This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What’s the best way to execute your dataintegration tasks: writing manual code or using ETLtool? Find out the approach that best fits your organization’s needs and the factors that influence it.
It is important to note that normalization often overlaps with the data cleaning process, as it helps to ensure consistency in data formats, particularly when dealing with different sources or inconsistent units. Data Validation Data validation ensures that the data meets specific criteria before processing.
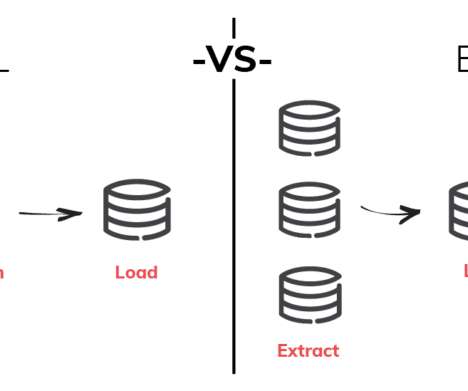
The good news is, businesses can choose the path of dataintegration to make the most out of the available information. The bad news is, integratingdata can become a tedious task, especially when done manually. Dataintegration in a nutshell. Dataintegration process. That’s a lot of work.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your datamanagement to the next level. Dataintegration with ETL has changed in the last three decades.
In this episode Brian McMillan shares his work on the book "Building Data Products" and how he is working to educate business users and data professionals about the combination of technical, economical, and business considerations that need to be blended for these projects to succeed. Who is your target audience?
To get a single unified view of all information, companies opt for dataintegration. In this article, you will learn what dataintegration is in general, key approaches and strategies to integrate siloed data, tools to consider, and more. What is dataintegration and why is it important?
ETL developer is a software developer who uses various tools and technologies to design and implement dataintegration processes across an organization. ETL developers are the backbone of a successful datamanagement strategy as they ensure that the data is consistent and accurate for data-driven decision-making.
To solve the activation challenge and make sure data is not sitting idly in the warehouse, data teams turned to reverse ETL. This article will help contextualize reverse ETL in the world of existing datamanagement approaches. What Is Reverse ETL? Reverse ETL emerged as a result of these difficulties.
Data doesn’t just flow – it floods in at breakneck speed. How do we track this tsunami of changes, ensure dataintegrity, and extract meaningful insights? Data versioning is the answer. Data versioning is the practice of tracking and managing changes to datasets over time.
Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange. This indicates the growing use of the ETL process and various ETLtools and techniques across multiple industries.
The demand for qualified experts who can make use of Azure's data capabilities, eventually promoting organizational efficiency, innovation, and informed decision-making through efficient datamanagement and analytics, is what motivates employers to hire Azure Data Engineers. Why Do Companies Hire Azure Data Engineers?
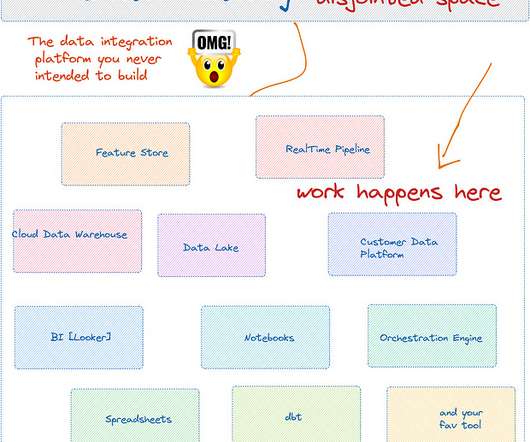
Data catalogs are the most expensive dataintegration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern data workflow, not just adding “modern” in its prefix. There are not many sources to pull the metadata.
In this article, we’ll delve into what is an automated ETL pipeline, explore its advantages over traditional ETL, and discuss the inherent benefits and characteristics that make it indispensable in the data engineering toolkit. What Is an Automated ETL Pipeline? The result?
[link] Meta: The Future of the data engineer — Part I Meta introduced a new term, “Accessible Analytics,” - self-describing to the extent that it doesn’t require specialized skills to draw meaningful insights from it. Meta shares its ever-changing landscape of data engineering.
