This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Open Source Data Pipeline Tools Open-source data pipeline tools are pivotal in data engineering, offering organizations flexible and scalable solutions for managing the end-to-end dataworkflow. Google Cloud Composer Google Cloud Composer is a fully managed workflow orchestration service built on Apache Airflow.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. Project Idea : Build a data pipeline to ingestdata from APIs like CoinGecko or Kaggle’s crypto datasets.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
Apache NiFi Apache NiFi is a commonly used open-source data integration tool for data routing, transformation, and system mediation. NiFi's user-friendly interface allows users to design complex data flows effortlessly, making it an excellent choice for dataingestion and routing tasks.
Dataprep's cutting-edge profiling tools enable the dynamic, simple ingestion of significant statistical data. Gain expertise in big data tools and frameworks with exciting big data projects for students. It runs on Python and is based on the Apache Airflow open-source project. PREVIOUS NEXT <
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a data pipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
OneLake's hierarchical structure simplifies data management across organizations, providing a unified namespace that spans users, regions, and clouds. Microsoft Fabric Use Cases Microsoft Fabric is a transformative solution for industry leaders to streamline data analytics processes and enhance efficiency.
Schedule dataingestion, processing, model training and insight generation to enhance efficiency and consistency in your data processes. Access Snowflake platform capabilities and data sets directly within your notebooks. We invite you to explore Snowflake Notebooks and discover how it can enhance your dataworkflows.
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Can you describe what Hevo Data is and the story behind it?
The AWS Data Engineer Associate Certification specifically validates critical tasks, such as dataingestion, transformation, and orchestration, leveraging programming concepts. Step 2: Master the AWS Data Engineer Certification Syllabus Understanding the exam domains and objectives is crucial for effective preparation.
It offers a scalable and flexible solution for data integration that can handle large volumes of data. It also provides an intuitive visual interface for designing and managing complex dataworkflows, allowing for easy scheduling and monitoring of data pipelines.
In order to quickly identify if and how two data systems are out of sync Gleb Mezhanskiy and Simon Eskildsen partnered to create the open source data-diff utility. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. In fact, while only 3.5%
Step 2: Master Big Data Tools and Technologies Familiarize yourself with the core Big Data technologies and frameworks, such as Hadoop , Apache Spark, and Apache Kafka. These tools are the backbone of Big Data processing and analytics. Apache Kafka: Kafka is a distributed event streaming platform.
Build an ETL Pipeline with Talend for Export of Data from Cloud Learn Efficient Multi-Source Data Processing with Talend ETL Learn How to Implement SCD in Talend to Capture Data Changes Talend Real-Time Project for ETL Process Automation 2. Moreover, automation scripting is crucial for maintaining and monitoring the ETL process.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
From business intelligence to machine learning, Azure Databricks provides a flexible and scalable environment to tackle various data challenges. Working on this project will help you learn the necessary techniques and processes to create and manage live delta tables, enabling real-time dataingestion , updates, and queries.
He explores their collaborative potential in orchestrating, exploring, and analyzing data, shaping a secure and comprehensive data engineering landscape. Its flexibility allows you to easily incorporate changes in data sources, transformations, and destinations.
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. In fact, while only 3.5% That’s where our friends at Ascend.io
Unlike the conventional ETL process, which involves complex data extraction, transformation, and loading steps, Zero ETL directly integrates data from the source to the destination. This integration allows for real-time data processing and analytics, reducing latency and simplifying dataworkflows.
Moreover, you can use ADF Service to transform the ingesteddata to fulfill business requirements. In most Big Data solutions, ADF Service is used as an ETL or ELT tool for dataingestion. Explain the data source in the Azure data factory. Can you list all the activities that can be performed in ADF?
A data science pipeline represents a systematic approach to collecting, processing, analyzing, and visualizing data for informed decision-making. Data science pipelines are essential for streamlining dataworkflows, efficiently handling large volumes of data, and extracting valuable insights promptly.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various dataworkflows.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of data processes across an organization. These tools help organizations implement DataOps practices by providing a unified platform for data teams to collaborate, share, and manage their data assets.
21, 2022 – Ascend.io , The Data Automation Cloud, today announced they have partnered with Snowflake , the Data Cloud company, to launch Free Ingest , a new feature that will reduce an enterprise’s dataingest cost and deliver data products up to 7x faster by ingestingdata from all sources into the Snowflake Data Cloud quickly and easily.
By working on this project, you will gain a comprehensive understanding of crucial aspects like setting up access permissions to ensure data security, establishing triggers for automated dataingestion to keep your data updated, and implementing transformation logic using Cloud Functions.
Editor’s Note: The current state of the Data Catalog The results are out for our poll on the current state of the Data Catalogs. The highlights are that 59% of folks think data catalogs are sometimes helpful. We saw in the Data Catalog poll how far it has to go to be helpful and active within a dataworkflow.
