This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learn tricks on importing various data formats using Pandas with a few lines of code. We will be learning to import SQL databases, Excel sheets, HTML tables, CSV, and JSON files with examples.
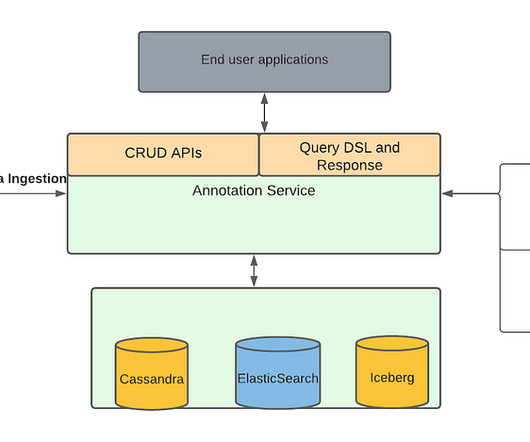
There are many naive solutions possible for this problem for example: Write different runs in different databases. Instead our challenge was to implement this feature on top of Cassandra and ElasticSearch databases because that’s what Marken uses. This is obviously very expensive. Write algo runs into files.
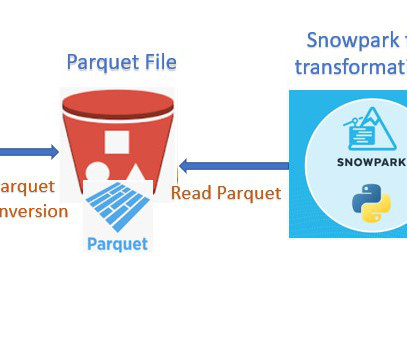
Once the final file is available inside the bucket, we have used Snowpark framework to perform the multiple steps below and ingest the final into Snowflake. Snowflake Output Happy 0 0 % Sad 0 0 % Excited 0 0 % Sleepy 0 0 % Angry 0 0 % Surprise 0 0 % The post DataIngestion with Glue and Snowpark appeared first on Cloudyard.
Cloudera Operational Database is now available in three different form-factors in Cloudera Data Platform (CDP). . If you are new to Cloudera Operational Database, see this blog post. Cloudera Operational Database (COD) experience that is is a managed dbPaaS solution. Dataingest. Tables and rows.
Every database built for real-time analytics has a fundamental limitation. When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving.
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Snowflake is launching native integrations with some of the most popular databases, including PostgreSQL and MySQL.
data access semantics that guarantee repeatable data read behavior for client applications. System Requirements Support for Structured Data The growth of NoSQL databases has broadly been accompanied with the trend of data “schemalessness” (e.g., key value stores generally allow storing any data under a key).
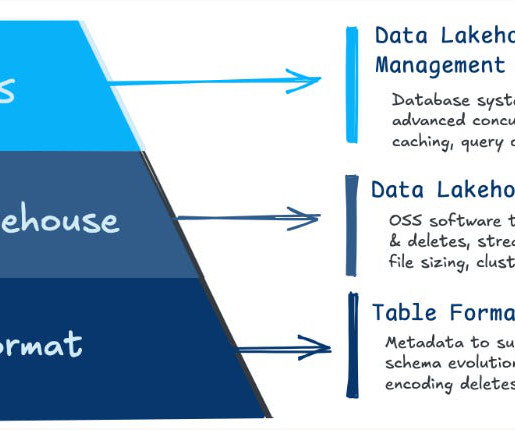
Bronze layers can also be the raw database tables. Next, data is processed in the Silver layer , which undergoes “just enough” cleaning and transformation to provide a unified, enterprise-wide view of core business entities. Data missing or incomplete at various stages is another critical quality issue in the Medallion architecture.
For machine learning applications relational models require additional processing to be directly useful, which is why there has been a growth in the use of vector databases. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
Singlestore aims to cut down on the number of database engines that you need to run so that you can reduce the amount of copying that is required. By supporting fast, in-memory row-based queries and columnar on-disk representation, it lets your transactional and analytical workloads run in the same database. In fact, while only 3.5%
Summary The database market has seen unprecedented activity in recent years, with new options addressing a variety of needs being introduced on a nearly constant basis. Despite that, there are a handful of databases that continue to be adopted due to their proven reliability and robust features. In fact, while only 3.5%
What if your data lake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data. Vinoth also stressed the need for solutions that ensure longevity and adaptability.
In the previous blog post , we looked at some of the application development concepts for the Cloudera Operational Database (COD). COD is an operational database-as-a-service that brings ease of use and flexibility to Apache HBase. Integrated across the Enterprise Data Lifecycle . Cloudera DataFlow .
