This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional datalakes, enter the world of Databricks Delta Lake now. Delta Lake is a game-changer for big data.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
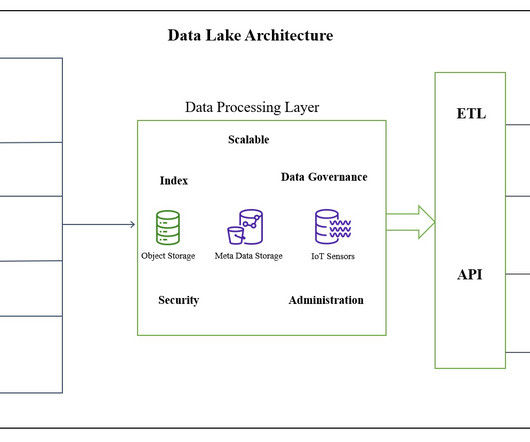
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
This guide is your roadmap to building a datalake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable datalake. That’s where datalakes come in. Table of Contents What is a DataLake?
In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time datalake without all of the headache. What is the impact of continuous data flows on dags/orchestration of transforms? RudderStack also supports real-time use cases.
Many organizations are struggling to store, manage, and analyze data due to its exponential growth. Cloud-based datalakes allow organizations to gather any form of data, whether structured or unstructured, and make this data accessible for usage across various applications, to address these issues.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
Did you know that the global datalakes market will likely grow at a CAGR of 29.9% Modern businesses are more likely to make data-driven decisions. Organizations are generating a massive volume of data due to the rise in digitalization. What is Azure DataLake ? and reach USD 17.60 billion by 2026?
Microsoft offers Azure DataLake, a cloud-based data storage and analytics solution. It is capable of effectively handling enormous amounts of structured and unstructured data. Therefore, it is a popular choice for organizations that need to process and analyze big data files.
Digital tools and technologies help organizations generate large amounts of data daily, requiring efficient governance and management. This is where the AWS datalake comes in. With the AWS datalake, organizations and businesses can store, analyze, and process structured and unstructured data of any size.
A comparative overview of data warehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
Responding to data overload with a security datalake Security professionals have to continually up their game to make sure that, from all the data at their disposal, theyre using the correct inputs to identify vulnerabilities and incidents. In it, we discuss three layers of AI that can become an attack surface.
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. Well also dive into […] The post How to Use Apache Iceberg Tables? appeared first on Analytics Vidhya.
Deploying upstream data profiling, validation, and cleansing rules was required to ensure garbage wasnt coming in, and suddenly organizations were discussing their plans for big data governance when they had yet to figure out how to implement little data governance. A datalake!
A few months ago, I uploaded a video where I discussed data warehouses, datalakes, and transactional databases. However, the world of data management is evolving rapidly, especially with the resurgence of AI and machine learning.
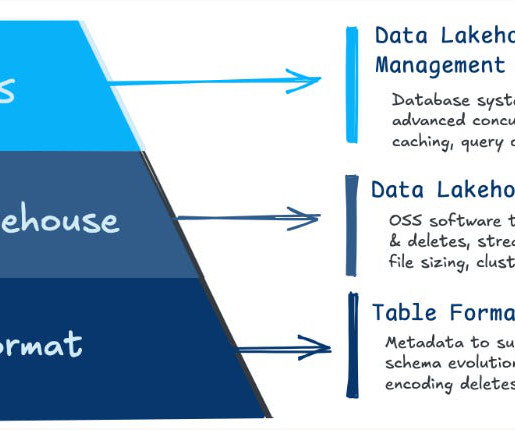
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. Visit [dataengineeringpodcast.com/data-council]([link] and use code *depod20* to register today!
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
Datalake structure 5. Loading user purchase data into the data warehouse 5.2 Loading classified movie review data into the data warehouse 5.3 Introduction 2. Objective 3. Prerequisite 4.2 AWS Infrastructure costs 4.3 Code walkthrough 5.1 Generating user behavior metric 5.4. Checking results 6.
We thank Vishnu Vettrivel, Founder, and Alex Thomas, Principal Data Scientist, for their contributions. This is a collaborative post from Databricks and wisecube.ai.
It combines the flexibility and scalability of datalake storage with the data analytics, data governance, and data management functionality of the data warehouse.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. Datalakes in various forms have been gaining significant popularity as a unified interface to an organization's analytics. When is Fabric the wrong choice?
Data stewards can also set up Request for Access (private preview) by setting a new visibility property on objects along with contact details so the right person can easily be reached to grant access.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Before it migrated to Snowflake in 2022, WHOOP was using a catalog of tools — Amazon Redshift for SQL queries and BI tooling, Dremio for a datalake, PostgreSQL databases and others — that had ultimately become expensive to manage and difficult to maintain, let alone scale.
What if your datalake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data.
Conclusion By understanding how transaction logs work in MySQL and PostgreSQL, we gain valuable insights into how CDC tools leverage these logs to perform incremental replication to downstream systems such as streaming applications, datalakes, and analytics platforms.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
Azure Data Factory is a cloud-based, fully managed, serverless ETL and data integration service offered by Microsoft Azure for automating data movement from its native place to, say, a datalake or data warehouse using ETL (extract-transform-load) OR extract-load-transform (ELT).
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform.
It offers a simple and efficient solution for data processing in organizations. It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, data warehouses , etc., where it can be used to facilitate business decisions.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content