This methodology emphasizes automation, collaboration, and continuous improvement, ensuring faster, more reliable dataworkflows. With dataworkflows growing in scale and complexity, data teams often struggle to keep up with the increasing volume, variety, and velocity of data. Let’s dive in!
In this article, we’ll dive deep into the data presentation layers of the data stack to consider how scale impacts our build versus buy decisions, and how we can thoughtfully apply our five considerations at various points in our platform’s maturity to find the right mix of components for our organizations unique business needs.
Automation plays a critical role in the DataOps framework, as it enables organizations to streamline their data management and analytics processes and reduce the potential for human error. This can be achieved through the use of automated dataingestion, transformation, and analysis tools.
The Third of Five Use Cases in Data Observability Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures data quality from the onset. Examples include regular loading of CRM data and anomaly detection.
Top 10 Azure Data Engineering Project Ideas for Beginners For beginners looking to gain practical experience in Azure Data Engineering, here are 10 Azure Data engineer real time projects ideas that cover various aspects of data processing, storage, analysis, and visualization using Azure services: 1.
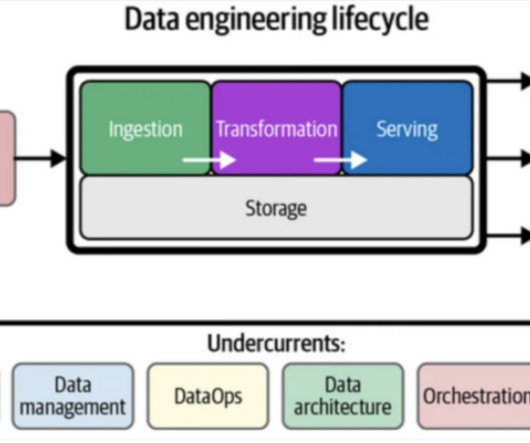
Table of Contents The Common Threads: Ingest, Transform, Share Before we explore the differences between the ETL process and a data pipeline , let’s acknowledge their shared DNA. DataIngestionDataingestion is the first step of both ETL and data pipelines.
Introducing CARTO Workflows Snowflake’s powerful dataingestion and transformation features help many data engineers and analysts who prefer SQL. Workflows automates not only geospatial processes, but other dataworkflows as well.
Data orchestration helps companies comply with various international privacy laws and regulations, many of which require companies to demonstrate the source and rationale for their data collection. As data volume grows, scheduling becomes critical to successfully managing your dataingestion and transformation jobs.
This blog explores the world of open source data orchestration tools, highlighting their importance in managing and automating complex dataworkflows. From Apache Airflow to Google Cloud Composer, we’ll walk you through ten powerful tools to streamline your data processes, enhance efficiency, and scale your growing needs.
Data Engineer Design, implement, and maintain data pipelines for dataingestion, processing, and transformation in Azure. Work together with data scientists and analysts to understand the needs for data and create effective dataworkflows.
Thanks to Monte Carlo, we can detect these issues very quickly — most of the time, even before our dataworkflow fails, so users aren’t impacted. Georvic Tur , Senior Data Engineer at Tools for Humanity, uses Performance dashboards to make sure his team’s real-time dataingestions are running correctly.
Why is data pipeline architecture important? Databricks – Databricks, the Apache Spark-as-a-service platform, has pioneered the data lakehouse, giving users the options to leverage both structured and unstructured data and offers the low-cost storage features of a data lake.
Why Should You Get an Azure Data Engineer Certification? Becoming an Azure data engineer allows you to seamlessly blend the roles of a data analyst and a data scientist. One of the pivotal responsibilities is managing dataworkflows and pipelines, a core aspect of a data engineer's role.
Data orchestration involves managing the scheduling and execution of dataworkflows. As for this part, Apache Airflow is a popular open-source platform choice used for data orchestration across the entire data pipeline.
Role Level: Intermediate Responsibilities Design and develop big data solutions using Azure services like Azure HDInsight, Azure Databricks, and Azure Data Lake Storage. Implement dataingestion, processing, and analysis pipelines for large-scale data sets.
The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization. This means that Elasticsearch can be easily integrated into different modern data stacks.
In our case, dataingestion, transformation, orchestration, reverse ETL, and observability. This is the modern data stack as we know it today. The modern data stack has become disjointed and complex, slowing data engineering’s productivity and limiting their ability to provide value to the business.
Data quality rules, or assertions, should be configurable at every processing step in every pipeline and evaluate every data record. Value Catching data problems in real-time avoids costly reruns and delays. It reduces the amount of rework arising from after-the- fact quality reviews and simplifies dataworkflows.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content