This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
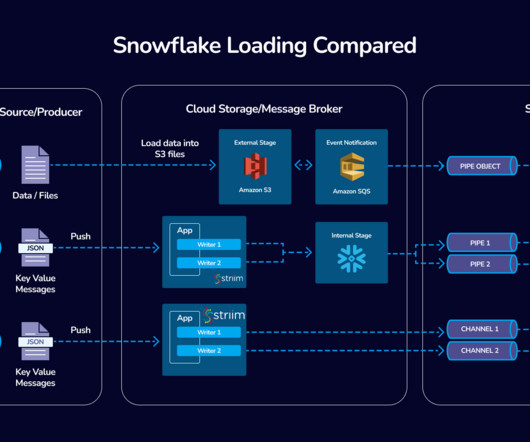
To address this challenge, we are happy to announce the public preview of Snowpipe Streaming as the latest addition to our Snowflake ingestion offerings. As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. How does Snowpipe Streaming work?
Every developer who uses Apache Kafka ® has used a Kafka consumer at least once. Although it is the simplest way to subscribe to and access events from Kafka, behind the scenes, Kafka consumers handle tricky distributed systems challenges like data consistency, failover and load balancing. Consistency.
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js
Welcome to the third blog post in our series highlighting Snowflake’s dataingestion capabilities, covering the latest on Snowpipe Streaming (currently in public preview) and how streaming ingestion can accelerate data engineering on Snowflake. What is Snowpipe Streaming?
Ingestdata more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
A key challenge, however, is integrating devices and machines to process the data in real time and at scale. Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. Example: Severstal.
Trains are an excellent source of streaming data—their movements around the network are an unbounded series of events. Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. As with any real system, the data has “character.”
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
There is a class of applications that cannot afford to be unavailable—for example, external-facing entry points into your organization. Typically, anything your customers interact with directly cannot go down. As […].
I can now begin drafting my dataingestion/ streaming pipeline without being overwhelmed. Kafka, while not in the top 5 most in demand skills, was still the most requested buffer technology requested which makes it worthwhile to include it. I'll use Python and Spark because they are the top 2 requested skills in Toronto.
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Striim’s integration with Snowpipe Streaming represents a significant advancement in real-time dataingestion into Snowflake.
Welcome back to this Toronto Specific data engineering project. We left off last time concluding finance has the largest demand for data engineers who have skills with AWS, and sketched out what our dataingestion pipeline will look like. I began building out the dataingestion pipeline by launching an EC2 instance.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
Introduction Apache Kafka is a well-known event streaming platform used in many organizations worldwide. It is used as the backbone of many data infrastructures, thus it’s important to understand how to use it efficiently. Environment Setup First, we want to have a Kafka Cluster up and running. Enter Giannis: 1. version: "3.7"
To find out, we decided to test the streaming ingestion performance of Rockset’s next generation cloud architecture and compare it to open-source search engine Elasticsearch , a popular sink for Apache Kafka. For this benchmark, we evaluated Rockset and Elasticsearch ingestion performance on throughput and data latency.
The customer also wanted to utilize the new features in CDP PvC Base like Apache Ranger for dynamic policies, Apache Atlas for lineage, comprehensive Kafka streaming services and Hive 3 features that are not available in legacy CDH versions. Lineage and chain of custody, advanced data discovery and business glossary. Kafka, SRM, SMM.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. STEP 4: Capture data from Apache Kafka streams.
Jeff Xiang | Software Engineer, Logging Platform Vahid Hashemian | Software Engineer, Logging Platform Jesus Zuniga | Software Engineer, Logging Platform At Pinterest, data is ingested and transported at petabyte scale every day, bringing inspiration for our users to create a life they love.
In this blog, we’ll compare and contrast how Elasticsearch and Rockset handle dataingestion as well as provide practical techniques for using these systems for real-time analytics. Or, they can periodically scan their relational database to get access to the most up to date records and reindex the data in Elasticsearch.
