This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Data Silos: Breaking down barriers between data sources. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g.,
The biggest challenge with modern datasystems is understanding what data you have, where it is located, and who is using it. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. Sifflet also offers a 2-week free trial. In fact, while only 3.5%
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. and then to Nuage 3.0, The article highlights Nuage 3.0's
requires multiple categories of data, from time series and transactional data to structured and unstructured data. It also relies on the integration of information technology (IT) and operational technology (OT) systems to support functions across the organization. Industry 4.0 Expanding on the key Industry 4.0
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange. Dataingestion through ‘s3’. Ozone Namespace Overview.
This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution. SnowConvert is an easy-to-use code conversion tool that accelerates legacy relational database management system (RDBMS) migrations to Snowflake.
Finally, imagine yourself in the role of a data platform reliability engineer tasked with providing advanced lead time to data pipeline (ETL) owners by proactively identifying issues upstream to their ETL jobs. Let’s review a few of these principles: Ensure data integrity ?—?Accurately Enable seamless integration?—?
Summary The best way to make sure that you don’t leak sensitive data is to never have it in the first place. The team at Skyflow decided that the second best way is to build a storage system dedicated to securely managing your sensitive information and making it easy to integrate with your applications and datasystems.
For example, the data storage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. Alation, Collibra) to some niche ones Allows easy ingestion of metadata (such as genomics metadata in Fig.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
In relation to previously existing roles , the data engineering field could be thought of as a superset of business intelligence and data warehousing that brings more elements from software engineering. Those systems have been taught to normalize the data for storage on their own.
Although it is the simplest way to subscribe to and access events from Kafka, behind the scenes, Kafka consumers handle tricky distributed systems challenges like data consistency, failover and load balancing. Data processing requirements. We therefore need a way of splitting up the dataingestion work.
Snowpark Updates Model management with the Snowpark Model Registry – public preview Snowpark Model Registry is an integrated solution to register, manage and use models and their metadata natively in Snowflake. Learn more here. Learn more here. The pipe can only be set to this state by Snowflake Support.
Understanding that the future of banking is data-driven and cloud-based, Bank of the West embraced cloud computing and its benefits, like remote capabilities, integrated processes, and flexible systems. Winner of the Data Impact Awards 2021: Security & Governance Leadership. You can become a data hero too.
This customer’s workloads leverage batch processing of data from 100+ backend database sources like Oracle, SQL Server, and traditional Mainframes using Syncsort. Data Science and machine learning workloads using CDSW. The customer is a heavy user of Kafka for dataingestion. Gather information on the current deployment.
From dataingestion, data science, to our ad bidding[2], GCP is an accelerant in our development cycle, sometimes reducing time-to-market from months to weeks. DataIngestion and Analytics at Scale Ingestion of performance data, whether generated by a search provider or internally, is a key input for our algorithms.
This CVD is built using Cloudera Data Platform Private Cloud Base 7.1.5 on Cisco UCS S3260 M5 Rack Server with Apache Ozone as the distributed file system for CDP. Collects and aggregates metadata from components and present cluster state. Metadata in cluster is disjoint across components. Data Generation at Scale.
which is difficult when troubleshooting distributed systems. We could also get contextual information about the streaming session by joining relevant traces with account metadata and service logs. Edgar uses this infrastructure tagging schema to query and join traces with log data for troubleshooting streaming sessions.
Governed internal collaboration with better discoverability and AI-powered object metadata Snowflake is introducing an entirely new way for data teams to easily discover, curate and share data, apps and now also models (private preview soon). Getting dataingested now only takes a few clicks, and the data is encrypted.
We’re excited to introduce vector search on Rockset to power fast and efficient search experiences, personalization engines, fraud detection systems and more. Feature Generation: Transform and aggregate data during the ingest process to generate complex features and reduce data storage volumes.
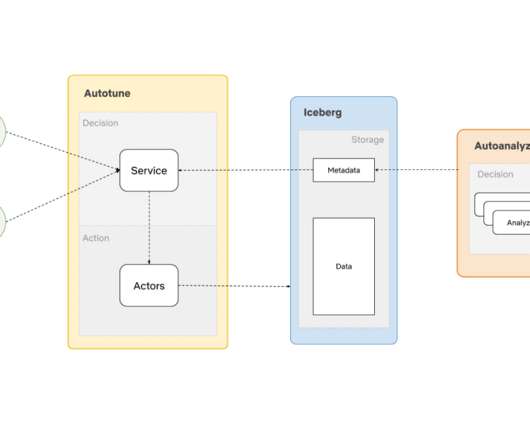
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. Use cases We found several use cases where a system like AutoOptimize can bring tons of value. We can also reorganize the metadata to make file scanning much faster.
In the first part of this series, we talked about design patterns for data creation and the pros & cons of each system from the data contract perspective. In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective. Why is Data Quality Expensive?
