This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Code allows for arbitrary levels of abstractions, allows for all logical operation in a familiar way, integrates well with source control, is easy to version and to collaborate on. Let’s highlight the fact that the abstractions exposed by traditional ETLtools are off-target.
Are you trying to better understand the plethora of ETLtools available in the market to see if any of them fits your bill? Are you a Snowflake customer (or planning on becoming one) looking to extract and load data from a variety of sources? If any of the above questions apply to you, then […]
It is important to note that normalization often overlaps with the data cleaning process, as it helps to ensure consistency in data formats, particularly when dealing with different sources or inconsistent units. Data Validation Data validation ensures that the data meets specific criteria before processing.
Integrity is a critical aspect of data processing; if the integrity of the data is unknown, the trustworthiness of the information it contains is unknown. What is DataIntegrity? Dataintegrity is the accuracy and consistency over the lifetime of the content and format of a data item.
The State of Customer Data The Modern Data Stack is all about making powerful marketing and sales decisions and performing impactful business analytics from a single source of truth. Customer DataIntegration makes this possible. Building a custom pipeline with a data engineering team can be an exhausting effort.
Tableau has helped numerous organizations understand their customer data better through their Visual Analytics platform. Data Visualization is the next step after the customer data present in rudimentary form has been cleaned, organized, transformed, and placed in a DataWarehouse. […]
What’s more, that data comes in different forms and its volumes keep growing rapidly every day — hence the name of Big Data. The good news is, businesses can choose the path of dataintegration to make the most out of the available information. Dataintegration in a nutshell. Dataintegration process.
To get a single unified view of all information, companies opt for dataintegration. In this article, you will learn what dataintegration is in general, key approaches and strategies to integrate siloed data, tools to consider, and more. What is dataintegration and why is it important?
ETL stands for Extract, Transform, and Load. ETL is a process of transferring data from various sources to target destinations/datawarehouses and performing transformations in between to make data analysis ready. Managing data is a tedious task if done manually and leads to no guarantee of accuracy.
StreamSets DataOps Platform is the world’s first single platform for building smart data pipelines across hybrid and multi-cloud architectures. Build, run, monitor and manage data pipelines confidently with an end-to-end dataintegration platform that’s built for constant change.
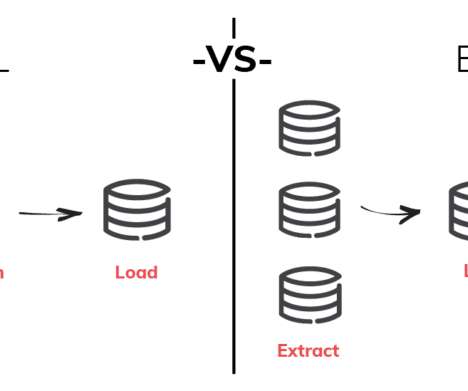
ETL stands for Extract, Transform, and Load, which involves extracting data from various sources, transforming the data into a format suitable for analysis, and loading the data into a destination system such as a datawarehouse. ETL developers play a significant role in performing all these tasks.
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
Data Engineers and Data Scientists require efficient methods for managing large databases, which is why centralized datawarehouses are in high demand. Cloud computing has made it easier for businesses to move their data to the cloud for better scalability, performance, solid integrations, and affordable pricing.
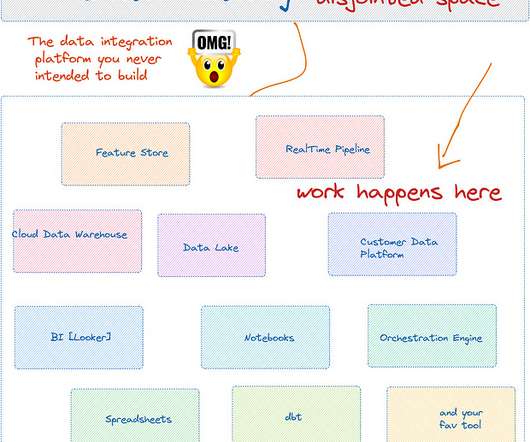
Data catalogs are the most expensive dataintegration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern data workflow, not just adding “modern” in its prefix. The modern(?)
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. Introduction to Apache Iceberg Tables Simplified dataintegrations Managed solutions like Fivetran and Stitch were built to manage third-party API integrations with ease.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
A data pipeline typically consists of three main elements: an origin, a set of processing steps, and a destination. Data pipelines are key in enabling the efficient transfer of data between systems for dataintegration and other purposes. Let’s take a closer look at some of the major components of a data pipeline.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a data storage (typically, a datawarehouse ), where it’s kept.
The ETLdataintegration process has been around for decades and is an integral part of data analytics today. In this article, we’ll look at what goes on in the ETL process and some modern variations that are better suited to our modern, data-driven society. What is ETL?
Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange. This indicates the growing use of the ETL process and various ETLtools and techniques across multiple industries.
Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance. Develop data models, data governance policies, and dataintegration strategies. Familiarity with ETLtools and techniques for dataintegration.
