This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
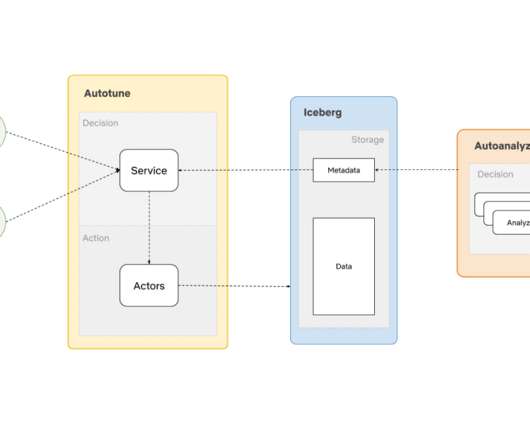
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Dataingestion is the process of collecting data from various sources and moving it to your datawarehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
Introduction Azure data factory (ADF) is a cloud-based dataingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
While the Iceberg itself simplifies some aspects of data management, the surrounding ecosystem introduces new challenges: Small File Problem (Revisited): Like Hadoop, Iceberg can suffer from small file problems. Dataingestion tools often create numerous small files, which can degrade performance during query execution.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a legacy datawarehouse to Snowflake and some of the benefits they saw.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. In fact, while only 3.5%
These trends and demands lead to stress for existing datawarehouse solutions – scale, efficiency, security integrations, IT budgets, ease of access. Cloudera recently launched Cloudera DataWarehouse, a modern data warehousing solution. Here are some highlights: DataIngest.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
Unbound by the limitations of a legacy on-premises solution, its multi-cluster shared data architecture separates compute from storage, allowing data teams to easily scale up and down based on their needs. Data engineers spent 20% of their time on infrastructure issues such as tuning Spark jobs.
Organizations that depend on data for their success and survival need robust, scalable data architecture, typically employing a datawarehouse for analytics needs. Snowflake is often their cloud-native datawarehouse of choice. Dataingestion must be performant to handle large amounts of data.
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 2 ECC data enrichment pipeline.
Examples of data sources and destinations include: Shopify Google Analytics Snowflake Data Cloud Oracle Salesforce Fivetran’s mission is to, “make access to data as easy as electricity” – so for the last 10 years, they have developed their platform into a leader in the cloud-based ELT market. What is Fivetran Used For?
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. workflows (Airflow, Prefect, Dagster, etc.)
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. In fact, while only 3.5%
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Cloudera customers run some of the biggest data lakes on earth. These lakes power mission-critical, large-scale data analytics and AI use cases—including enterprise datawarehouses.
When you activate the query acceleration service when Snowflake thinks that a query can be accelerated it will launch more compute than actually specified by your warehouse. This is funny to see their offering because they offer a "managed datawarehouse storage", which means without the compute.
WAP [Write-Audit-Publish] Pattern The WAP pattern follows a three-step process Write Phase The write phase results from a dataingestion or data transformation step. In the 'Write' stage, we capture the computed data in a log or a staging area. We call this pattern as WAP [Write-Audit-Publish] Pattern. How to Fix It?
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. In fact, while only 3.5%
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
At Isima they decided to reimagine the entire ecosystem from the ground up and built a single unified platform to allow end-to-end self service workflows from dataingestion through to analysis. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
For a more in-depth exploration, plus advice from Snowflake’s Travis Henry, Director of Sales Development Ops and Enablement, and Ryan Huang, Senior Marketing Data Analyst, register for our Snowflake on Snowflake webinar on boosting market efficiency by leveraging data from Outreach. Each of these sources may store data differently.
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a data pipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse). Apache Hive.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. In fact, while only 3.5% That’s where our friends at Ascend.io In fact, while only 3.5%
This tool automates ELT (Extract, Load, Transform) process, integrating your data from the source system of Google Calendar to our Snowflake datawarehouse. Storage — Snowflake Snowflake, a cloud-based datawarehouse tailored for analytical needs, will serve as our data storage solution.
All of these happen continuously and repetitively on a daily basis, amounting to petabytes worth of information and data. This requires massive amounts of dataingestion, messaging, and processing within a data-in-motion context. From a dataingestion standpoint, NiFi is designed for this purpose.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. In fact, while only 3.5% That’s where our friends at Ascend.io In fact, while only 3.5%
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. In fact, while only 3.5%
In order to quickly identify if and how two data systems are out of sync Gleb Mezhanskiy and Simon Eskildsen partnered to create the open source data-diff utility. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. In fact, while only 3.5%
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. In fact, while only 3.5% That’s where our friends at Ascend.io
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content