This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Looking for the ultimate guide on mastering Apache Kafka in 2024? The ultimate hands-on learning guide with secrets on how you can learn Kafka by doing. Discover the key resources to help you master the art of real-time data streaming and building robust data pipelines with Apache Kafka. Here it is!
If you’re looking for everything a beginner needs to know about using Apache Kafka for real-time data streaming, you’ve come to the right place. This blog post explores the basics about Apache Kafka and its uses, the benefits of utilizing real-time data streaming, and how to set up your data pipeline.
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? Kafka Stream vs. Spark Streaming What is Spark streaming? Table of Contents What is Spark streaming?
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. Project Idea : Build a data pipeline to ingestdata from APIs like CoinGecko or Kaggle’s crypto datasets.
Ace your Big Data engineer interview by working on unique end-to-end solved Big Data Projects using Hadoop Prerequisites to Become a Big Data Developer Certain prerequisites to becoming a successful big data developer include a strong foundation in computer science and programming, encompassing languages such as Java, Python , or Scala.
The core engine for large-scale distributed and parallel data processing is SparkCore. The distributed execution engine in the Spark core provides APIs in Java, Python, and Scala for constructing distributed ETL applications. The cache() function or the persist() method with proper persistence settings can be used to cache data.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
It even allows you to build a program that defines the data pipeline using open-source Beam SDKs (Software Development Kits) in any three programming languages: Java, Python, and Go. CMAK Source: Github CMAK stands for Cluster Manager for Apache Kafka , previously known as Kafka Manager, is a tool for managing Apache Kafka clusters.
With the ability to handle streaming dataingestion rates of up to millions of events per second, Amazon Kinesis has become a popular choice for high-volume data processing applications. Ready to take your data streaming to the next level? For Kinesis Firehose, AWS charges based on the amount of dataingested.
Source: N ifi.apache.org Apache NiFi is an open-source data integration tool designed to seamlessly and intuitively manage, automate, and distribute data flows. This powerful platform addresses the challenges of dataingestion, distribution, and transformation across diverse systems. What is NiFi vs Kafka?
Data scientists can then leverage different Big Data tools to analyze the information. Data scientists and engineers typically use the ETL (Extract, Transform, and Load) tools for dataingestion and pipeline creation. It has built-in machine learning algorithms, SQL, and data streaming modules.
Responsibilities of a Data Engineer When you make a career transition from an ETL developer to a data engineer, your day-to-day responsibilities are likely to be a lot more than before. Organize and gather data from various sources following business needs. Python, HTML, CSS, Java, etc.,
AWS Projects For Data Engineers Orchestrate Redshift ETL using AWS Glue and Step Functions Building Real-Time AWS Log Analytics Solution 2. Azure Projects For Data Engineers Learn Real-Time DataIngestion with Azure Purview Analyse Yelp Dataset with Spark & Parquet Format on Azure Databricks 3. PREVIOUS NEXT <
You can use your AWS account to analyze Twitter sentiments in real time by leveraging Apache NiFi, Kafka, and Spark on AWS EC2. This project guides you through dataingestion, stream processing, sentiment classification, and live visualization using Python Plotly and Dash. Github link- Hybrid Recommendation System 29.
To address this challenge, we are happy to announce the public preview of Snowpipe Streaming as the latest addition to our Snowflake ingestion offerings. As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. How does Snowpipe Streaming work?
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Jeff Xiang | Software Engineer, Logging Platform Vahid Hashemian | Software Engineer, Logging Platform Jesus Zuniga | Software Engineer, Logging Platform At Pinterest, data is ingested and transported at petabyte scale every day, bringing inspiration for our users to create a life they love.
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
Introduction Apache Kafka is a well-known event streaming platform used in many organizations worldwide. It is used as the backbone of many data infrastructures, thus it’s important to understand how to use it efficiently. The code samples are written in Kotlin, but the implementation should be easy to port in Java or Scala.
