This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
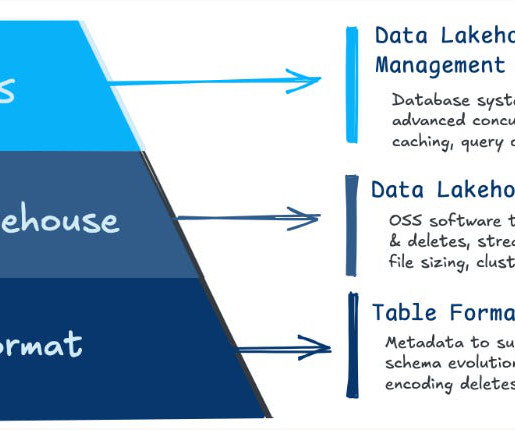
Finally, the challenge we are addressing in this document – is how to prove the data is correct at each layer.? How do you ensure data quality in every layer? The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment.
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. AvroTensorDataset speeds up data preprocessing by multiple orders of magnitude, enabling us to keep site content as fresh as possible for our members. avro", "part-00001.avro"], Default is zero.
Hudi bridges the gap between traditional databases and data lakes by enabling transactional updates, data versioning, and time travel. This hybrid approach empowers enterprises to efficiently handle massive datasets while maintaining flexibility and reducing operational overhead. Exploring Apache Hudi 1.0:
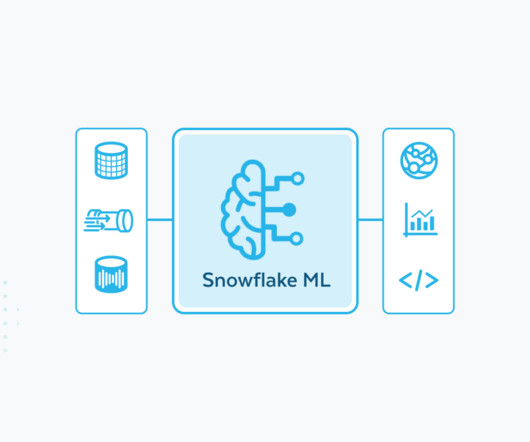
For training using default settings out of the box for Snowflake Notebooks on Container Runtime, our benchmarks show that distributed XGBoost on Snowflake is over 2x faster for tabular data compared to a managed Spark solution and a competing cloud service.
In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Like Hadoop, it aims to tackle scalability, cost, speed, and data silos.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process. A typical dataingestion flow.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
For these use cases, typically datasets are generated offline in batch jobs and get bulk uploaded from S3 to the database running on EC2. In the case during the instance migration, even though the measured network throughput was well below the baseline bandwidth, we still see TCP retransmits to spike during bulk dataingestion into EC2.
To try and predict this, an extensive dataset including anonymised details on the individual loanee and their historical credit history are included. As a machine learning problem, it is a classification task with tabular data, a perfect fit for RAPIDS. Get the Dataset. The dataset can be downloaded from: [link].
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
lower latency than Elasticsearch for streaming dataingestion. We’ll also delve under the hood of the two databases to better understand why their performance differs when it comes to search and analytics on high-velocity data streams. Why measure streaming dataingestion? Data Latency: Rockset sees up to 2.5x
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
transformers) became standardized, ML engineers started to show a growing appetite to iterate on datasets. While such dataset iterations can yield significant gains, we observed that only a handful of such experiments were conducted and productionized in the last six months. As model architecture building blocks (e.g.
Modak’s Nabu is a born in the cloud, cloud-neutral integrated data engineering platform designed to accelerate the journey of enterprises to the cloud. The platform converges data cataloging, dataingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata.
Only data platform with built-in capability to ingestdata from on-prem to the cloud. Readily Accessible DataIngestion and Analytics. Sophisticated data practitioners and business analysts want access to new datasets that can help optimize their work and transform whole business functions.
So to improve the speed of data analysis, the IRS worked with the combined technology integrating Cloudera Data Platform (CDP) and NVIDIA’s RAPIDS Accelerator for Apache Spark 3.0. The Roads and Transport Authority (RTA) operating in Dubai wanted to apply big data capabilities to transportation and enhance travel efficiency.
