This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we’ll explore the significance of schema evolution using real-world examples with CSV, Parquet, and JSON data formats. Schema evolution allows for the automatic adjustment of the schema in the data warehouse as new data is ingested, ensuring dataintegrity and avoiding pipeline failures.
Do ETL and dataintegration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular dataintegration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
Reading Time: 9 minutes Imagine your data as pieces of a complex puzzle scattered across different platforms and formats. This is where the power of dataintegration comes into play. Meet Airbyte, the data magician that turns integration complexities into child’s play.
Dataintegration As a Snowflake Native App, AI Decisioning leverages the existing data within an organization’s AI Data Cloud, including customer behaviors and product and offer details. During a one-time setup, your data owner maps your existing dataschemas within the UI, which fuels AI Decisioning’s models.
As the paved path for moving data to key-value stores, Bulldozer provides a scalable and efficient no-code solution. Users only need to specify the data source and the destination cluster information in a YAML file. Bulldozer provides the functionality to auto-generate the dataschema which is defined in a protobuf file.
One of its neat features is the ability to store data in a compressed format, with snappy compression being the go-to choice. Another cool aspect of Parquet is its flexible approach to dataschemas. This adaptability makes it super user-friendly for evolving data projects. Plus, there’s the _delta_log folder.
Are we going to be using intermediate data stores to store data as it flows to the destination? Are we collecting data from the origin in predefined batches or in real time? Step 4: Design the data processing plan Once data is ingested, it must be processed and transformed for it to be valuable to downstream systems.
Critical Questions for Data Ingestion Monitoring Effective data ingestion anomaly monitoring should address several critical questions to ensure dataintegrity: Are there any unknown anomalies affecting the data? Have all the source files/data arrived on time? Is the source data of expected quality?
While data warehouses focus on structured data for historical analysis, big data platforms enable processing and analysis of diverse, large-scale, and often unstructured data in real-time. The focus is on maintaining a historical record of data, ensuring dataintegrity and consistency for reporting and analysis purposes.
Introduction to Apache Iceberg Tables Simplified dataintegrations Managed solutions like Fivetran and Stitch were built to manage third-party API integrations with ease. These days many companies choose this approach to simplify data interactions with their external data sources.
The logical basis of RDF is extended by related standards RDFS (RDF Schema) and OWL (Web Ontology Language). They allow for representing various types of data and content (dataschema, taxonomies, vocabularies, and metadata) and making them understandable for computing systems. General scenarios of using knowledge graphs.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
Skills Required for MongoDB for Data Science To excel in MongoDB for data science, you need a combination of technical and analytical skills: Database Querying: It is necessary to know how to write sophisticated queries using the query language of MongoDB. Quickly pull (fetch), filter, and reduce data.
It is because they help you generate dynamic reports and feature data modeling, complete data comparison, and more. Understanding Power BI Requirements As I have mentioned before, Power BI is a revolutionary, remarkable program that enables high-speed dataintegration and the creation of plenty of reports.
The extracted data is often raw and unstructured and may come in various formats such as text, images, audio, or video. The extraction process requires careful planning to ensure dataintegrity. It’s crucial to understand the source systems and their structure, as well as the type and quality of data they produce.
Versatility: The versatile nature of MongoDB enables it to easily deal with a broad spectrum of data types , structured and unstructured, and therefore, it is perfect for modern applications that need flexible dataschemas. Good Hold on MongoDB and data modeling. Experience with ETL tools and dataintegration techniques.
This workflow imbalance allows unencumbered engineering while protecting dataintegrity. Mirror production dataschemas: While masking sensitive information, reflecting production data shapes, interfaces and dependencies reduces surprises when changes reach customers. This improves security and accountability.
To do so, we’ll focus on three steps: Performing the email domain extraction from the email Flagging personal emails Creating a column for corporate emails After we complete these steps, we’ll also cover a "human in the loop" step to ensure dataintegrity at the modelling stage.
This allows for two-way integration so that information can flow from one system to another in real-time. Striim is a cloud-native Data Mesh platform that offers features such as automated data mapping, real-time dataintegration, streaming analytics, and more.
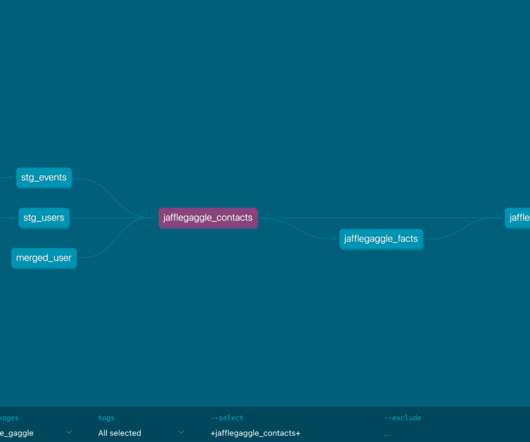
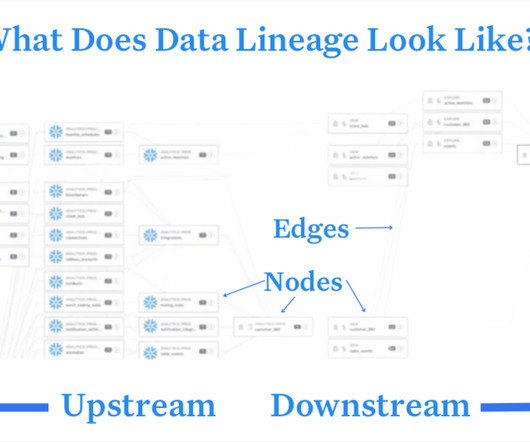
Squatch VP of Data, IT & Security, Nick Johnson. Dataintegration and modeling In previous eras, data models like Data Vault were used to manually create full visibility into data lineage. A few tips for a safe migration using data lineage: Document current dataschema and lineage.
Checking data at rest involves looking at syntactic attributes such as freshness, distribution, volume, schema, and lineage. Start checking data at rest with a strong data profile. The image above shows an example ‘’data at rest’ test result.
Facilitating self-service data? Integrating new tooling? But just to be safe, here are a few tips: Document your current dataschema and lineage. This will be important when you have to cross-reference your old data ecosystem with your new one. Better governance? What does success look like?
It also discusses several kinds of data. Schemas are available in various shapes and sizes, and the star schema and the snowflake schema are two of the most common. Entities in a star schema are depicted as stars, whereas those in a snowflake schema are depicted as snowflakes.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
Interoperability: By providing a standardized way of describing your customer domain, ontologies can facilitate dataintegration across different systems and even different brands within a larger corporation. we can evolve our customer data models faster than customers can change their minds – and that’s saying something!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content