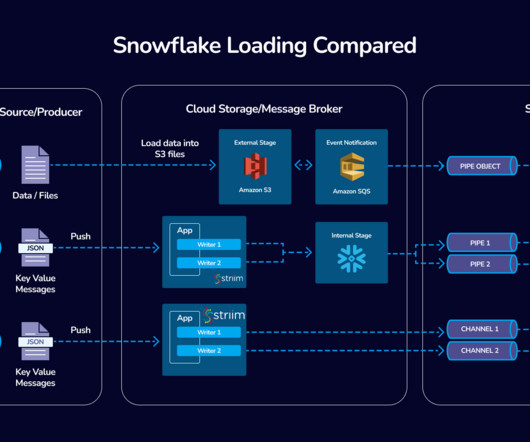
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Striim’s integration with Snowpipe Streaming represents a significant advancement in real-time dataingestion into Snowflake.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
The developers must understand lower-level languages like Java and Scala and be familiar with the streaming APIs. A modern streaming architecture consists of critical components that provide dataingestion, security and governance, and real-time analytics. What is modern streaming architecture?
To enable the ingestion and real-time processing of enormous volumes of data, LinkedIn built a custom stream processing ecosystem largely with tools developed in-house (and subsequently open-sourced). In 2010, they introduced Apache Kafka , a pivotal Big Dataingestion backbone for LinkedIn’s real-time infrastructure.
In this blog, we’ll compare and contrast how Elasticsearch and Rockset handle dataingestion as well as provide practical techniques for using these systems for real-time analytics. Or, they can periodically scan their relational database to get access to the most up to date records and reindex the data in Elasticsearch.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
The Rise of the Data Engineer The Downfall of the Data Engineer Functional Data Engineering — a modern paradigm for batch data processing There is a global consensus stating that you need to master a programming language (Python or Java based) and SQL in order to be self-sufficient. This is not.
If you are a database administrator or developer, you can start writing queries right-away using Apache Phoenix without having to wrangle Java code. . To store and access data in the operational database, you can do one of the following: Use native Apache HBase client APIs to interact with data in HBase: Use the HBase APIs for Java.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
MiNiFi comes in two versions: C++ and Java. The MiNiFi Java option is a lightweight single node instance, a headless version of NiFi without the user interface nor the clustering capabilities. Still, it requires Java to be available on the host. Still, it requires Java to be available on the host.
In a previous blog of this series, Turning Streams Into Data Products , we talked about the increased need for reducing the latency between data generation/ingestion and producing analytical results and insights from this data. The use case. The streaming SQL job also saves the fraud detections to the Kudu database.
HELK is a free threat hunting platform built on various components including the Elastic stack, Apache Kafka ® and Apache Spark. WHERE PARENT_PROCESS_PATH LIKE '%WmiPrvSE.exe%'; The results of the KSQL query can be written to a Kafka topic, which in turn can drive real-time monitoring or alerting dashboards and applications.
3EJHjvm Once a business need is defined and a minimal viable product ( MVP ) is scoped, the data management phase begins with: Dataingestion: Data is acquired, cleansed, and curated before it is transformed. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? Kafka Stream vs. Spark Streaming What is Spark streaming? Table of Contents What is Spark streaming?
Why Striim Stands Out As detailed in the GigaOm Radar Report, Striim’s unified data integration and streaming service platform excels due to its distributed, in-memory architecture that extensively utilizes SQL for essential operations such as transforming, filtering, enriching, and aggregating data.
That’s why we built Snowpipe Streaming, now generally available to handle row-set dataingestion. The new Kafka connector, built with Snowpipe Streaming , now supports schema detection and evolution. Snowpipe streaming supports both database replication and group-based replication. Learn more here.
Data Engineering Project for Beginners If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of data engineering project examples below. This big data project discusses IoT architecture with a sample use case.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Top 10 Azure Data Engineering Project Ideas for Beginners For beginners looking to gain practical experience in Azure Data Engineering, here are 10 Azure Data engineer real time projects ideas that cover various aspects of data processing, storage, analysis, and visualization using Azure services: 1.
Databricks architecture Databricks provides an ecosystem of tools and services covering the entire analytics process — from dataingestion to training and deploying machine learning models. Besides that, it’s fully compatible with various dataingestion and ETL tools. Let’s see what exactly Databricks has to offer.
Here are some essential skills for data engineers when working with data engineering tools. Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content