This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (Unstructured Data). Organizations need dataingestion and integration to realize the complete value of their data assets.
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (Unstructured Data). Organizations need dataingestion and integration to realize the complete value of their data assets.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
The application you're implementing needs to analyze this data, combining it with other datasets, to return live metrics and recommended actions. But how can you interrogate the data and frame your questions correctly if you don't understand the shape of your data? This enables Rockset to generate a Smart Schema on the data.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Data Collection Using Cloudera Data Platform.
DataIngestion. The rawdata is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files. Common problems at this stage can be related to GPU versions. RAPIDS is only supported on Pascal or newer NVIDIA GPUs.
Data Management A tutorial on how to use VDK to perform batch data processing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source dataingestion and processing framework designed to simplify data management complexities. link] Summary Congratulations!
The data and the techniques presented in this prototype are still applicable as creating a PCA feature store is often part of the machine learning process. . The process followed in this prototype covers several steps that you should follow: DataIngest – move the rawdata to a more suitable storage location.
These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed. Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline.
Schedule dataingestion, processing, model training and insight generation to enhance efficiency and consistency in your data processes. Access Snowflake platform capabilities and data sets directly within your notebooks.
The modeling process begins with data collection. Here, Cloudera Data Flow is leveraged to build a streaming pipeline which enables the collection, movement, curation, and augmentation of rawdata feeds. These feeds are then enriched using external data sources (e.g.,
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. In fact, while only 3.5% That’s where our friends at Ascend.io
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as dataingestion and processing from different sources, using SQL or Python.
Data Flow – is an individual data pipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the data pipeline workload runs, like Databricks, BigQuery, and Snowflake.
Data Flow – is an individual data pipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the data pipeline workload runs, like Databricks, BigQuery, and Snowflake.
While terms like “Fivetran ETL” or “Fivetran data pipeline” are echoing in the corridors of data professionals, the truth is, Fivetran is primarily an expert on dataingestion — just the first step in a much broader and nuanced data management process.
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. ® , Go, and Python SDKs where an application can use SQL to query rawdata coming from Kafka through an API (but that is a topic for another blog). However, Apache Kafka is more than just messaging.
The Third of Five Use Cases in Data Observability Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures data quality from the onset. Examples include regular loading of CRM data and anomaly detection.
In this article, we’ll dive deep into the data presentation layers of the data stack to consider how scale impacts our build versus buy decisions, and how we can thoughtfully apply our five considerations at various points in our platform’s maturity to find the right mix of components for our organizations unique business needs.
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline dataingestion, processing, and analytics by automating and integrating various data workflows.
The intention of Dynamic Tables is to apply incremental transformations on near real-time dataingestion that Snowflake now supports with Snowpipe Streaming. Data enters Snowflake in its raw operational form (event data) and Dynamic Tables transforms that rawdata into a form that serves analytical value.
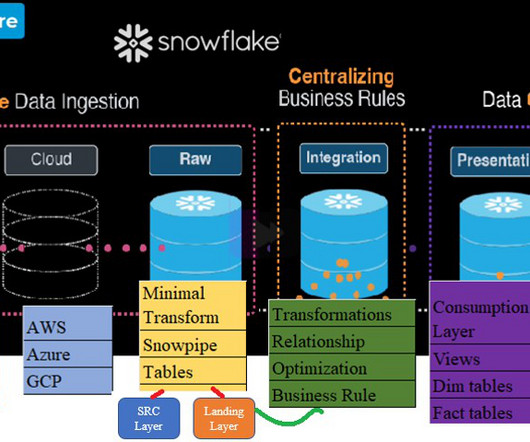
DCDW Architecture Above all, Architecture was divided into three Business layers: Firstly,Agile Dataingestion : Heterogeneous Source System fed the data into Cloud. Respective Cloud would consume/Store the data in bucket or containers. Load the data AS-IS into Snowflake called RAW layer.
In the contemporary data landscape, data teams commonly utilize data warehouses or lakes to arrange their data into L1, L2, and L3 layers. The current landscape of Data Observability Tools shows a marked focus on “Data in Place,” leaving a significant gap in the “Data in Use.”
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Video explaining how data streaming works.
Architecture designed to empower more clients Gem’s cybersecurity platform starts with rawdataingestion from its clients’ cloud environments. Gem uses the fully-managed Snowpipe service, allowing it to stream and process source data in near-real time. Pushing and scaling are super smooth.
Welcome to the comprehensive guide for beginners on harnessing the power of Microsoft's remarkable data visualization tool - Power BI. In today's data-driven world, the ability to transform rawdata into meaningful insights is paramount, and Power BI empowers users to achieve just that. What is Power BI?
Similarly , in data, every step of the pipeline, from dataingestion to delivery, plays a pivotal role in delivering impactful results. In this article, we’ll break down the intricacies of an end-to-end data pipeline and highlight its importance in today’s landscape.
If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructured data on their models or analysis. For example, an industrial analytics team wants to use the logs from rawdata. The Data Warehouse(s) facilitates dataingestion and enables easy access for end-users.
The key differentiation lies in the transformational steps that a data pipeline includes to make data business-ready. Ultimately, the core function of a pipeline is to take rawdata and turn it into valuable, accessible insights that drive business growth. cleaning, formatting)?
A data lake is essentially a vast digital dumping ground where companies toss all their rawdata, structured or not. A modern data stack can be built on top of this data storage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Instead, we can focus on building a flexible and versatile model that can be easily extended to new types of input data and applied to a variety of prediction tasks. In general, learning from rawdata can help to avoid limitations when placing too much confidence in human domain modeling.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
For this reason, your data platform becomes the foundation for your AI initiatives. Robust DataIngestion AI systems thrive on diverse data sources. Your platform should be equipped with robust mechanisms for dataingestion and integration, enabling seamless flow of data from various sources into the system.
It seems everyone has a handful of such shapes in their rawdata, and in the past they had to fix those shapes outside of Snowflake before ingesting them. Introducing CARTO Workflows Snowflake’s powerful dataingestion and transformation features help many data engineers and analysts who prefer SQL.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content