WAP [Write-Audit-Publish] Pattern The WAP pattern follows a three-step process Write Phase The write phase results from a dataingestion or data transformation step. In the 'Write' stage, we capture the computed data in a log or a staging area. The Fronting Kafka pattern follows a two-cluster approach.
At the front end, you’ve got your dataingestion layer —the workhorse that pulls in data from everywhere it lives. The beauty of modern ingestion tools is their flexibility—you can handle everything from old-school CSV files to real-time streams using platforms like Kafka or Kinesis.
In light of this, we’ll share an emerging machine-to-machine (M2M) architecture pattern in which MQTT, Apache Kafka ® , and Scylla all work together to provide an end-to-end IoT solution. Sensors generate data points while actuators are mechanical components that may be controlled through commands. What is Apache Kafka?
A modern streaming architecture consists of critical components that provide dataingestion, security and governance, and real-time analytics. The three fundamental parts of the architecture are: Dataingestion that acquires the data from different streaming sources and orchestrates and augments the data from other sources.
Modern applications often provide streaming interfaces to send transaction data in real-time to external systems for analysis. Apache Kafka deployments are commonly used to buffer these messages for downstream consumption. DataIngest for Microsoft Sentinel .
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern data warehouse solution, one that balances speed with platform cost management, performance, and reliability.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. Snowflake's separate clusters for ETL, reporting and data science eliminated resource contention.
To enable the ingestion and real-time processing of enormous volumes of data, LinkedIn built a custom stream processing ecosystem largely with tools developed in-house (and subsequently open-sourced). In 2010, they introduced Apache Kafka , a pivotal Big Dataingestion backbone for LinkedIn’s real-time infrastructure.
Use Case 1: NiFi pulling data from Kafka and pushing it to a file system (like HDFS). The Kafka coordinator, for the specified Consumer Group ID, will rebalance the existing topic partitions across the consumers from both HDF and CFM clusters. There should be no dataingested in HDF, only CFM.
We think that this is a good validation of our data-in-motion philosophy that a streaming architecture is made up of needs across dataingestion , messaging and analytics and in our case, this is powered by Apache NiFi, Apache Kafka and Apache Flink.
Dataingestion pipeline with Operation Management — At Netflix they annotate video which can lead to thousand of annotation but they need to manage the annotation lifecycle each time the annotation algorithm runs. Not related, they also announced Snowpipe Streaming this week. This article explains how they did it.
Snowflake simplifies dataingestion by consolidating batch and streaming, increasing Marriott’s speed to market—as soon as a customer transaction occurs, the data is available for consumption. With Snowflake’s Kafka connector, the technology team can ingest tokenized data as JSON into tables as VARIANT.
Cloudera DataFlow (CDF) is a scalable, real-time streaming data platform that collects, curates, and analyzes data so customers gain key insights for immediate actionable intelligence. CDF, as an end-to-end streaming data platform, emerges as a clear solution for managing data from the edge all the way to the enterprise.
CDC enables true real-time analytics on your application data, assuming the platform you send the data to can consume the events in real time. Options For Change Data Capture on MongoDB Apache Kafka The native CDC architecture for capturing change events in MongoDB uses Apache Kafka.
Faster, easier ingest To make dataingestion even more cost effective and effortless, Snowflake is announcing performance improvements of up to 25% for loading JSON files, and for loading Parquet files, up to 50%. With this launch, Snowflake is providing more native connectors to allow you to bring data in more easily.
Twitter represents the default source for most event streaming examples, and it’s particularly useful in our case because it contains high-volume event streaming data with easily identifiable keywords that can be used to filter for relevant topics. Ingesting Twitter data. connector.state]. Transfermarkt. The Guardian.
All of these happen continuously and repetitively on a daily basis, amounting to petabytes worth of information and data. This requires massive amounts of dataingestion, messaging, and processing within a data-in-motion context. From a dataingestion standpoint, NiFi is designed for this purpose.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content