This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized datastorage. Flume is a tool that is very dependable, distributed, and customizable.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. DataStorage : Store validated data in a structured format, facilitating easy access for analysis. A typical dataingestion flow.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a data warehouse at the center. What is Hadoop? Is it really modern?
News on Hadoop- March 2016 Hortonworks makes its core more stable for Hadoop users. PCWorld.com Hortonworks is going a step further in making Hadoop more reliable when it comes to enterprise adoption. Hortonworks Data Platform 2.4, Source: [link] ) Syncsort makes Hadoop and Spark available in native Mainframe.
The interesting world of big data and its effect on wage patterns, particularly in the field of Hadoop development, will be covered in this guide. As the need for knowledgeable Hadoop engineers increases, so does the debate about salaries. You can opt for Big Data training online to learn about Hadoop and big data.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
With the help of ProjectPro’s Hadoop Instructors, we have put together a detailed list of big dataHadoop interview questions based on the different components of the Hadoop Ecosystem such as MapReduce, Hive, HBase, Pig, YARN, Flume, Sqoop , HDFS, etc. What is the difference between Hadoop and Traditional RDBMS?
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Dataingestion.
There are three steps involved in the deployment of a big data model: DataIngestion: This is the first step in deploying a big data model - Dataingestion, i.e., extracting data from multiple data sources. How is Hadoop related to Big Data? RDBMS stores structured data.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Data processing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. The process requires extracting data from diverse sources, typically via APIs.
The key characteristics of big data are commonly described as the three V's: volume (large datasets), velocity (high-speed dataingestion), and variety (data in different formats). Unlike big data warehouse, big data focuses on processing and analyzing data in its raw and unstructured form.
The history of big data takes people on an astonishing journey of big data evolution, tracing the timeline of big data. The Emergence of DataStorage and Processing Technologies A datastorage facility first appeared in the form of punch cards, developed by Basile Bouchon to facilitate pattern printing on textiles in looms.
An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining data processing systems and solutions on the Microsoft Azure cloud platform. A Data Engineer is responsible for designing the entire architecture of the data flow while taking the needs of the business into account.
Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
Big Data Large volumes of structured or unstructured data. Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse.
Forrester describes Big Data Fabric as, “A unified, trusted, and comprehensive view of business data produced by orchestrating data sources automatically, intelligently, and securely, then preparing and processing them in big data platforms such as Hadoop and Apache Spark, data lakes, in-memory, and NoSQL.”.
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
Data lakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Notice how Snowflake dutifully avoids (what may be a false) dichotomy by simply calling themselves a “data cloud.” Not to mention seamless integration with the Oracle ecosystem.
Batch jobs are often scheduled to load data into the warehouse, while real-time data processing can be achieved using solutions like Apache Kafka and Snowpipe by Snowflake to stream data directly into the cloud warehouse. But this distinction has been blurred with the era of cloud data warehouses.
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations. Key Features of Databricks 1.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Transformation section.
These languages are used to write efficient, maintainable code and create scripts for automation and data processing. Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%).
These languages are used to write efficient, maintainable code and create scripts for automation and data processing. Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%).
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including data collection and ingestion, data analytics, datastorage, data warehousing, data processing, and data visualization.
Tech Mahindra Tech Mahindra is a service-based company with a data-driven focus. The complex data activities, such as dataingestion, unification, structuring, cleaning, validating, and transforming, are made simpler by its self-service. It also makes it easier to load the data into destination databases.
Why is data pipeline architecture important? 5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Singer – An open source tool for moving data from a source to a destination.
Knowledge of popular big data tools like Apache Spark, Apache Hadoop, etc. Good communication skills as a data engineer directly works with the different teams. These tools complement the knowledge of cloud computing as data engineers often implement codes that can handle large datasets over the cloud.
DataFrames are used by Spark SQL to accommodate structured and semi-structured data. Apache Spark is also quite versatile, and it can run on a standalone cluster mode or Hadoop YARN , EC2, Mesos, Kubernetes, etc. Presto allows you to query data stored in Hive, Cassandra, relational databases, and even bespoke datastorage.
Speed and performance Speed and performance are foundational to Elasticsearch’s appeal, setting it apart from traditional datastorage and retrieval systems. This remarkable efficiency is a game-changer compared to traditional batch processing engines like Hadoop , enabling real-time analytics and insights.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
A brief history of datastorage The value of data has been apparent for as long as people have been writing things down. Mobile devices, cloud computing, and the internet of things have significantly accelerated growth in data volume and velocity in recent years.
MDVS also serves as the storehouse and the manager for the data schema itself. As was noted in the previous post , data schema could itself evolve over time, but all the data, ingested hitherto, has to remain compliant with the latest schema. this could be computationally intensive in some scenarios.
The latest Azure exam from Microsoft is structured as follows: Design and implement datastorage: Creating and implementing a storage structure, a partition, and a serving layer are tested in this portion (40–45%). You can browse the data lake files with the interactive training material.
Read our article on Hotel Data Management to have a full picture of what information can be collected to boost revenue and customer satisfaction in hospitality. While all three are about data acquisition, they have distinct differences. Find sources of relevant data. Choose data collection methods and tools.
The data is stored in HDFS (Hadoop Distributed File System), which takes a long time to retrieve. Spark saves data in memory (RAM), making data retrieval quicker and faster when needed. Spark is a low-latency computation platform because it offers in-memory datastorage and caching.
When it comes to dataingestion pipelines, PySpark has a lot of advantages. PySpark allows you to process data from Hadoop HDFS , AWS S3, and various other file systems. It begins with complex Json real-time streaming data extraction and CSV parsing, followed by datastorage in HDFS through NiFi.
This involves: Building data pipelines and efficiently storing data for tools that need to query the data. Analyzing the data, ensuring it adheres to data governance rules and regulations. Understanding the pros and cons of datastorage and query options.
Depending on how you measure it, the answer will be 11 million newspaper pages or… just one Hadoop cluster and one tech specialist who can move 4 terabytes of textual data to a new location in 24 hours. The Hadoop toy. So the first secret to Hadoop’s success seems clear — it’s cute. What is Hadoop?
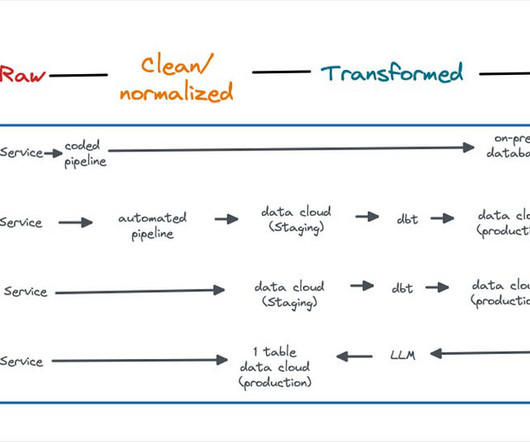
And so it almost seems unfair that new ideas are already springing up to disrupt the disruptors: Zero-ETL has dataingestion in its sights AI and Large Language Models could transform transformation Data product containers are eyeing the table’s thrown as the core building block of data Are we going to have to rebuild everything (again)?
And so it almost seems unfair that new ideas are already springing up to disrupt the disruptors: Zero-ETL has dataingestion in its sights AI and Large Language Models could transform transformation Data product containers are eyeing the table’s thrown as the core building block of data Are we going to have to rebuild everything (again)?
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Big Data Project using Hadoop with Source Code for Web Server Log Processing 5.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content