This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
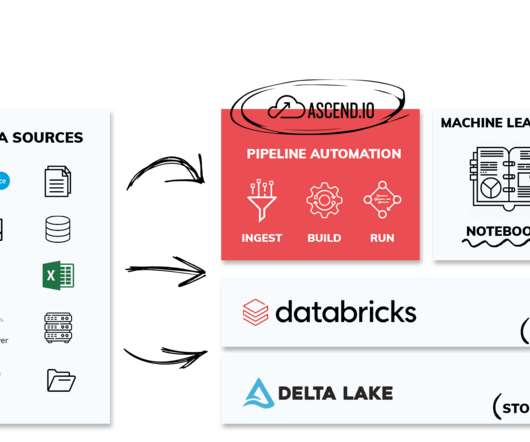
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. In fact, while only 3.5% That’s where our friends at Ascend.io
Working with our partners, this architecture includes MQTT-based dataingestion into Snowflake. This provides a highly scalable, fast, flexible (OT data published by exception from edge to cloud), and secure communication to Snowflake. Stay tuned for more insights on Industry 4.0 and supply chain in the coming months.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
link] LinkedIn: Journey of next-generation control plane for data systems LinkedIn writes about the evolution of Nuage, its internal control plane framework for managing data infrastructure resources. link] Grab: Improving Hugo's stability and addressing oncall challenges through automation.
Instead, it is a Sankey diagram driven by the same dynamic metadata that runs the Ascend control plane. Other dataingestion enhancements include: Incremental read for MS SQL can now be based on a datetime column Native data types support in our Salesforce Read Connector and support for the new Hubspot API token.
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange. Dataingestion through ‘s3’. Ozone Namespace Overview.
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. In fact, while only 3.5% That’s where our friends at Ascend.io
For organizations with lakehouse architectures, Snowflake has developed features that simplify the experience of building pipelines and securing data lakehouses with Apache Iceberg™, the leading open source table format. Support for auto-refresh and Iceberg metadata generation is coming soon to Delta Lake Direct.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. For example, we have a service that stores a movie entity’s metadata or a service that stores metadata about images. In this case it is BOUNDING_BOX.
Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources. Our dataingestion approach, in a nutshell, is classified broadly into two buckets?—?push We leverage Metacat data, our internal metadata store and service, to enrich lineage data with additional table metadata.
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
Also, the associated business metadata for omics, which make it findable for later use, are dynamic and complex and need to be captured separately. Additionally, the fact that they need to be standardized makes the data discovery effort challenging for downstream analysis.
DataIngestion. The raw data is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files. Parquet also stores type metadata which makes reading back and processing the files later slightly easier. P2 GPU instances are not supported.
Snowpark Updates Model management with the Snowpark Model Registry – public preview Snowpark Model Registry is an integrated solution to register, manage and use models and their metadata natively in Snowflake. Learn more here. Learn more here.
It also becomes the role of the data engineering team to be a “center of excellence” through the definitions of standards, best practices and certification processes for data objects. In a fast growing, rapidly evolving, slightly chaotic data ecosystem, metadata management and tooling become a vital component of a modern data platform.
In the past year, the Bank of the West has begun using the Cloudera platform to establish a data governance and security framework to manage and protect its customers’ sensitive information. The platform is centralizing the data, data management & governance, and building custom controls for dataingestion into the system.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
There is no way that one computer node will ever be able to ingest and process all the events that get generated in real time. We therefore need a way of splitting up the dataingestion work. The broker then waits until that specific __consumer_offsets topic’s partition data gets replicated to all its followers.
With this in mind, it’s clear that no “one size fits all” architecture will work here; we need a diverse set of data services, fit for each workload and purpose, backed by optimized compute engines and tools. . Data changes in numerous ways: the shape and form of the data changes; the volume, variety, and velocity changes.
Governed internal collaboration with better discoverability and AI-powered object metadata Snowflake is introducing an entirely new way for data teams to easily discover, curate and share data, apps and now also models (private preview soon). Getting dataingested now only takes a few clicks, and the data is encrypted.
