This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Takeaways Trusted data is critical for AI success. Dataintegration ensures your AI initiatives are fueled by complete, relevant, and real-time enterprise data, minimizing errors and unreliable outcomes that could harm your business. Dataintegration solves key business challenges.
Key Takeaways: Harness automation and dataintegrity unlock the full potential of your data, powering sustainable digital transformation and growth. Data and processes are deeply interconnected. Today, automation and dataintegrity are increasingly at the core of successful digital transformation.
Key Takeaways: New AI-powered innovations in the Precisely DataIntegrity Suite help you boost efficiency, maximize the ROI of data investments, and make confident, data-driven decisions. These enhancements improve data accessibility, enable business-friendly governance, and automate manual processes.
Struggling to handle messy data silos? Fear not, data engineers! This blog is your roadmap to building a dataintegration bridge out of chaos, leading to a world of streamlined insights. That's where dataintegration comes in, like the master blacksmith transforming scattered data into gleaming insights.
When companies work with data that is untrustworthy for any reason, it can result in incorrect insights, skewed analysis, and reckless recommendations to become dataintegrity vs data quality. Two terms can be used to describe the condition of data: dataintegrity and data quality.
Register now Home Insights Data platform Article How To Use Airbyte, dbt-teradata, Dagster, and Teradata Vantage™ for Seamless DataIntegration Build and orchestrate a data pipeline in Teradata Vantage using Airbyte, Dagster, and dbt. Register now Join us at Possible 2025.
A large international scientist collaboration released The Well : 2 massive datasets from physics simulation (15TB) to astronomical scientific data (100TB). The future of data querying with Natural Language — What are all the architecture block needed to make natural language query working with data (esp.
To gather all the necessary information we need to infere a Database Schema to ChatGPT including example datasets and field descriptions by using few-shot prompting. We will start out propagating the Database Schema and some example data to ChatGPT.
Key Takeaways: Dataintegrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Data quality and data governance are the top dataintegrity challenges, and priorities. AI drives the demand for dataintegrity.
Do ETL and dataintegration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular dataintegration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
Summary One of the perennial challenges posed by data lakes is how to keep them up to date as new data is collected. With the improvements in streaming engines it is now possible to perform all of your dataintegration in near real time, but it can be challenging to understand the proper processing patterns to make that performant.
A report by ResearchAndMarkets projects the global dataintegration market size to grow from USD 12.24 This growth is due to the increasing adoption of cloud-based dataintegration solutions such as Azure Data Factory. What is Azure Data Factory? billion in 2020 to USD 24.84 billion by 2025, at a CAGR of 15.2%
For example: Text Data: Natural Language Processing (NLP) techniques are required to handle the subtleties of human language, such as slang, abbreviations, or incomplete sentences. Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets.
With global data creation projected to grow to more than 180 zettabytes by 2025 , it’s not surprising that more organizations than ever are looking to harness their ever-growing datasets to drive more confident business decisions.
Diverse and Rich Historical Data Mainframes store decades’ worth of transactional data. This data captures historical trends and behaviors across different demographics, markets, and socioeconomic conditions. Contextual Insights Historical data from mainframes provides context that is often missing in newer datasets.
In 2023, organizations dealt with more data than ever and witnessed a surge in demand for artificial intelligence use cases – particularly driven by generative AI. They relied on their data as a critical factor to guide their businesses to agility and success. These more complete datasets will both reduce bias and increase accuracy.
Finally, the challenge we are addressing in this document – is how to prove the data is correct at each layer.? How do you ensure data quality in every layer? The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment.
First: It is critical to set up a thorough data inventory and assessment procedure. Organizations must do a comprehensive inventory of their current data repositories, recording the data sources, kind, structure, and quality before starting dataintegration.
Showing how Kappa unifies batch and streaming pipelines The development of Kappa architecture has revolutionized data processing by allowing users to quickly and cost-effectively reduce dataintegration costs. Stream processors, storage layers, message brokers, and databases make up the basic components of this architecture.
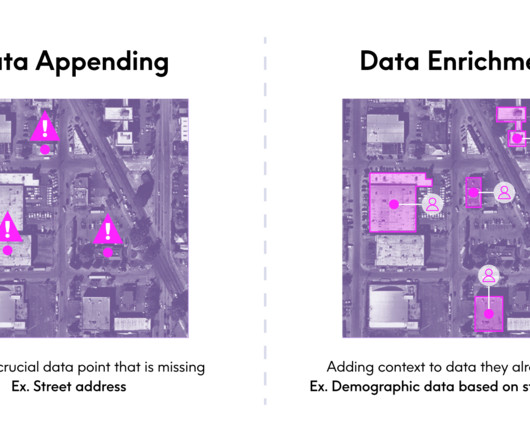
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” We often use different terms when were talking about the same thing in this case, data appending vs. data enrichment.
