This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
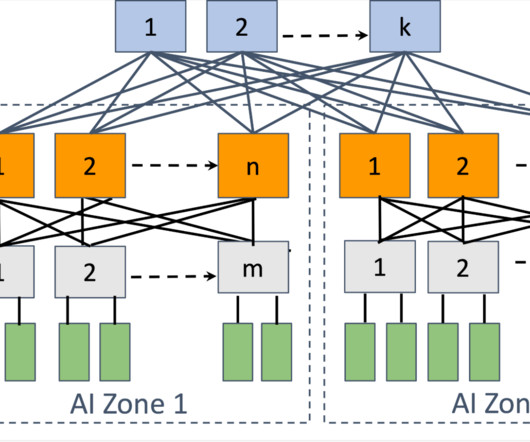
When Meta introduced distributed GPU-based training , we decided to construct specialized data center networks tailored for these GPU clusters. We opted for RDMA Over Converged Ethernet version 2 (RoCEv2) as the inter-node communication transport for the majority of our AI capacity.
Roads and Transport Authority, Dubai. The Roads and Transport Authority (RTA) operating in Dubai wanted to apply big data capabilities to transportation and enhance travel efficiency. For this, the RTA transformed its dataingestion and management processes. .
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
To drive these data use cases, the Department of Defense (DoD) communities and branches require a reliable, scalable datatransport mechanism to deliver data (from any source) from origination through all points of consumption; at the edge, on-premise, and in the cloud in a simple, secure, universal, and scalable way.
Each component incorporates end-to-end non-blocking I/O, leveraging Nettys EventLoop with Linux-native Epoll transport. Country-Level Isolation / Getting Data In To achieve a level of country-level isolation, multiple instances of PRAPI are deployedknown as Market Groupswith each serving a subset of our countries.
Transportation: Monitor truck health and performance from smartphones and tablets, prioritize needed reports, and quickly identify the nearest dealer service locations. A modern streaming architecture consists of critical components that provide dataingestion, security and governance, and real-time analytics.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Conclusion.
Stream Processing: to sample or not to sample trace data? This was the most important question we considered when building our infrastructure because data sampling policy dictates the amount of traces that are recorded, transported, and stored. Mantis is our go-to platform for processing operational data at Netflix.
As a result, a single consolidated and centralized source of truth does not exist that can be leveraged to derive data lineage truth. Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources. push or pull. Today, we are operating using a pull-heavy model.
In a nutshell you have: text based formats (CSV, JSON and raw stuff), columnar file formats (Parquet, ORC), memory format ( Arrow ), transport protocols and format (Protobuf, Thrift, gRPC, Avro), table formats ( Hudi, Iceberg, Delta ), database and vendor formats (Postgres, Snowflake, BigQuery, etc.).
The organization was locked into a legacy data warehouse with high operational costs and inability to perform exploratory analytics. With more than 25TB of dataingested from over 200 different sources, Telkomsel recognized that to best serve its customers it had to get to grips with its data. .
Jeff Xiang | Software Engineer, Logging Platform Vahid Hashemian | Software Engineer, Logging Platform Jesus Zuniga | Software Engineer, Logging Platform At Pinterest, data is ingested and transported at petabyte scale every day, bringing inspiration for our users to create a life they love.
It allows real-time dataingestion, processing, model deployment and monitoring in a reliable and scalable way. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers. Any option can pair well with Apache Kafka.
The Five Use Cases in Data Observability: Effective Data Anomaly Monitoring (#2) Introduction Ensuring the accuracy and timeliness of dataingestion is a cornerstone for maintaining the integrity of data systems. This process is critical as it ensures data quality from the onset.
Data Collection and Integration: Data is gathered from various sources, including sensor and IoT data, transportation management systems, transactional systems, and external data sources such as economic indicators or traffic data. Here’s the process. That’s where Striim came into play.
As IoT projects go from concepts to reality, one of the biggest challenges is how the data created by devices will flow through the system. Since MQTT is designed for low-power and coin-cell-operated devices, it cannot handle the ingestion of massive datasets. Interactive M2M/IoT Sector Map. MQTT Proxy + Apache Kafka (no MQTT broker).
ML Pipeline operations begins with dataingestion and validation, followed by transformation. The transformed data is trained and deployed. Initializing the InteractiveContext # This will create an sqlite db for storing the metadata context = InteractiveContext(pipeline_root=_pipeline_root) Next, we start with dataingestion.
What emerges is the criticality of a data strategy and core data management competency, including both data and model management, to support enterprise ML initiatives.
Data comes in a continuous manner, and often a separate architecture is required to handle streaming data. What remains challenging is how streaming data is brought together with batch data. That’s why we built Snowpipe Streaming, now generally available to handle row-set dataingestion. Commerce Datos Inc.
The data observability solutions require more attention in the remediation workflow to ensure they don’t end up as a disjointed workflow like Data Catalogs. Meta: Tulip - Modernizing Meta’s data platform Meta writes about Tulip's adoption story, its datatransportation, and the serialization protocol for its data platform.
Lifting-and-shifting their big data environment into the cloud only made things more complex. The modern data stack introduced a set of cloud-native data solutions such as Fivetran for dataingestion, Snowflake, Redshift or BigQuery for data warehousing , and Looker or Mode for data visualization.
This shift not only saves time but also ensures a higher standard of data quality. Tools like BiG EVAL are leading data quality field for all technical systems in which data is transported and transformed.
Finnhub API with Kafka for Real-Time Financial Market Data Pipeline Project Overview: The goal of this project is to construct a streaming data pipeline by making use of the real-time financial market data API provided by Finnhub.
Contrary to traditional methods, such as batch processing where data is collected, stored, and analyzed at a later time, with real-time processing there’s no delay even for high-velocity data sets. This data must be ingested with minimal latency to ensure it is available for immediate processing.