Summary The optimal format for storage and retrieval of data is dependent on how it is going to be used. For analytical systems there are decades of investment in data warehouses and various modeling techniques. What are the primary system requirements that have influenced the design choices? In fact, while only 3.5%
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
What is data engineering As I said it before data engineering is still a young discipline with many different definitions. Still, we can have a common ground when mixing software engineering, DevOps principles, Cloud — or on-prem — systems understanding and data literacy. Is it really modern?
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. being data exactly matches the classifier, and 0.0 Why Use AWS Glue?
Now you can easily retrieve it from your account by leveraging “data movement platforms” like Fivetran. This tool automates ELT (Extract, Load, Transform) process, integrating your data from the source system of Google Calendar to our Snowflake data warehouse. As of now, Fivetran offers 14-day free trial — link.
ECC will enrich the data collected and will make it available to be used in analysis and model creation later in the data lifecycle. Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig.
The author goes beyond comparing the tools to various offerings from streaming vendors in stream processing and Kafka protocol-supported systems. The logging engine to debug AI workflow logs is an excellent system design study if you’re interested in it. The extracted key-value pairs are written to the line’s metadata.
Running on CDW is fully integrated with streaming, data engineering, and machine learning analytics. It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. Consideration of both data & metadata in the migration.
“Observability” has become a bit of a buzzword so it’s probably best to define it: Data observability is the blanket term for monitoring and improving the health of data within applications and systems like data pipelines. Data observability vs. monitoring: what is the difference?
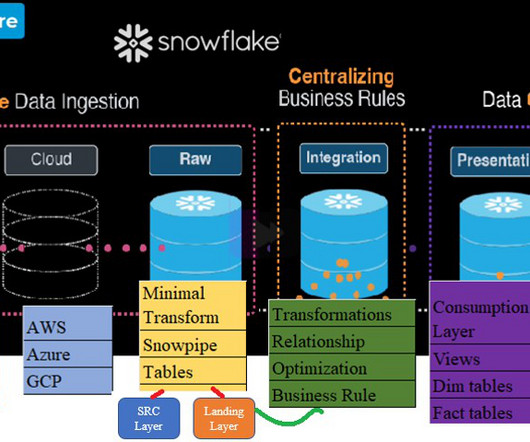
DCDW Architecture Above all, Architecture was divided into three Business layers: Firstly,Agile Dataingestion : Heterogeneous Source System fed the data into Cloud. Respective Cloud would consume/Store the data in bucket or containers. Load the data AS-IS into Snowflake called RAW layer.
The modern data stack consists of multiple interdependent datasystems all working together. Data anomalies and incidents can be introduced across any point of this pipeline, which can make root cause analysis a fragmented and frustrating multi-tab process. Was it a query changed within Snowflake? A modified dbt model?
Are these sources a match for all my batch dataingest and change data capture (CDC) needs? #2. Whether you’re bringing a new system online or connecting an existing database with your analytics platform, the process should be simple and straightforward. A notable capability that achieves this is the data catalog.
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern data warehouse solution, one that balances speed with platform cost management, performance, and reliability.
By offering real-time tracking mechanisms and sending targeted alerts to specific consumers, a Payload DJ can immediately notify them of any changes, delays, or issues affecting their data. This transparent system effectively answers real-time data location and status questions, thus enhancing customer trust and satisfaction.
Query across your ANN indexes on vector embeddings, and your JSON and geospatial “metadata” fields efficiently. Spin a Virtual Instance for streaming dataingestion. As AI models become more advanced, LLMs and generative AI apps are liberating information that is typically locked up in unstructured data.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structured data and the file system underneath is Colossus, the distributed file system by Google. Load data For dataingestion Google Cloud Storage is a pragmatic way to solve the task.
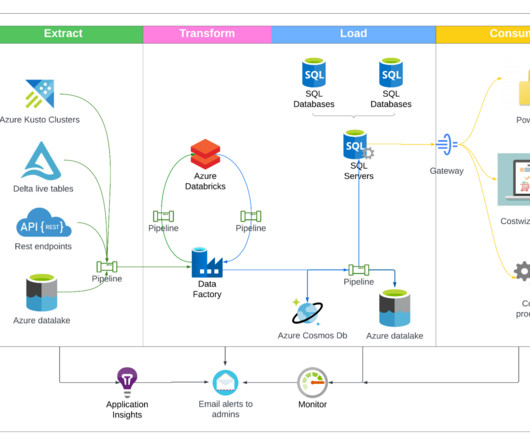
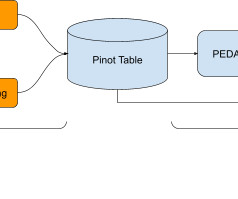
Costwiz application and workflow management system For the initial rollout, we built a single-page app for users to perform actions on their recommendations (as seen in Figure 1). Data providers: The core input data for which the workflows should be executed and other supporting data required are fed to the system by data providers.
Although we can prescribe a way to achieve an overall privacy guarantee with differential privacy with various algorithms, there is still the challenge of integrating differential privacy into an existing system that can return analytics for streaming data in real-time under intense query loads.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content