Random data doesn’t do it — and production data is not safe (or legal) for developers to use. What if you could mimic your entire production database to create a realistic dataset with zero sensitive data? Random data doesn’t do it — and production data is not safe (or legal) for developers to use.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. This project will help analyze user data for actionable insights. Utilize the Spotify Million Playlist Dataset to study user listening patterns.
An open-source AI-driven data quality testing that learns from your data automatically while providing a simple UI, not a code-specific DSL, to review, improve, and manage your data quality test estatea Test Generator. The Challenge of Writing Manual Data Quality Testing Organizations often have hundreds or thousands of tables.
CDC allows applications to respond to these changes in real-time, making it an essential component for dataintegration, replication, and synchronization. Real-Time Data Processing : CDC enables real-time data processing by capturing changes as they happen. Why is CDC Important?
These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets. Databricks and Apache Spark provide robust parallel processing capabilities for big data workloads, making it easier to distribute tasks across multiple nodes and improve throughput.
Key Takeaways: Dataintegrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Data quality and data governance are the top dataintegrity challenges, and priorities. AI drives the demand for dataintegrity.
2025 Outlook: Essential DataIntegrity Insights Whats trending in trusted data and AI readiness for 2025? Read the report Poor Address Data is Expensive in More Ways Than One Working with address data comes with unique challenges, and poor-quality data can have far-reaching effects on your business operations.
Traditional databases may need help to provide the necessary performance when dealing with large datasets and complex queries. Data warehousing tools are designed to handle such scenarios efficiently, enabling faster query performance and analysis, even on massive datasets. Familiar SQL language for querying.
Features of Apache Spark Allows Real-Time Stream Processing- Spark can handle and analyze data stored in Hadoop clusters and change data in real time using Spark Streaming. Spark uses Resilient Distributed Dataset (RDD), which allows it to keep data in memory transparently and read/write it to disc only when necessary.
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. This foundational dataset is essential, as it supports various downstream workflows and enables a multitude of usecases.
Why do data engineers love Azure Data Factory? Is Azure Data Factory Real-Time? What is Azure Data Factory? You can use Azure Data Factory to construct and plan data-driven processes (also known as pipelines) that can consume data from many sources.
Let us understand how this Microsoft Azure Data Factory Training will benefit data engineers in different ways- Comprehensive Understanding of Azure Data Factory- The training provides beginners with a solid foundation in understanding Azure Data Factory's core concepts and functionalities.
Key Takeaways: Data enrichment is the process of appending your first-party data with contextually rich third-party data, enabling you to make more data-driven decisions. Third-party data should be relevant, consistent, accessible, and trustworthy. Is data complete across pertinent geographies?
This is where ETL tools, such as Talend, come in handy as they help businesses manage cloud and dataintegration activities efficiently. If you are willing to enter the big data industry and searching for some good Talend projects for resume, you must explore some of the unique Talend ETL projects in this blog.
What is data enrichment? Data enrichment is the process of augmenting your organizations internal data with trusted, curated third-party datasets. Its key to delivering the context required to achieve overall dataintegrity. First, well start with the basics in case a refresher is needed.
Here is the list of AWS Data pipeline tools, designed for scalability and efficiency in handling data processing tasks within the AWS ecosystem. Data Catalog : Its integrateddata catalog automatically discovers and catalogs metadata from various sources, making it easy to find and understand datasets.
With the rapid growth of data in the industry, businesses often deal with several challenges when handling complex processes such as dataintegration and analytics. This increases the demand for big data processing tools such as AWS Glue.
As Databricks has revealed, a staggering 73% of a company's data goes unused for analytics and decision-making when stored in a data lake. Built on datasets that fail to capture the majority of a company's data, these models are doomed to return inaccurate results. Write data in delta format by using the below command.
Similarly, data teams might struggle to determine actionable steps if the metrics do not highlight specific datasets, systems, or processes contributing to poor data quality. This approach allows enterprises to hold data suppliers accountable or optimize their ingestion processes to ensure higher dataintegrity.
Target Data Completeness This involves validating the presence of expected records and the population of required fields in the target dataset, preventing data loss and supporting comprehensive analysis. Record Completeness: Record completeness checks assess whether all expected records are present in the target dataset.
DataOps emphasizes automation, version control, and streamlined workflows to reduce the time it takes to move data from ingestion to actionable insights. Monitor and Test Data Quality : Build automated testing and monitoring into your data workflows. Scalability: Implement scalable solutions to accommodate growing data volumes.
This influx of data and surging demand for fast-moving analytics has had more companies find ways to store and process data efficiently. This is where Data Engineers shine! The first step in any data engineering project is a successful data ingestion strategy. What are the parameters involved in Data Ingestion?
Combined with other Snowflake offerings, Cortex Agents now provide an end to end solution for retrieving, processing and governing both structured and unstructured data at scale. Snowflake's support for unstructured data includes capabilities to store, access, process, manage, govern and share such data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content