As we are pulling data with discrepancies together from different operational systems, the dataingestion process can be more time-consuming than originally thought! Including basic data cleaning and manual mapping as the first step can improve data consistency and alignment for more accurate results.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
Once the prototype has been completely deployed, you will have an application that is able to make predictions to classify transactions as fraudulent or not: The data for this is the widely used credit card fraud dataset. Data analysis – create a plan to build the model.
Random data doesn’t do it — and production data is not safe (or legal) for developers to use. What if you could mimic your entire production database to create a realistic dataset with zero sensitive data? Random data doesn’t do it — and production data is not safe (or legal) for developers to use.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers. The use case is fraud detection for credit card payments.
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig.
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. ® , Go, and Python SDKs where an application can use SQL to query raw data coming from Kafka through an API (but that is a topic for another blog). In addition, it is often used for smaller datasets (e.g.,
Random data doesn’t do it — and production data is not safe (or legal) for developers to use. What if you could mimic your entire production database to create a realistic dataset with zero sensitive data? Random data doesn’t do it — and production data is not safe (or legal) for developers to use.
Data testing checks for rule-based validations, while observability ensures overall pipeline health, tracking aspects like latency, freshness, and lineage. How to Evaluate a Data Observability Tool When selecting a data observability tool, assessing both functionality and how well it integrates into your existing data stack is important.
The primary objective here is to establish a metric that can effectively measure the cleanliness level of a dataset, translating this concept into a concrete optimisation problem. or HoloClean: Holistic Data Repairs with Probabilistic Inference ). Data issues should be locateable to specific cells.
Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset. ML Pipeline operations begins with dataingestion and validation, followed by transformation. You can access it from here.
Data Management A tutorial on how to use VDK to perform batch data processing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source dataingestion and processing framework designed to simplify data management complexities.
Indeed, datalakes can store all types of data including unstructured ones and we still need to be able to analyse these datasets. Indeed, why would we build a data connector from scratch if it already exists and is being managed in the cloud? You can change these # to conform to your data. Datalake example.
With Select Star’s data catalog, a single source of truth for your data is built in minutes, even across thousands of datasets. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. You’ll also get a swag package when you continue on a paid plan.
Summary Exploratory data analysis works best when the feedback loop is fast and iterative. This is easy to achieve when you are working on small datasets, but as they scale up beyond what can fit on a single machine those short iterations quickly become long and tedious. In fact, while only 3.5% That’s where our friends at Ascend.io
Twitter represents the default source for most event streaming examples, and it’s particularly useful in our case because it contains high-volume event streaming data with easily identifiable keywords that can be used to filter for relevant topics. Ingesting Twitter data. wwc : defines the BigQuery dataset name.
This use case is vital for organizations that rely on accurate data to drive business operations and strategic decisions. DataIngestion Continuous monitoring during dataingestion ensures that updates to existing data sources are accurate and consistent.
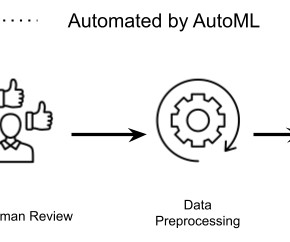
In content moderation classifier development, there are Data ETL (Export, Transform, Load) pipelines that collect data from various sources and store it in offline locations like a data lake or HDFS. Most of these steps are automated using the AutoML framework, saving data scientists’ time and reducing the risk of errors.
As a result, a single consolidated and centralized source of truth does not exist that can be leveraged to derive data lineage truth. Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources. push or pull. Today, we are operating using a pull-heavy model.
The Five Use Cases in Data Observability: Effective Data Anomaly Monitoring (#2) Introduction Ensuring the accuracy and timeliness of dataingestion is a cornerstone for maintaining the integrity of data systems. This process is critical as it ensures data quality from the onset.
Since there are numerous ways to approach this task, it encourages originality in one's approach to data analysis. Moreover, this project concept should highlight the fact that there are many interesting datasets already available on services like GCP and AWS. Source: Use Stack Overflow Data for Analytic Purposes 4.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content