This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
Apache NiFi Apache NiFi is a commonly used open-source data integration tool for data routing, transformation, and system mediation. NiFi's user-friendly interface allows users to design complex data flows effortlessly, making it an excellent choice for dataingestion and routing tasks.
If you are willing to gain hands-on experience with Google BigQuery , you must explore the GCP Project to Learn using BigQuery for Exploring Data. Google Cloud Dataproc Dataproc is a fully-managed and scalable Spark and Hadoop Service that supports batch processing, querying, streaming, and machine learning. PREVIOUS NEXT <
Let's delve deeper into the essential responsibilities and skills of a Big Data Developer: Develop and Maintain Data Pipelines using ETL Processes Big Data Developers are responsible for designing and building data pipelines that extract, transform, and load (ETL) data from various sources into the Big Data ecosystem.
He explores their collaborative potential in orchestrating, exploring, and analyzing data, shaping a secure and comprehensive data engineering landscape. It also enables data transformation using compute services such as Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Azure Machine Learning.
From business intelligence to machine learning, Azure Databricks provides a flexible and scalable environment to tackle various data challenges. Learn the A-Z of Big Data with Hadoop with the help of industry-level end-to-end solved Hadoop projects.
Their role includes designing data pipelines, integrating data from multiple sources, and setting up databases and data lakes that can support machine learning and analytics workloads. They work with various tools and frameworks, such as Apache Spark, Hadoop , and cloud services, to manage massive amounts of data.
By working on this project, you will gain a comprehensive understanding of crucial aspects like setting up access permissions to ensure data security, establishing triggers for automated dataingestion to keep your data updated, and implementing transformation logic using Cloud Functions.
The ETL (Extract, Transform, Load) process follows four main steps: i) Connect and Collect: Connect to the data source/s and move data to local and crowdsource data storage. ii) Data transformation using computing services such as HDInsight, Hadoop , Spark, etc. Explain the data source in the Azure data factory.
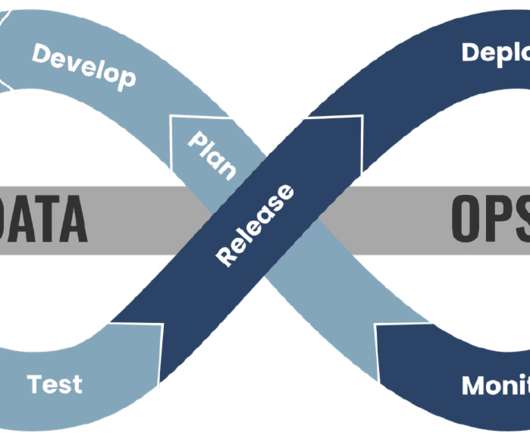
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of data processes across an organization. These tools help organizations implement DataOps practices by providing a unified platform for data teams to collaborate, share, and manage their data assets.
Top 10 Azure Data Engineering Project Ideas for Beginners For beginners looking to gain practical experience in Azure Data Engineering, here are 10 Azure Data engineer real time projects ideas that cover various aspects of data processing, storage, analysis, and visualization using Azure services: 1.
Data orchestration involves managing the scheduling and execution of dataworkflows. As for this part, Apache Airflow is a popular open-source platform choice used for data orchestration across the entire data pipeline. A simplified diagram shows the major components of Airbnb’s data infrastructure stack.
Why is data pipeline architecture important? 5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Singer – An open source tool for moving data from a source to a destination.
Why Should You Get an Azure Data Engineer Certification? Becoming an Azure data engineer allows you to seamlessly blend the roles of a data analyst and a data scientist. One of the pivotal responsibilities is managing dataworkflows and pipelines, a core aspect of a data engineer's role.
Role Level: Intermediate Responsibilities Design and develop big data solutions using Azure services like Azure HDInsight, Azure Databricks, and Azure Data Lake Storage. Implement dataingestion, processing, and analysis pipelines for large-scale data sets.
The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization. This means that Elasticsearch can be easily integrated into different modern data stacks.
phData Cloud Foundation is dedicated to machine learning and data analytics, with prebuilt stacks for a range of analytical tools, including AWS EMR, Airflow, AWS Redshift, AWS DMS, Snowflake, Databricks, Cloudera Hadoop, and more. This helps drive requirements and determines the right validation at the right time for the data.
Web Server Log Processing In this project, you'll process web server logs using a combination of Hadoop, Flume, Spark, and Hive on Azure. Starting with setting up an Azure Virtual Machine, you'll install necessary big data tools and configure Flume agents for log dataingestion.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content