This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
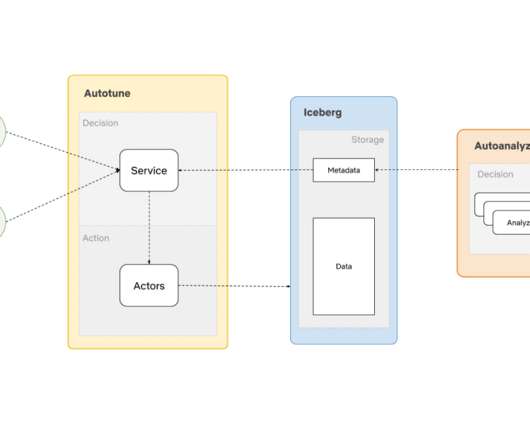
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. In fact, while only 3.5% That’s where our friends at Ascend.io In fact, while only 3.5%
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
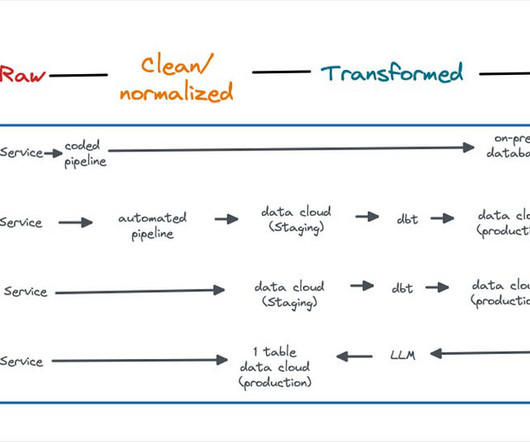
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. In fact, while only 3.5%
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
As part of this movement, Fivetran and dbt fundamentally altered the data pipeline from ETL to ELT. Hightouch interrupted SaaS eating the world in an attempt to shift the center of gravity to the datawarehouse. Other common light transformations done within the ingestion phase are data formatting and deduplication.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. workflows (Airflow, Prefect, Dagster, etc.)
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 2 ECC data enrichment pipeline.
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources. Our dataingestion approach, in a nutshell, is classified broadly into two buckets?—?push We leverage Metacat data, our internal metadata store and service, to enrich lineage data with additional table metadata.
WAP [Write-Audit-Publish] Pattern The WAP pattern follows a three-step process Write Phase The write phase results from a dataingestion or data transformation step. In the 'Write' stage, we capture the computed data in a log or a staging area. Event Routers can add additional metadata to the envelope of the event.
A data engineering manager at a Fortune 500 company expressed the pain of on-prem limitations to me by saying: “Our analysts were unable to run the queries they wanted to run when they wanted to run them. Why are these things related, and more importantly, why should data leaders care? Double check any requirements that say otherwise.
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. Indeed, why would we build a data connector from scratch if it already exists and is being managed in the cloud? The downside of this approach is it’s pricing model though.
Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), Cloudera customers, such as Teranet , have built open lakehouses to future-proof their data platforms for all their analytical workloads. Only metadata will be regenerated. Data quality using table rollback.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of datawarehouses and data lakes, aiming to support AI, BI, ML, and data engineering on a single platform.” Iceberg handles massive data born in the cloud.
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
This tool automates ELT (Extract, Load, Transform) process, integrating your data from the source system of Google Calendar to our Snowflake datawarehouse. Storage — Snowflake Snowflake, a cloud-based datawarehouse tailored for analytical needs, will serve as our data storage solution.
As part of this movement, Fivetran and dbt fundamentally altered the data pipeline from ETL to ELT. Hightouch interrupted SaaS eating the world in an attempt to shift the center of gravity to the datawarehouse. Other common light transformations done within the ingestion phase are data formatting and deduplication.
Summary The optimal format for storage and retrieval of data is dependent on how it is going to be used. For analytical systems there are decades of investment in datawarehouses and various modeling techniques. What are some of the data management considerations that are introduced by vector databases?
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as data lakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
Snowflake Overview A datawarehouse is a critical part of any business organization. Lot of cloud-based datawarehouses are available in the market today, out of which let us focus on Snowflake. Snowflake is an analytical datawarehouse that is provided as Software-as-a-Service (SaaS).
Dive into Spyne's experience with: - Their search for query acceleration with pre-aggregations and caching - Developing new functionality with Open AI - Optimizing query cost with their datawarehouse [link] Suresh Hasuni: Cost Optimization Strategies for Scalable Data Lakehouse Cost is the major concern as the adoption of data lakes increases.
This might include processes like data extraction from different sources, data cleansing, data transformation (like aggregation), and loading the data into a database or a datawarehouse. Data storage and delivery : Observability continues into the storage and delivery phase.
Faster dataingestion: streaming ingestion pipelines. The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities. She is a smart data analyst and former DBA working at a planet-scale manufacturing company.
Want to learn more about data governance? Check out our Data Governance on Snowflake blog! Metadata Management Data modeling methodologies help in managing metadata within the data lake. Metadata describes the characteristics, attributes, and context of the data.
That’s why, in addition to integrating with your central datawarehouse , lake , and lakehouse , Monte Carlo also integrates with transformation , orchestration , and now dataingestion tools. A modified dbt model? Failed Airflow job? None of the above?
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. Ingestion layer 2.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. Ingestion layer 2.
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. It is designed to be easily queryable with SQL even for large analytic tables (we’re talking petabytes of data). How Apache Iceberg tables structure metadata.
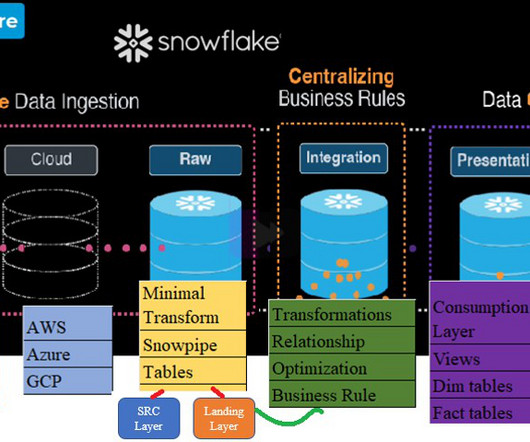
DCDW Architecture Above all, Architecture was divided into three Business layers: Firstly,Agile Dataingestion : Heterogeneous Source System fed the data into Cloud. Respective Cloud would consume/Store the data in bucket or containers. Load the data AS-IS into Snowflake called RAW layer.
At its core, BigQuery is a serverless DataWarehouse for analytical purposes and built-in features like Machine Learning ( BigQuery ML ). Traditionally, normalization has been hailed as a best practice, emphasizing the reduction of redundancy and the preservation of data integrity. Also this query comes at 0 costs.
Weak model lineage can result in reduced model performance, a lack of confidence in model predictions and potentially violation of company, industry or legal regulations on how data is used. . Within the CML data service, model lineage is managed and tracked at a project level by the SDX. Figure 03: lineage.yaml.
Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources. Whether it’s a cloud datawarehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of datawarehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Datawarehouse vs. data lake in a nutshell.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
DuckDB is gaining much attention on this promise, and the Dagster team writes about its experimental datawarehouse built on top of DuckDB, Parquet, and Dagster. link] Sponsored: Why You Should Care About Dimensional Data Modeling It's easy to overlook all of the magic that happens inside the datawarehouse.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a datawarehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. See our post: Data Lakes vs. DataWarehouses.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of data processes across an organization. These tools help organizations implement DataOps practices by providing a unified platform for data teams to collaborate, share, and manage their data assets.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content