Use Case Essential for data preprocessing and creating usable datasets. Types of data you can extract Data extraction is a fundamental process in the realm of datamanagement and analysis, encompassing the retrieval of specific, relevant information from various sources.
Data Engineer Career: Overview Currently, with the enormous growth in the volume, variety, and veracity of data generated and the will of large firms to store and analyze their data, datamanagement is a critical aspect of data science. That’s where data engineers are on the go.
The conventional ETL software and server setup are plagued by problems related to scalability and cost overruns, which are ably addressed by Hadoop. If you encounter Big Data on a regular basis, the limitations of the traditional ETLtools in terms of storage, efficiency and cost is likely to force you to learn Hadoop.
Table of Contents What Does an AI Data Quality Analyst Do? The role is usually on a Data Governance, Analytics Engineering, Data Engineering, or Data Science team, depending on how the data organization is structured. Data Cleaning and Preprocessing : Techniques to identify and remove errors.
Data engineers are programmers first and data specialists next, so they use their coding skills to develop, integrate, and managetools supporting the data infrastructure: data warehouse, databases, ETLtools, and analytical systems. Data warehousing.
Introduction to Apache Iceberg Tables Simplified dataintegrationsManaged solutions like Fivetran and Stitch were built to manage third-party API integrations with ease. These days many companies choose this approach to simplify data interactions with their external data sources.
The need for efficient and agile datamanagement products is higher than ever before, given the ongoing landscape of data science changes. MongoDB is a NoSQL database that’s been making rounds in the data science community. js combined with MongoDB for advanced data visualizations.
Besides these categories, specialized solutions tailored specifically for particular domains or use cases also exist, such as extract, transform and load (ETL) tools for managingdata pipelines, dataintegrationtools for combining information from disparate sources or systems and more.
Tableau Prep has brought in a new perspective where novice IT users and power users who are not backward faithfully can use drag and drop interfaces, visual data preparation workflows, etc., simultaneously making raw data efficient to form insights. Validate dataintegrity at key stages to maintain accuracy throughout your flow.
By loading the data before transforming it, ELT takes full advantage of the computational power of these systems. This approach allows for faster data processing and more flexible datamanagement compared to traditional methods. The extraction process requires careful planning to ensure dataintegrity.
Salesforce integration means the interconnectedness of processes, systems, or databases in addressing several business issues regarding dataintegrity and efficiency. Integration can occur in different ways: API, Middleware, and Custom integration based on the requirements of the business, which two companies have.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, datamanagement , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor. Data engineers must know datamanagement fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology.
They help organizations understand the dependencies between data sources, processes, and systems, enabling better data governance and impact analysis. They provide insights into the health of dataintegration processes, detect issues in real-time, and enable teams to optimize data flows.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. Software Engineers with datamanagement knowledge and specialization usually take up the role of a Big Data Engineer.
You maintain the dataintegrity, security, and performance by monitoring, optimizing, and troubleshooting database operations. Education & Skills Required Bachelor’s or Master’s degree in Computer Science, Data Science , or a related field. Good Hold on MongoDB and data modeling. Strong programming skills (e.g.,
The healthcare industry has seen an exponential growth in the use of datamanagement and integrationtools in recent years to leverage the data at their disposal. Unlocking the potential of “Big Data” is imperative in enhancing patient care quality, streamlining operations, and allocating resources optimally.
Data Solutions Architect Role Overview: Design and implement datamanagement, storage, and analytics solutions to meet business requirements and enable data-driven decision-making. Role Level: Mid to senior-level position requiring expertise in data architecture, database technologies, and analytics platforms.
Workflow: It involves the sequencing of jobs in the data pipeline and managing their dependency. Workflow dependencies can be technical or business-oriented, deciding when a data pipeline runs. Monitoring: It is a component that ensures dataintegrity. ADF does not store any data on its own.
You might implement this using a tool like Apache Kafka or Amazon Kinesis, creating that immutable record of all customer interactions. Data Activation : To put all this customer data to work, you might use a tool like Hightouch or Census. But what exactly is an ontology in the context of customer datamanagement?
Transform Data Once the data is validated, we apply transformations to remove duplicates, perform cleansing, standardization, business rule application, perform dataintegrity checks, data governance, use aggregations, and many more. Stage DataData that has been transformed is stored in this layer.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content