This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
With Snowpipe for Apache Kafka (public preview soon in AWS and Microsoft Azure), a “pull” mechanism, rather than the existing “push” connector, allows you to extract and ingest Apache Kafka events into your Snowflake account directly without hosting your own Kafka Connect cluster.
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Sign up free at dataengineeringpodcast.com/rudder Data teams are increasingly under pressure to deliver. In fact, while only 3.5%
During a recent talk titled Hunters ATT&CKing with the Right Data , which I presented with my brother Jose Luis Rodriguez at ATT&CKcon, we talked about the importance of documenting and modeling security event logs before developing any data analytics while preparing for a threat hunting engagement. Why KSQL and HELK?
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
WAP [Write-Audit-Publish] Pattern The WAP pattern follows a three-step process Write Phase The write phase results from a dataingestion or data transformation step. In the 'Write' stage, we capture the computed data in a log or a staging area. Event Routers typically don’t alter the payload.
Snowpark Updates Model management with the Snowpark Model Registry – public preview Snowpark Model Registry is an integrated solution to register, manage and use models and their metadata natively in Snowflake. As a result, you should not rely on any forward-looking statements as predictions of future events. Learn more here.
It also becomes the role of the data engineering team to be a “center of excellence” through the definitions of standards, best practices and certification processes for data objects. In a fast growing, rapidly evolving, slightly chaotic data ecosystem, metadata management and tooling become a vital component of a modern data platform.
Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources. Our dataingestion approach, in a nutshell, is classified broadly into two buckets?—?push We leverage Metacat data, our internal metadata store and service, to enrich lineage data with additional table metadata.
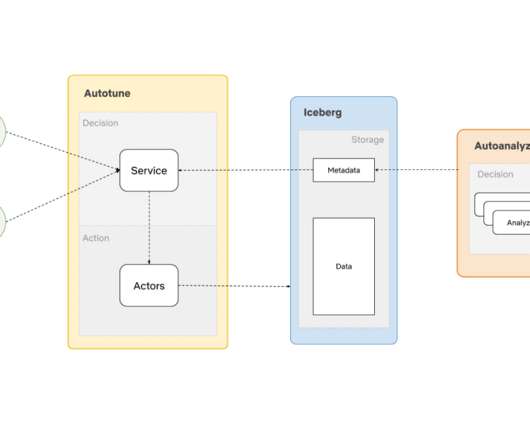
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. Sometimes Data Engineers write downstream ETLs on ingesteddata to optimize the data/metadata layouts to make other ETL processes cheaper and faster.
Faster dataingestion: streaming ingestion pipelines. The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities. Handle late-arriving data: How does my application detect and deal with streaming events that come out of order?
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
Application programming interfaces (APIs) are used to modify the retrieved data set for integration and to support users in keeping track of all the jobs. Users can schedule ETL jobs, and they can also choose the events that will trigger them. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog.
The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months.
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern data warehouse solution, one that balances speed with platform cost management, performance, and reliability.
’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event. By offering real-time tracking mechanisms and sending targeted alerts to specific consumers, a Payload DJ can immediately notify them of any changes, delays, or issues affecting their data.
A true enterprise-grade integration solution calls for source and target connectors that can accommodate: VSAM files COBOL copybooks open standards like JSON modern platforms like Amazon Web Services ( AWS ), Confluent , Databricks , or Snowflake Questions to ask each vendor: Which enterprise data sources and targets do you support?
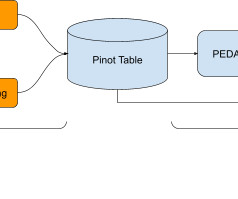
Less stringent privacy baselines have been proposed in the literature, such as event-level privacy which would consider the privacy of each new view in our setting. Pinot is a columnar OLAP store that serves analytics queries on dataingested from realtime streams.
That’s why, in addition to integrating with your central data warehouse , lake , and lakehouse , Monte Carlo also integrates with transformation , orchestration , and now dataingestion tools. Now teams can instantly get full visibility into how these systems may be impacting their data assets, all in a single pane of glass.
Running on CDW is fully integrated with streaming, data engineering, and machine learning analytics. It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. Smart DwH Mover helps in accelerating data warehouse migration.
