This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This solution is both scalable and reliable, as we have been able to effortlessly ingest upwards of 1GB/s throughput.” Rather than streaming data from source into cloud object stores then copying it to Snowflake, data is ingested directly into a Snowflake table to reduce architectural complexity and reduce end-to-end latency.
SoFlo Solar SoFlo Solars SolarSync platform uses real-time AI data analytics and ML to transform underperforming residential solar systems into high-uptime clean energy assets, providing homeowners with savings while creating a virtual power plant network that delivers measurable value to utilities and grid operators.
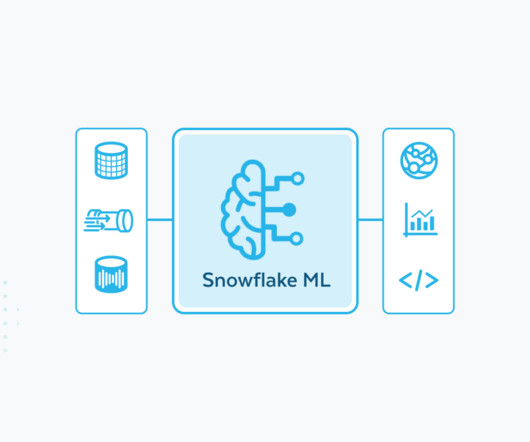
A set of CPU- and GPU-specific images, pre-installed with the latest and most popular libraries and frameworks (PyTorch, XGBoost, LightGBM, scikit-learn and many more ) supporting ML development, so data scientists can simply spin up a Snowflake Notebook and dive right into their work.
Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Delayed dataingestion : Batch processing delays insights, making real-time decision-making impossible. Start Your Free Trial | Schedule a Demo
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Systems must be capable of handling high-velocity data without bottlenecks. Addressing these challenges demands an end-to-end approach that integrates dataingestion, streaming analytics, AI governance, and security in a cohesive pipeline. Register for a demo.
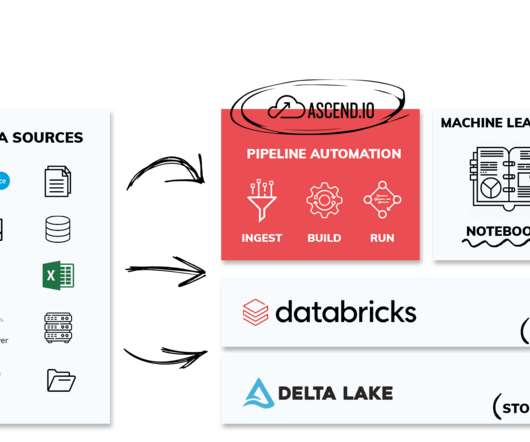
Improved Support for Databricks To highlight our improved Databricks capabilities, our re:Invent booth was next to theirs, and we chose to power our demos with their Lakehouse. More and more customers are dramatically accelerating their time to value with Databricks data pipelines by leveraging Ascend automation.
Let’s take a look at a few examples of Snowflake Native Apps that utilize Snowpark Container Services: Carto: Carto, a geospatial platform, can be deployed entirely inside Snowflake to tackle problems like vehicle routing without requiring data movement. Check out the demo. Check out the demo and sign up for the waitlist.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Data teams are increasingly under pressure to deliver. Data teams are increasingly under pressure to deliver.
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers.
Future connected vehicles will rely upon a complete data lifecycle approach to implement enterprise-level advanced analytics and machine learning enabling these advanced use cases that will ultimately lead to fully autonomous drive. In addition, join us for industry 4.0- challenges.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
As we are pulling data with discrepancies together from different operational systems, the dataingestion process can be more time-consuming than originally thought! Your program might get confused too when records come in with different names even though it means the same thing.
We’ll also provide demo code so you can try it out for yourself. Since MQTT is designed for low-power and coin-cell-operated devices, it cannot handle the ingestion of massive datasets. On the other hand, Apache Kafka may deal with high-velocity dataingestion but not M2M. Demo of Scylla and Confluent integration.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. More Data Collection Resources. Conclusion.
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a data pipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterprises in their IoT initiatives around edge management and edge data collection.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Data teams are increasingly under pressure to deliver. Data teams are increasingly under pressure to deliver.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Cloudera Flow Management (CFM) is a no-code dataingestion and management solution powered by Apache NiFi. With a slick user interface, 300+ processors and the NiFi Registry, CFM delivers highly scalable data management and DevOps capabilities to the enterprise. NiFi can handle all types of data across any type of data source.
Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline. By efficiently handling dataingestion, this component sets the stage for effective data processing and analysis.
To highlight these new capabilities, we built a search demo using OpenAI to create embeddings for Amazon product descriptions and Rockset to generate relevant search results. In the demo, you’ll see how Rockset delivers search results in 15 milliseconds over thousands of documents.
Data observability works with your data pipeline by providing insights into how your data flows and is processed from start to end. Here is a more detailed explanation of how data observability works within the data pipeline: Dataingestion : Observability begins from the point where data is ingested into the pipeline.