Today, organizations are adopting modern ETLtools and approaches to gain as many insights as possible from their data. However, to ensure the accuracy and reliability of such insights, effective ETL testing needs to be performed. So what is an ETL tester’s responsibility? Dataintegration testing.
The key distinctions between the two jobs are outlined in the following table: Parameter AWS Data Engineer Azure Data Engineer Platform Amazon Web Services (AWS) Microsoft Azure Data Services AWS Glue, Redshift, Kinesis, etc. Azure Data Factory, Databricks, etc.
It is the process of extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a target database or datawarehouse. ETL is used to integratedata from different sources and formats into a single target for analysis. What is an ETL Pipeline?
The conventional ETL software and server setup are plagued by problems related to scalability and cost overruns, which are ably addressed by Hadoop. If you encounter Big Data on a regular basis, the limitations of the traditional ETLtools in terms of storage, efficiency and cost is likely to force you to learn Hadoop.
The architecture of a data lake project may contain multiple components, including the Data Lake itself, one or multiple DataWarehouses or one or multiple Data Marts. The Data Lake acts as the central repository for aggregating data from diverse sources in its raw format.
Redshift is no longer a true competitor in the warehouse space. 1 On dbt; Yes, I completely agree with the author’s take that it lacks the basic functionality expected of a best-in-class tool. Meta shares its ever-changing landscape of data engineering. Airflow is obsolete. Airbyte is not production-grade software. #1
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. process data in real time and run streaming analytics. In other words, Kafka can serve as a messaging system, commit log, dataintegrationtool, and stream processing platform.
This data can be structured, semi-structured, or entirely unstructured, making it a versatile tool for collecting information from various origins. The extracted data is then duplicated or transferred to a designated destination, often a datawarehouse optimized for Online Analytical Processing (OLAP).
Top 10 Azure Data Engineer Tools I have compiled a list of the most useful Azure Data Engineer Tools here, please find them below. Azure Data Factory Azure Data Factory is a cloud ETLtool for scale-out serverless dataintegration and data transformation.
And at IMPACT, Maxime shared his key predictions for the future of data engineering. Watch his entire talk here , or read on for five key takeaways about the post-modern data stack. Now, according to Maxime, a new trend is emerging that could have a similar effect on data engineering workloads: reverse ETL.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a data processing method that involves extracting data from its source, loading it into a database or datawarehouse, and then later transforming it into a format that suits business needs. The extraction process requires careful planning to ensure dataintegrity.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
In this article, we’ll delve into what is an automated ETL pipeline, explore its advantages over traditional ETL, and discuss the inherent benefits and characteristics that make it indispensable in the data engineering toolkit. What Is an Automated ETL Pipeline? Read More: What is ETL? The result?
As data volumes explode across enterprises, the struggle to manage, integrate, and analyze it is getting real. Thankfully, with serverless dataintegration solutions like Azure Data Factory (ADF), data engineers can easily orchestrate, integrate, transform, and deliver data at scale.
It’s a Swiss Army knife for data pros, merging dataintegration, warehousing, and big data analytics into one sleek package. In other words, Synapse lets users ingest, prepare, manage, and serve data for immediate BI and machine learning needs. Is Azure Synapse an ETLtool? No worries.
With over 20 pre-built connectors and 40 pre-built transformers, AWS Glue is an extract, transform, and load (ETL) service that is fully managed and allows users to easily process and import their data for analytics. You can leverage AWS Glue to discover, transform, and prepare your data for analytics.
Here are some common examples: Merging Data Sources : Combining data from multiple sources into one cohesive dataset for analysis, facilitating comprehensive insights. Cleaning Data: Removing irrelevant or unnecessary data, ensuring that only pertinent information is used for analysis. What are data wrangling challenges?
Data Modeling The process of creating a logical and physical data model for a system is known as data modeling. Understanding data modeling concepts like entity-relationship diagrams, data normalization, and dataintegrity is a requirement for an Azure Data Engineer.
Generally, data pipelines are created to store data in a datawarehouse or data lake or provide information directly to the machine learning model development. Keeping data in datawarehouses or data lakes helps companies centralize the data for several data-driven initiatives.
They help organizations understand the dependencies between data sources, processes, and systems, enabling better data governance and impact analysis. They provide insights into the health of dataintegration processes, detect issues in real-time, and enable teams to optimize data flows.
Introduction Amazon Redshift, a cloud datawarehouse service from Amazon Web Services (AWS), will directly query your structured and semi-structured data with SQL. Amazon Redshift Serverless allows customers to analyze and query data without configuring and managing a datawarehouse.
Tableau Prep has brought in a new perspective where novice IT users and power users who are not backward faithfully can use drag and drop interfaces, visual data preparation workflows, etc., simultaneously making raw data efficient to form insights. Validate dataintegrity at key stages to maintain accuracy throughout your flow.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. You shall know database creation, data manipulation, and similar operations on the data sets. Your organization will use internal and external sources to port the data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content