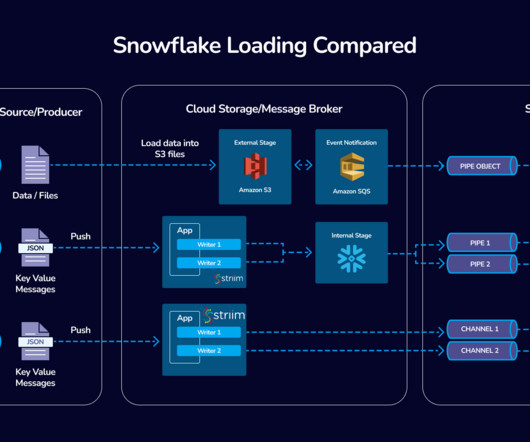
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable data pipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process. A typical dataingestion flow.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
Unify transactional and analytical workloads in Snowflake for greater simplicity Many businesses must maintain two separate databases: one to handle transactional workloads and another for analytical workloads.
Introduction Azure data factory (ADF) is a cloud-based dataingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Striim’s integration with Snowpipe Streaming represents a significant advancement in real-time dataingestion into Snowflake.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
However, as we were migrating our widecolumn database , we saw significant performance degradation across many clusters, especially for our bulk-updated workloads. For these use cases, typically datasets are generated offline in batch jobs and get bulk uploaded from S3 to the database running on EC2.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
KAWA combines analytics, automation and AI agents to help enterprises build data apps and AI workflows quickly and achieve their digital transformation goals. It connects structured and unstructured databases across sources and uses a no-code UI or Python for advanced and predictive analytics.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
Rockset is a database used for real-time search and analytics on streaming data. In scenarios involving analytics on massive data streams, we’re often asked the maximum throughput and lowest data latency Rockset can achieve and how it stacks up to other databases. Why measure streaming dataingestion?
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. One of its core products uses a single-tenant architecture, which means each client has its own database.
Elasticsearch was designed for log analytics where data is not frequently changing, posing additional challenges when dealing with transactional data. Rockset, on the other hand, is a cloud-native database, removing a lot of the tooling and overhead required to get data into the system.
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view.
We are excited to announce the availability of data pipelines replication, which is now in public preview. In the event of an outage, this powerful new capability lets you easily replicate and failover your entire dataingestion and transformations pipelines in Snowflake with minimal downtime.
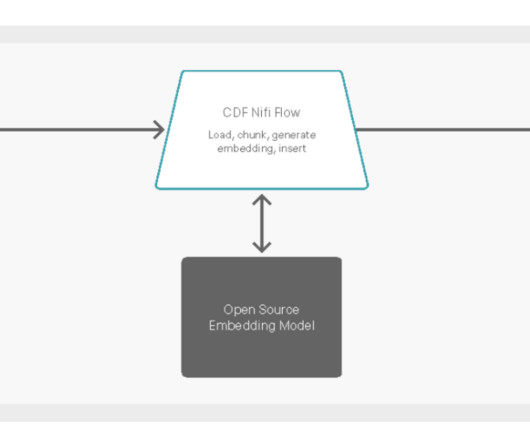
And so we are thrilled to introduce our latest applied ML prototype (AMP) — a large language model (LLM) chatbot customized with website data using Meta’s Llama2 LLM and Pinecone’s vector database. High-level overview of real-time dataingest with Cloudera DataFlow to Pinecone vector database.
Systems must be capable of handling high-velocity data without bottlenecks. Addressing these challenges demands an end-to-end approach that integrates dataingestion, streaming analytics, AI governance, and security in a cohesive pipeline. As you can see, theres a lot to consider in adopting real-time AI.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Streaming and Real-Time Data Processing As organizations increasingly demand real-time data insights, Open Table Formats offer strong support for streaming data processing, allowing organizations to seamlessly merge real-time and batch data. Amazon S3, Azure Data Lake, or Google Cloud Storage).
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
This critical step leverages dataingestion tools to interface with diverse data sources, both internal and external, using various protocols and formats. Furthermore, Striim also supports real-time data replication and real-time analytics, which are both crucial for your organization to maintain up-to-date insights.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
This is part two in Rockset’s Making Sense of Real-Time Analytics on Streaming Data series. In part 1 , we covered the technology landscape for real-time analytics on streaming data. In this post, we’ll explore the differences between real-time analytics databases and stream processing frameworks. With that, let’s dive in.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content