This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
Trains are an excellent source of streaming data—their movements around the network are an unbounded series of events. Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. As with any real system, the data has “character.”
As Marriott’s business has grown over the past century, its data infrastructure has become more complex. In 2019, the company embarked on a mission to modernize and simplify its data platform. Prior to 2019, Marriott was an early adopter of Netezza and Hadoop, leveraging the IBM BigInsights platform.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a data warehouse at the center. What is Hadoop? This is not.
The customer also wanted to utilize the new features in CDP PvC Base like Apache Ranger for dynamic policies, Apache Atlas for lineage, comprehensive Kafka streaming services and Hive 3 features that are not available in legacy CDH versions. Lineage and chain of custody, advanced data discovery and business glossary. Kafka, SRM, SMM.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. The company migrated from its outdated Teradata appliance to the Snowflake AI Data Cloud to resolve performance issues and meet growing data demands.
Depending on how you measure it, the answer will be 11 million newspaper pages or… just one Hadoop cluster and one tech specialist who can move 4 terabytes of textual data to a new location in 24 hours. The Hadoop toy. So the first secret to Hadoop’s success seems clear — it’s cute. What is Hadoop?
Use Case 1: NiFi pulling data from Kafka and pushing it to a file system (like HDFS). The Kafka coordinator, for the specified Consumer Group ID, will rebalance the existing topic partitions across the consumers from both HDF and CFM clusters. There should be no dataingested in HDF, only CFM.
These platforms represent far more than just “Hadoop” . Over time, additional use cases and functions expanded from original EDW and Data Lake related functions to support increasing demands from the business. Streaming data analytics. . Data science & engineering. The only constant is change, however.
With the help of ProjectPro’s Hadoop Instructors, we have put together a detailed list of big dataHadoop interview questions based on the different components of the Hadoop Ecosystem such as MapReduce, Hive, HBase, Pig, YARN, Flume, Sqoop , HDFS, etc. What is the difference between Hadoop and Traditional RDBMS?
Big Data analytics encompasses the processes of collecting, processing, filtering/cleansing, and analyzing extensive datasets so that organizations can use them to develop, grow, and produce better products. Big Data analytics processes and tools. Dataingestion. Apache Hadoop. Hadoop architecture layers.
As the demand for data engineers grows, having a well-written resume that stands out from the crowd is critical. Azure data engineers are essential in the design, implementation, and upkeep of cloud-based data solutions. It is also crucial to have experience with dataingestion and transformation.
With event-driven architectures powered by systems like Apache Kafka becoming more prominent, there are now many applications in the modern software stack that make use of events and messages to operate effectively. Types of Event Data Applications emit events that correspond to important actions or state changes in their context.
Data Engineering Project for Beginners If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of data engineering project examples below. This big data project discusses IoT architecture with a sample use case.
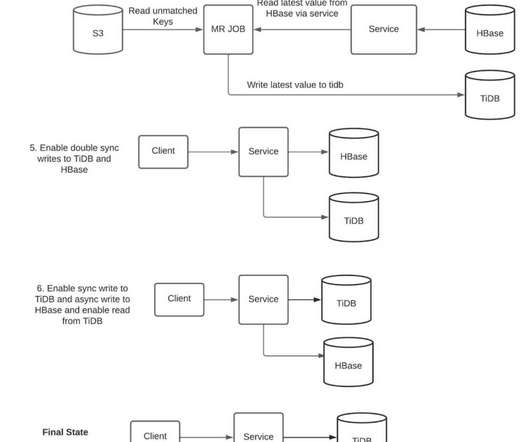
The HBase Ecosystem, though having various advantages like strong consistency at row level in high volume requests, flexible schema, low latency access to data, Hadoop integration, etc. In this blog post, we will first learn the various approaches considered for data migration with their trade offs.
Top 10 Azure Data Engineering Project Ideas for Beginners For beginners looking to gain practical experience in Azure Data Engineering, here are 10 Azure Data engineer real time projects ideas that cover various aspects of data processing, storage, analysis, and visualization using Azure services: 1.
Big Data Large volumes of structured or unstructured data. Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse.
Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
However, you can also pull data from centralized data sources like data warehouses to transform data further and build ETL pipelines for training and evaluating AI agents. Processing: It is a data pipeline component that decides the data flow implementation.
These languages are used to write efficient, maintainable code and create scripts for automation and data processing. Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%).
These languages are used to write efficient, maintainable code and create scripts for automation and data processing. Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%).
Hortonworks Data Engineering Certification The HDP Certified Developer (HDPCD) certification is another popular data engineering certification you can earn to build a successful career in this domain. Cloudera: You can take a Spark and Hadoop training course the platform provides. Candidates must register on www.examslocal.com.
We continuously hear data professionals describe the advantage of the Snowflake platform as “it just works.” Snowpipe and other features makes Snowflake’s inclusion in this top data lake vendors list a no-brainer. Not to mention seamless integration with the Oracle ecosystem.
Why is data pipeline architecture important? 5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Singer – An open source tool for moving data from a source to a destination.
DataFrames are used by Spark SQL to accommodate structured and semi-structured data. Apache Spark is also quite versatile, and it can run on a standalone cluster mode or Hadoop YARN , EC2, Mesos, Kubernetes, etc. CMAK is developed to help the Kafka community. To learn more about the recent updates and contribute: [link] 8.
Examples of unstructured data can range from sensor data in the industrial Internet of Things (IoT) applications, videos and audio streams, images, and social media content like tweets or Facebook posts. DataingestionDataingestion is the process of importing data into the data lake from various sources.
Features of Spark Speed : According to Apache, Spark can run applications on Hadoop cluster up to 100 times faster in memory and up to 10 times faster on disk. Spark streaming also has in-built connectors for Apache Kafka which comes very handy while developing Streaming applications. Spark streaming also supports Structure Streaming.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Born out of the minds behind Apache Spark, an open-source distributed computing framework, Databricks is designed to simplify and accelerate data processing, data engineering, machine learning, and collaborative analytics tasks. This flexibility allows organizations to ingestdata from virtually anywhere.
MapReduce Apache Spark Only batch-wise data processing is done using MapReduce. Apache Spark can handle data in both real-time and batch mode. The data is stored in HDFS (Hadoop Distributed File System), which takes a long time to retrieve. You can learn a lot by utilizing PySpark for data intake processes.
Role Level: Intermediate Responsibilities Design and develop big data solutions using Azure services like Azure HDInsight, Azure Databricks, and Azure Data Lake Storage. Implement dataingestion, processing, and analysis pipelines for large-scale data sets.
This remarkable efficiency is a game-changer compared to traditional batch processing engines like Hadoop , enabling real-time analytics and insights. With native integrations for major cloud platforms like AWS, Azure, and Google Cloud, sending data to Elastic Cloud is straightforward.
In years past, some companies may have tried to create this report within Excel, having multiple business analysts and engineers contribute to data extraction and manipulation. Once the data has been collected from each system, a data engineer can determine how to optimally join the data sets.
phData Cloud Foundation is dedicated to machine learning and data analytics, with prebuilt stacks for a range of analytical tools, including AWS EMR, Airflow, AWS Redshift, AWS DMS, Snowflake, Databricks, Cloudera Hadoop, and more. The way you validate your data will be greatly influenced by your situation and architecture.
The Apache Hadoop open source big data project ecosystem with tools such as Pig, Impala, Hive, Spark, Kafka Oozie, and HDFS can be used for storage and processing. Big Data Project using Hadoop with Source Code for Web Server Log Processing 5.
Additionally, this modularity can help prevent vendor lock-in, giving organizations more flexibility and control over their data stack. Many components of a modern data stack (such as Apache Airflow, Kafka, Spark, and others) are open-source and free. Offered as open-source with active support by communities.
Explosion in Streaming Data Before Kafka, Spark and Flink, streaming came in two flavors: Business Event Processing (BEP) and Complex Event Processing (CEP). Many (Kafka, Spark and Flink) were open source. It also prevents data bloat that would hamper storage efficiency and query speeds.
Databricks architecture Databricks provides an ecosystem of tools and services covering the entire analytics process — from dataingestion to training and deploying machine learning models. Besides that, it’s fully compatible with various dataingestion and ETL tools. Let’s see what exactly Databricks has to offer.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content