This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We do that by excluding the following from all queries in our system. Dataingestion pipeline with Operation Management was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
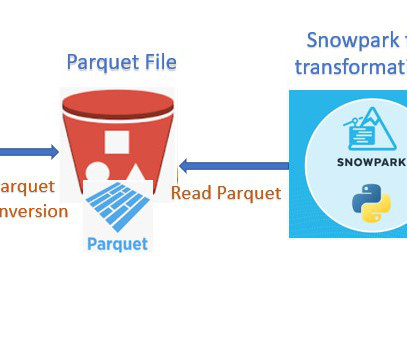
As per the requirement source system has fed a CSV file to our S3 bucket which needs to be ingested into Snowflake. Parquet, columnar storage file format saves both time and space when it comes to big data processing. Instead of consuming the file as-is we are supposed to convert the file into Parquet format.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (Unstructured Data). Organizations need dataingestion and integration to realize the complete value of their data assets.
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (Unstructured Data). Organizations need dataingestion and integration to realize the complete value of their data assets.
Systems must be capable of handling high-velocity data without bottlenecks. Addressing these challenges demands an end-to-end approach that integrates dataingestion, streaming analytics, AI governance, and security in a cohesive pipeline. As you can see, theres a lot to consider in adopting real-time AI.
The Bronze layer is the initial landing zone for all incoming raw data, capturing it in its unprocessed, original form. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable data pipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing.
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. If you notice delays in data availability or if the system isn’t keeping up with the data load, adjustments might be necessary.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
By enabling advanced analytics and centralized document management, Digityze AI helps pharmaceutical manufacturers eliminate data silos and accelerate data sharing. KAWA Analytics Digital transformation is an admirable goal, but legacy systems and inefficient processes hold back many companies efforts.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
Data Silos: Breaking down barriers between data sources. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). Dataingestion tools often create numerous small files, which can degrade performance during query execution.
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
In recent years, while managing Pinterests EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2s network performance and its direct impact on our applications reliability and performance. In the database service, the application reads data (e.g.
lower latency than Elasticsearch for streaming dataingestion. We’ll also delve under the hood of the two databases to better understand why their performance differs when it comes to search and analytics on high-velocity data streams. Why measure streaming dataingestion? Data Latency: Rockset sees up to 2.5x
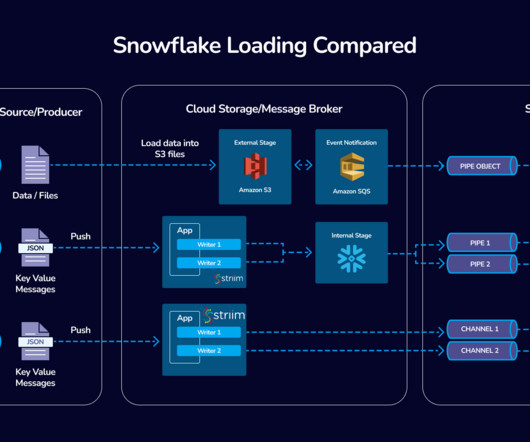
Read Time: 2 Minute, 34 Second Introduction In modern data pipelines, especially in cloud data platforms like Snowflake, dataingestion from external systems such as AWS S3 is common.
If the underlying data is incomplete, inconsistent, or delayed, even the most advanced AI models and business intelligence systems will produce unreliable insights. Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis.
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. and then to Nuage 3.0, The article highlights Nuage 3.0's
[link] Alex Miller: Decomposing Transactional Systems I was re-reading Jack Vanlightly's excellent series on understanding the consistency model of various lakehouse formats when I stumbled upon the blog on decomposing transaction systems. We all know that data freshness plays a critical role in the performance of Lakehouse.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. This caused system contention, missed SLAs, delayed report deliveries and significant maintenance overhead.
They applied solutions like SAP BusinessObjects Data Services, Fivetran and Qlik, or used extractors to get SAP data into SAP BW and then attached more tools to get the data from SAP BW into other systems. Those trade-offs became less acceptable as demand for near real-time data and analytics increased.
Introduction At Lyft, we have used systems like Apache ClickHouse and Apache Druid for near real-time and sub-second analytics. Sub-second query systems allow for near real-time data explorations and low latency, high throughput queries, which are particularly well-suited for handling time-series data.
Faster, easier ingest To make dataingestion even more cost effective and effortless, Snowflake is announcing performance improvements of up to 25% for loading JSON files, and for loading Parquet files, up to 50%. Getting dataingested now only takes a few clicks, and the data is encrypted.
report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. What are the mechanisms that you use for categorizing data assets?
As advanced use cases, like advanced driver assistance systems featuring lane change departure detection, advanced vehicle diagnostics, or predictive maintenance move forward, the existing infrastructure of the connected car is being stressed. billion in 2019, and is projected to reach $225.16 billion by 2027, registering a CAGR of 17.1%
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution. SnowConvert is an easy-to-use code conversion tool that accelerates legacy relational database management system (RDBMS) migrations to Snowflake.
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity.
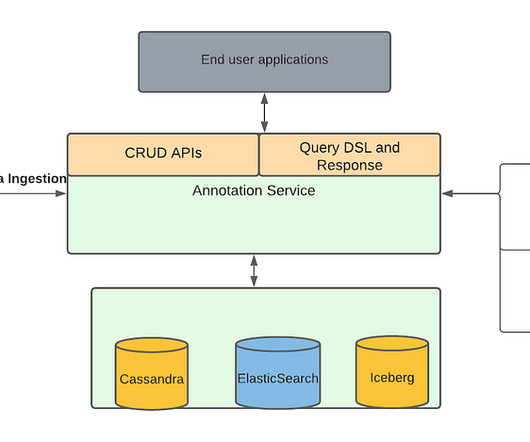
To serve the presentation view of a Product Offer, a multi-stage event-driven system merged Product, Price, and Stock events into a single structure. With ~350 engineering teams and thousands of deployed applications, many relying directly or indirectly on Product data, migration was always going to be complex.
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. Data Processing That brings us to our next step: Data processing.
While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange. Dataingestion through ‘s3’. Ozone Namespace Overview.
Data integrations and pipelines can also impact latency. Complex data transformations and ETL/ELT pipelines with significant data movement can see increases in latency. Streamlining dataingestion and transformation pipelines can help decrease latency.
Strategically enhancing address mapping during data integration using geocoding and string matching Many individuals in the big data industry may encounter the following scenario: Is the acronym “TIL” equivalent to the phrase “Today I learned” when extracting these two entries from distinct systems?
For a more in-depth exploration, plus advice from Snowflake’s Travis Henry, Director of Sales Development Ops and Enablement, and Ryan Huang, Senior Marketing Data Analyst, register for our Snowflake on Snowflake webinar on boosting market efficiency by leveraging data from Outreach. Each of these sources may store data differently.
Python developers can start increasing the impact of their work by building apps that bridge the gap between data and actionable insights for business teams — without adding any ops burden to IT teams. Learn more here. The pipe can only be set to this state by Snowflake Support.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. You need to think about the whole model lifecycle.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content