This customer’s workloads leverage batch processing of data from 100+ backend database sources like Oracle, SQL Server, and traditional Mainframes using Syncsort. Data Science and machine learning workloads using CDSW. The customer is a heavy user of Kafka for dataingestion. on roadmap). Instead use Ranger REST API.
Jeff Xiang | Software Engineer, Logging Platform Vahid Hashemian | Software Engineer, Logging Platform Jesus Zuniga | Software Engineer, Logging Platform At Pinterest, data is ingested and transported at petabyte scale every day, bringing inspiration for our users to create a life they love.
Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed data lakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. Data Preparation (Apache Spark and Apache Hive) .
An Avro file is formatted with the following bytes: Figure 1: Avro file and data block byte layout The Avro file consists of four “magic” bytes, file metadata (including a schema, which all objects in this file must conform to), a 16-byte file-specific sync marker, and a sequence of data blocks separated by the file’s sync marker.
Collects and aggregates metadata from components and present cluster state. Metadata in cluster is disjoint across components. This architecture allows for: Extremely fast dataingest, and data engineering done at the data lake. Apache Ozone handles both large and small size files. .
Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), Cloudera customers, such as Teranet , have built open lakehouses to future-proof their data platforms for all their analytical workloads. Only metadata will be regenerated. Data quality using table rollback.
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. Sometimes Data Engineers write downstream ETLs on ingesteddata to optimize the data/metadata layouts to make other ETL processes cheaper and faster.
Under the hood, Rockset utilizes its Converged Index technology, which is optimized for metadata filtering, vector search and keyword search, supporting sub-second search, aggregations and joins at scale. Feature Generation: Transform and aggregate data during the ingest process to generate complex features and reduce data storage volumes.
Distributed Tracing: the missing context in troubleshooting services at scale Prior to Edgar, our engineers had to sift through a mountain of metadata and logs pulled from various Netflix microservices in order to understand a specific streaming failure experienced by any of our members.
The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory. In this category I recommend also to have a look at dataingestion (Airbyte, Fivetran, etc.), workflows (Airflow, Prefect, Dagster, etc.)
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
Closely related to this is how those same platforms are bundling or unbundling related data services from dataingestion and transformation to data governance and monitoring. Why are these things related, and more importantly, why should data leaders care?
WAP [Write-Audit-Publish] Pattern The WAP pattern follows a three-step process Write Phase The write phase results from a dataingestion or data transformation step. In the 'Write' stage, we capture the computed data in a log or a staging area. Event Routers can add additional metadata to the envelope of the event.
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig.
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. manage versions of vectors, metadata management, etc.)
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. being data exactly matches the classifier, and 0.0 Why Use AWS Glue?
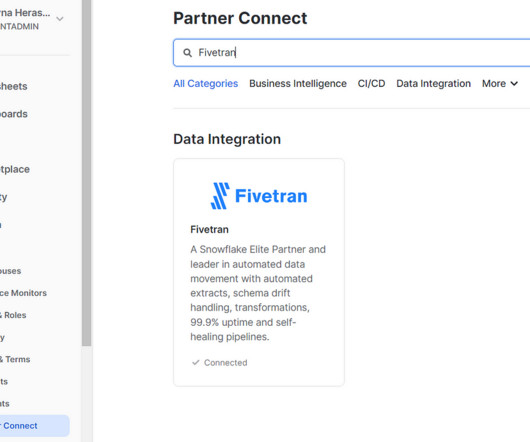
Ingestion — Fivetran Dataingestion can be configured from both Fivetran and Snowflake using the Partner Connect feature. After the initial sync, you can access your data from the Snowflake UI. You will see the data lineage graph and metadata which is automatically created from your project.
The APIs support emitting unstructured log lines and typed metadata key-value pairs (per line). Ingestion clusters read objects from queues and support additional parsing based on user-defined regex extraction rules. The extracted key-value pairs are written to the line’s metadata.
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern data warehouse solution, one that balances speed with platform cost management, performance, and reliability.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
ML Pipeline operations begins with dataingestion and validation, followed by transformation. The transformed data is trained and deployed. This process also creates a sqlite database for storing the metadata of the pipeline process. Every record and its metadata are stored in dictionary format.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content