Generally, five key steps comprise the standard workflow for spatial data scientists, which takes them from data collection to offering business insights after the process. Machine learning is increasingly becoming a necessary component of every workflow due to the growing quantity of data businesses gather, store, and evaluate.
Data Engineering Data engineering is a process by which data engineers make data useful. Data engineers design, build, and maintain data pipelines that transform data from a raw state to a useful one, ready for analysis or data science modeling. HDFS stands for Hadoop Distributed File System.
DataIngestion Snowpipe auto-ingest expands to support cross-cloud and cross-platform ingestion – public preview With this release, we are making a few enhancements to Snowpipe auto-ingest to make ingestion easier with Snowflake. Visit our documentation page to learn more.
CDC leverages streaming in order to track and transport changes from one system to another. First, CDC theoretically allows companies to analyze and react to data in real time, as it’s generated. These will help users more easily configure the correct transformations on top of CDC data.
AWS Glue Studio offers several built-in transforms for the purpose of processing your data. A DynamicFrame, an extension of an Apache Spark SQL DataFrame, transports your data from one job node to the next. You can transform your data using the Transform-ApplyMapping transform node or additional transforms.
Then, we’ll explore a data pipeline example and dive deeper into the key differences between a traditional data pipeline vs ETL. What is a Data Pipeline? A data pipeline refers to a series of processes that transportdata from one or more sources to a destination, such as a data warehouse, database, or application.
Read our article on Hotel Data Management to have a full picture of what information can be collected to boost revenue and customer satisfaction in hospitality. While all three are about data acquisition, they have distinct differences.
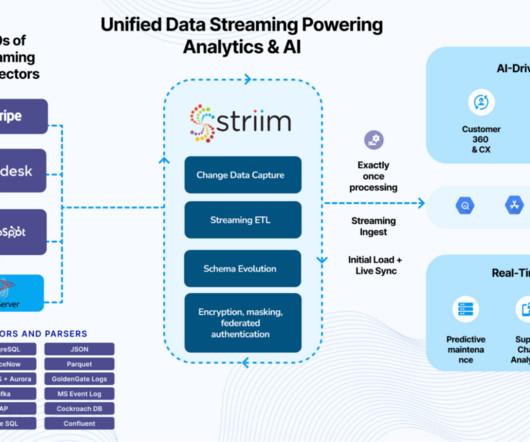
Focused on delivering real-time intelligence for AI and leveraging change data capture (CDC) from databases, Striim’s approach addresses the urgent need for thorough data integration, emphasizing the critical role of connecting disparate applications to fully realize their potential. What is Striim Cloud for Application Integration?
It includes the service and capability portfolio that makes the device connectivity, dataingestion, analytics, and integration with other cloud services. Azure IoT by Microsoft is a comprehensive platform that helps organizations connect, monitor, and manage many IoT devices and assets. trillion by 2026.
It’s represented in terms of batch reporting, near real-time/real-time processing, and data streaming. The best-case scenario is when the speed with which the data is produced meets the speed with which it is processed. Let’s take the transportation industry for example. Big Data analytics processes and tools.
Data engineers serve as the architects, laying the foundation upon which data scientists construct their projects. They are responsible for the crucial tasks of gathering, transporting, storing, and configuring data infrastructure, which data scientists rely on for analysis and insights.
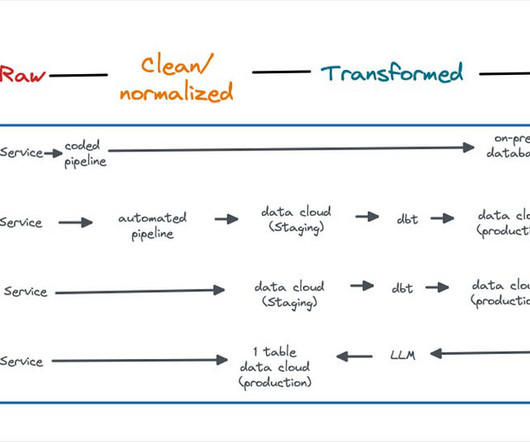
Yes, data warehouses can store unstructured data as a blob datatype. Data Transformation Raw dataingested into a data warehouse may not be suitable for analysis. Data engineers use SQL, or tools like dbt, to transform data within the data warehouse. They need to be transformed.
However, you can also pull data from centralized data sources like data warehouses to transform data further and build ETL pipelines for training and evaluating AI agents. Processing: It is a data pipeline component that decides the data flow implementation.
Okay, data lives everywhere, and that’s the problem the second component solves. Data integration Data integration is the process of transportingdata from multiple disparate internal and external sources (including databases, server logs, third-party applications, and more) and putting it in a single location (e.g.,
What are the steps involved in deploying a big data solution? The core components of Flume are – Event- The single log entry or unit of data that is transported. Source- This is the component through which data enters Flume workflows. Sink-It is responsible for transportingdata to the desired destination.
And so it almost seems unfair that new ideas are already springing up to disrupt the disruptors: Zero-ETL has dataingestion in its sights AI and Large Language Models could transform transformation Data product containers are eyeing the table’s thrown as the core building block of data Are we going to have to rebuild everything (again)?
And so it almost seems unfair that new ideas are already springing up to disrupt the disruptors: Zero-ETL has dataingestion in its sights AI and Large Language Models could transform transformation Data product containers are eyeing the table’s thrown as the core building block of data Are we going to have to rebuild everything (again)?
Here are some more instances of how businesses use Big Data: Big data assists oil and gas businesses in identifying potential drilling locations and monitoring pipeline operations; similarly, utilities use it to track power networks. . Data collection might be conditionally triggered, scheduled, or ad hoc. .
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content