Data observability works with your data pipeline by providing insights into how your data flows and is processed from start to end. Here is a more detailed explanation of how data observability works within the data pipeline: Dataingestion : Observability begins from the point where data is ingested into the pipeline.
Data Service – is a group of Data Flows. At this level, users configure team members, connections to other systems, and event notifications. Data Flow – is an individual data pipeline. Data Flows include the ingestion of raw data, transformation via SQL and python, and sharing of finished data products.
Data Service – is a group of Data Flows. At this level, users configure team members, connections to other systems, and event notifications. Data Flow – is an individual data pipeline. Data Flows include the ingestion of raw data, transformation via SQL and python, and sharing of finished data products.
Giannis is a proud alumnus of Rock the JVM, working as a Solutions Architect with a focus on Event Streaming and Stream Processing Systems. Introduction Apache Kafka is a well-known event streaming platform used in many organizations worldwide. The producer will send some events to Kafka. EVENTS_TOPIC , event.
Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment. then you are on the right page.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Virtual Reality – The Next Frontier in Media I work as a Data Engineer at a leading company in the VR space, with a mission to capture and transmit reality in perfect fidelity. Our content varies from on-demand experiences to live events like NBA games, comedy shows and music concerts.
In the contemporary data landscape, data teams commonly utilize data warehouses or lakes to arrange their data into L1, L2, and L3 layers. This existing paradigm fails to address the challenges and intricacies of “Data in Use.” ” For example, these tools may offer metadata-based notifications.
Cross-Cloud Snowgrid Account Replication expands replication beyond databases – general availability Account Replication, now generally available, expands replication beyond databases to account metadata and integrations, making business continuity truly turnkey. Visit our documentation page to learn more. Learn more.
Data Engineering Project for Beginners If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of data engineering project examples below. This big data project discusses IoT architecture with a sample use case.
Compute Plane: Processes data against serverless or classic compute resources. Workspace Storage Account: System data, notebooks, and logs are stored here. This storage account contains files and metadata associated with user workspaces, notebooks, and logs. It provides data versioning and transaction support.
3EJHjvm Once a business need is defined and a minimal viable product ( MVP ) is scoped, the data management phase begins with: Dataingestion: Data is acquired, cleansed, and curated before it is transformed. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
First, CDC theoretically allows companies to analyze and react to data in real time, as it’s generated. It works with existing streaming systems like Apache Kafka, Amazon Kinesis, and Azure Events Hubs, making it easier than ever to build a real-time data pipeline.
Tools and platforms for unstructured data management Unstructured data collection Unstructured data collection presents unique challenges due to the information’s sheer volume, variety, and complexity. The process requires extracting data from diverse sources, typically via APIs. Invest in data governance.
It serves as a distributed processing engine for both categories of data streams: unbounded and bounded. Support for stream and batch processing, comprehensive state management, event-time processing semantics, and consistency guarantee for the state are just a few of Flink's capabilities.
Analysis of logs, metrics, and security events. With Elasticsearch, you can aggregate and analyze large streams of logs, metrics, and security events in near real-time, making it indispensable for system monitoring and security information and event management (SIEM). Real-time behavior modeling with ML.
Moreover, over 20 percent of surveyed companies were found to be utilizing 1,000 or more data sources to provide data to analytics systems. These sources commonly include databases, SaaS products, and event streams. Databases store key information that powers a company’s product, such as user data and product data.
Read our article on Hotel Data Management to have a full picture of what information can be collected to boost revenue and customer satisfaction in hospitality. While all three are about data acquisition, they have distinct differences. They dictate how data is gathered, stored, and processed and who has access to what content.
Why is data pipeline architecture important? Databricks – Databricks, the Apache Spark-as-a-service platform, has pioneered the data lakehouse, giving users the options to leverage both structured and unstructured data and offers the low-cost storage features of a data lake.
We’ll cover: What is a data platform? Databricks – Databricks, the Apache Spark-as-a-service platform, has pioneered the data lakehouse, giving users the options to leverage both structured and unstructured data and offers the low-cost storage features of a data lake.
StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. To define the columns, PySpark offers the pyspark.sql.types import StructField class, which has the column name (String), column type (DataType), nullable column (Boolean), and metadata (MetaData).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content