Second, CML seamlessly integrates with the rest of the Cloudera Data Platform to provide end-to-end ML workflows. CML can leverage experiences in the earlier stages, such as dataingestion and data engineering, to fully automate data collection, cleansing and transformation before the prediction (ML) stage begins. .
The workflow—from dataingestion and model training to model deployment—is meticulously defined within a YAML configuration file. Like AMPs, Spaces are ML demo applications that are self-contained and instantly ready to deliver value upon deployment.
I have used Colab for this demo, as it is much easier (and faster) to configure the environment. ML Pipeline operations begins with dataingestion and validation, followed by transformation. The transformed data is trained and deployed. . Have a look at this article to gain better understanding of this article.
Over the last few weeks, I delivered four live NiFi demo sessions, showing how to use NiFi connectors and processors to connect to various systems, with 1000 attendees in different geographic regions. Interactive demo sessions and live Q&A are what we all need these days when working remotely from home is now a norm.
21, 2022 – Ascend.io , The Data Automation Cloud, today announced they have partnered with Snowflake , the Data Cloud company, to launch Free Ingest , a new feature that will reduce an enterprise’s dataingest cost and deliver data products up to 7x faster by ingestingdata from all sources into the Snowflake Data Cloud quickly and easily.
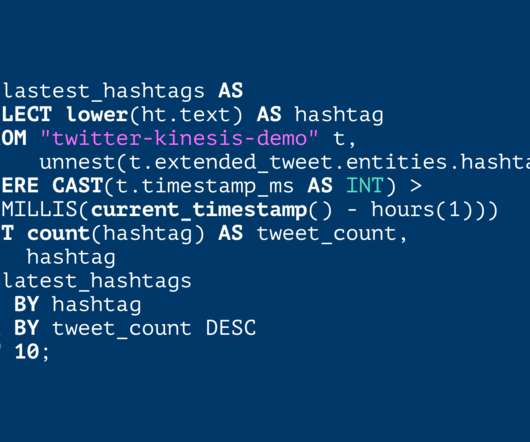
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. Because Rockset continuously syncs data from Kafka, new tweets can show up in the real-time dashboard in a matter of seconds, giving users an up-to-date view of what’s going on in Twitter.
In this blog, I will show how Rockset can serve a live dashboard, which surfaces analytics on real-time Twitter dataingested into Rockset from a Kinesis stream. We obtain data points for the number of incoming tweets every 2 seconds and plot them in a chart. This can also be achieved through the AWS Console or the AWS CLI.
Data freshness best practices Once you have talked with your key data consumers and determined your data freshness goals or SLAs, there are a few best practices you can leverage to provide the best service or data product possible. Fill out the form below to schedule a demo!
Set up the demo environment. The intention of Dynamic Tables is to apply incremental transformations on near real-time dataingestion that Snowflake now supports with Snowpipe Streaming. Dynamic Tables support the same SQL join behavior, and we will illustrate this join behavior with the following sample code: 1.
Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Apache Spark, Trino, Flink, Presto, and Hive to safely work with the same tables, at the same time. Snowflake is going to be your unified platform for developing data applications from code to monetization. That story?
Real-Time DataIngestion Striim seamlessly ingestsdata from various sources and streams it directly into Snowflake in real time. This continuous data flow guarantees that the most up-to-date, accurate information is always available for immediate analysis. Here’s how.
Data management becomes increasingly manual, creating elongated data pipelines, delayed analytics, and greater potential for error. Snowflake is helping transform the asset servicing workflow with its modernizing technology and data management capabilities, streamlining dataingestion and data sharing.
Data readiness – These set of metrics help you measure if your organization is geared up to handle the sheer volume, variety and velocity of IoT data. It is meant for you to assess if you have thought through processes such as continuous dataingestion, enterprise data integration and data governance.
Due to the high storage cost in the legacy EDW solution, 100% source data capture proved cost-prohibitive – this led to continuing and costly change cycles to load incremental source updates as business requirements changed. To learn more about CDP & the Smart Data Transition Toolkit: . Demo Video. Solution brief.
The workflow—from dataingestion and model training to model deployment—is meticulously defined within a YAML configuration file. Like AMPs, Spaces are ML demo applications that are self-contained and instantly ready to deliver value upon deployment.
CDSW gives data scientists the freedom to use their favorite open source and other vendor tools and libraries for the end-to-end ML workflow in addition to secure, self-service access to corporate data and distributed computing power, all managed efficiently and securely by IT. Stay tuned. Register today!
Data Operating System: Orchestrating a Unified Data Ecosystem A data operating system is an advanced data management platform that unifies data storage, integration, processing, and analytics. It provides a flexible, scalable, and secure data infrastructure that can adapt to evolving business needs.
Data Operating System: Orchestrating a Unified Data Ecosystem A data operating system is an advanced data management platform that unifies data storage, integration, processing, and analytics. It provides a flexible, scalable, and secure data infrastructure that can adapt to evolving business needs.
Data Operating System: Orchestrating a Unified Data Ecosystem A data operating system is an advanced data management platform that unifies data storage, integration, processing, and analytics. It provides a flexible, scalable, and secure data infrastructure that can adapt to evolving business needs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content