This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized datastorage. Flume is a tool that is very dependable, distributed, and customizable.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. DataStorage : Store validated data in a structured format, facilitating easy access for analysis. A typical dataingestion flow.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
formats — This is a huge part of data engineering. Picking the right format for your datastorage. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory. workflows (Airflow, Prefect, Dagster, etc.)
In order to achieve our targets, we’ll use pre-built connectors available in Confluent Hub to source data from RSS and Twitter feeds, KSQL to apply the necessary transformations and analytics, Google’s Natural Language API for sentiment scoring, Google BigQuery for datastorage, and Google Data Studio for visual analytics.
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.) Source Code: Yelp Review Analysis 2.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
The author goes beyond comparing the tools to various offerings from streaming vendors in stream processing and Kafka protocol-supported systems. As we predicted in the key trends of 2023 about Apache Flink as a clear winner in the stream processing frameworks, we see Confluent offering Flink as a service.
Rockset offers a number of benefits along with vector search support to create relevant experiences: Real-Time Data: Ingest and index incoming data in real-time with support for updates. Feature Generation: Transform and aggregate data during the ingest process to generate complex features and reduce datastorage volumes.
link] Meta: Tulip - Schematizing Meta’s data platform Numerous heterogeneous services make up a data platform, such as warehouse datastorage and various real-time systems. The schematization of data plays a vital role in a data platform. The author shares the experience of one such transition.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Dataingestion.
3EJHjvm Once a business need is defined and a minimal viable product ( MVP ) is scoped, the data management phase begins with: Dataingestion: Data is acquired, cleansed, and curated before it is transformed. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining data processing systems and solutions on the Microsoft Azure cloud platform. A Data Engineer is responsible for designing the entire architecture of the data flow while taking the needs of the business into account.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructured data. Increasingly, data warehouses and data lakes are moving toward each other in a general shift toward data lakehouse architecture.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructured data. Increasingly, data warehouses and data lakes are moving toward each other in a general shift toward data lakehouse architecture.
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations. Key Features of Databricks 1.
Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
Why is data pipeline architecture important? This is frequently referred to as a 5 or 7 layer (depending on who you ask) data stack like in the image below. Here are some of the most common solutions that are involved in modern data pipelines and the role they play.
No matter the actual size, each cluster accommodates three functional layers — Hadoop distributed file systems for datastorage, Hadoop MapReduce for processing, and Hadoop Yarn for resource management. Yet, its pool of supporters definitely stands out if compared with other Big Data platforms. Hadoop ecosystem evolvement.
Managing cloud-based data services, cost optimization, and scaling are key responsibilities, and these trends are likely to grow along with the future of data governance. Data Pipeline Tools: Familiarity with tools such as Apache Kafka (mentioned in 71% of job postings) and Apache Spark (66%) is vital.
Managing cloud-based data services, cost optimization, and scaling are key responsibilities, and these trends are likely to grow along with the future of data governance. Data Pipeline Tools: Familiarity with tools such as Apache Kafka (mentioned in 71% of job postings) and Apache Spark (66%) is vital.
Data Engineering Data engineering is a process by which data engineers make data useful. Data engineers design, build, and maintain data pipelines that transform data from a raw state to a useful one, ready for analysis or data science modeling. HDFS stands for Hadoop Distributed File System.
It was built from the ground up for interactive analytics and can scale to the size of Facebook while approaching the speed of commercial data warehouses. Presto allows you to query data stored in Hive, Cassandra, relational databases, and even bespoke datastorage. CMAK is developed to help the Kafka community.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Datastorage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloud storage systems. Amazon S3 for AWS, Azure Blob Storage for Azure, or Google Cloud Storage for GCP) to store the actual data files in micro-partitions.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
Data lakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Notice how Snowflake dutifully avoids (what may be a false) dichotomy by simply calling themselves a “data cloud.” Not to mention seamless integration with the Oracle ecosystem.
Speed and performance Speed and performance are foundational to Elasticsearch’s appeal, setting it apart from traditional datastorage and retrieval systems. With native integrations for major cloud platforms like AWS, Azure, and Google Cloud, sending data to Elastic Cloud is straightforward.
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including data collection and ingestion, data analytics, datastorage, data warehousing, data processing, and data visualization.
However, with the advancement of network technologies, there's been a shift back to remote storage. Content indexing and datastorage are increasingly handled by remote machines, overseen by orchestrator machines that execute calls to these storage systems.
This involves: Building data pipelines and efficiently storing data for tools that need to query the data. Analyzing the data, ensuring it adheres to data governance rules and regulations. Understanding the pros and cons of datastorage and query options.
Core components of a Hadoop application are- 1) Hadoop Common 2) HDFS 3) Hadoop MapReduce 4) YARN Data Access Components are - Pig and Hive DataStorage Component is - HBase Data Integration Components are - Apache Flume, Sqoop, Chukwa Data Management and Monitoring Components are - Ambari, Oozie and Zookeeper.
Spark saves data in memory (RAM), making data retrieval quicker and faster when needed. Spark is a low-latency computation platform because it offers in-memory datastorage and caching. The cache() function or the persist() method with proper persistence settings can be used to cache data.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Big Data Project using Hadoop with Source Code for Web Server Log Processing 5.
We’ll cover: What is a data platform? Below, we share what the “basic” data platform looks like and list some hot tools in each space (you’re likely using several of them): The modern data platform is composed of five critical foundation layers. DataStorage and Processing The first layer?
Additionally, this modularity can help prevent vendor lock-in, giving organizations more flexibility and control over their data stack. Many components of a modern data stack (such as Apache Airflow, Kafka, Spark, and others) are open-source and free. But this distinction has been blurred with the era of cloud data warehouses.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











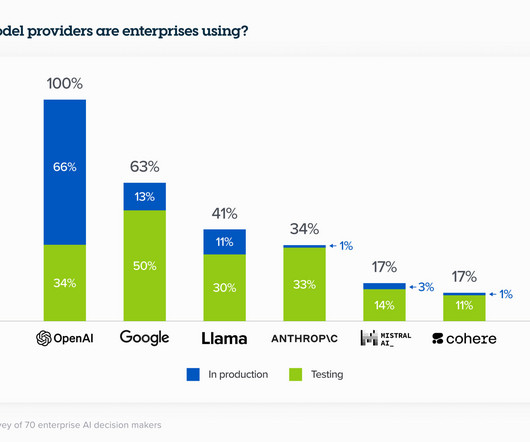


































Let's personalize your content