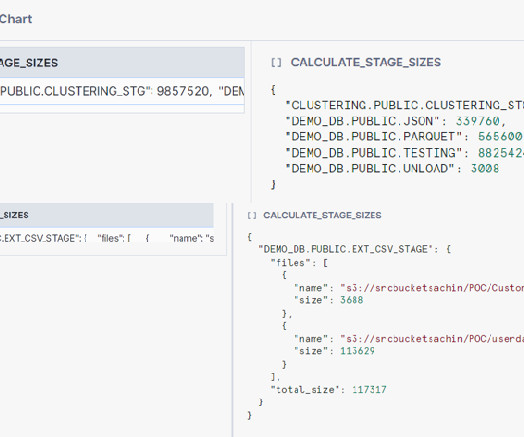
Read Time: 1 Minute, 39 Second Many organizations leverage Snowflake stages for temporary datastorage. However, with ongoing dataingestion and processing, it’s easy to lose track of stages containing old, potentially unnecessary data. This can lead to wasted storage costs.
Comparison of Snowflake Copilot and Cortex Analyst Cortex Search: Deliver efficient and accurate enterprise-grade document search and chatbots Cortex Search is a fully managed search solution that offers a rich set of capabilities to index and query unstructured data and documents. Our state-of-the-art hybrid search enables better results.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
The data read queries took an increasingly longer time to finish because ElasticSearch clusters were using heavy compute resources for creating indexes on ingested traces. The high dataingestion rate eventually degraded both read and write operations.
[link] Freshworks: Modernizing analytics dataingestion pipeline from legacy engine to distributed processing engine The article discusses Freshworks' journey in modernizing its analytics data platform to handle increasing volumes of data efficiently.
For example, we are integrating architecture diagrams for active/passive, geographically dispersed disaster recovery cluster pairs like the following diagram, showing a common application zone and for dataingestion and analytics, and how replication moves through the system.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. The data objects are accessible only through SQL query operations run using Snowflake.
Data observability works with your data pipeline by providing insights into how your data flows and is processed from start to end. Here is a more detailed explanation of how data observability works within the data pipeline: Dataingestion : Observability begins from the point where data is ingested into the pipeline.
Rockset offers a number of benefits along with vector search support to create relevant experiences: Real-Time Data: Ingest and index incoming data in real-time with support for updates. Feature Generation: Transform and aggregate data during the ingest process to generate complex features and reduce datastorage volumes.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable data pipelines, datastorage solutions, and data processing systems.
Some of the more interesting use cases include: Customer service triage, response generation, and eventually full-chat experiences, as described above Advertising creative generation personalized for each customer, based on everything you know about each customer in Snowflake SQL-drafting and question-answering data analysis chatbots based on your (..)
This exam measures your ability to design and implement data management, data processing, and data security solutions using Azure data services. The course covers the skills and knowledge required to design and implement data management, data processing, and data security solutions using Azure data services.
This blog will guide you through the best data modeling methodologies and processes for your data lake, helping you make informed decisions and optimize your data management practices. What is a Data Lake? What are Data Modeling Methodologies, and Why Are They Important for a Data Lake? Contact phData Today!
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations. Key Features of Databricks 1.
The history of big data takes people on an astonishing journey of big data evolution, tracing the timeline of big data. The Emergence of DataStorage and Processing Technologies A datastorage facility first appeared in the form of punch cards, developed by Basile Bouchon to facilitate pattern printing on textiles in looms.
It is meant for you to assess if you have thought through processes such as continuous dataingestion, enterprise data integration and data governance. Data infrastructure readiness – IoT architectures can be insanely complex and sophisticated.
While this “data tsunami” may pose a new set of challenges, it also opens up opportunities for a wide variety of high value business intelligence (BI) and other analytics use cases that most companies are eager to deploy. . Traditional data warehouse vendors may have maturity in datastorage, modeling, and high-performance analysis.
At its core, CDP Private Cloud Data Services (“the platform”) is an end-to-end cloud native platform that provides a private open data lakehouse. It offers features such as dataingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment.
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining data pipelines, datastorage solutions, data processing, and data integration to enable data-driven decision-making inside a company.
An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining data processing systems and solutions on the Microsoft Azure cloud platform. A Data Engineer is responsible for designing the entire architecture of the data flow while taking the needs of the business into account.
A data lake is essentially a vast digital dumping ground where companies toss all their raw data, structured or not. A modern data stack can be built on top of this datastorage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
It encompasses data from diverse sources such as social media, sensors, logs, and multimedia content. The key characteristics of big data are commonly described as the three V's: volume (large datasets), velocity (high-speed dataingestion), and variety (data in different formats).
Tools and platforms for unstructured data management Unstructured data collection Unstructured data collection presents unique challenges due to the information’s sheer volume, variety, and complexity. The process requires extracting data from diverse sources, typically via APIs. Data durability and availability.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content