This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI data engineers are data engineers that are responsible for developing and managing datapipelines that support AI and GenAI data products. Essential Skills for AI Data Engineers Expertise in DataPipelines and ETL Processes A foundational skill for data engineers?
Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructureddata, most enterprises manage and deliver data to the datalake and leverage various applications like ETL tools, search engines, and databases for analysis.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the datalake. As a result, monitoring data in real time was often an afterthought.
Lastly, companies have historically collaborated using inefficient and legacy technologies requiring file retrieval from FTP servers, API scraping and complex datapipelines. These processes were costly and time-consuming and also introduced governance and security risks, as once data is moved, customers lose all control.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. What is DataLake? .
A well-executed datapipeline can make or break your company’s ability to leverage real-time insights and stay competitive. Thriving in today’s world requires building modern datapipelines that make moving data and extracting valuable insights quick and simple. What is a DataPipeline?
A robust data infrastructure is a must-have to compete in the F1 business. We’ll build a data architecture to support our racing team starting from the three canonical layers : DataLake, Data Warehouse, and Data Mart. in alphabetical order: Apache Airflow, Azure Data Factory, DBT, Google DataForm, …).
Learn how we build datalake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently. And what is the reason for that?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
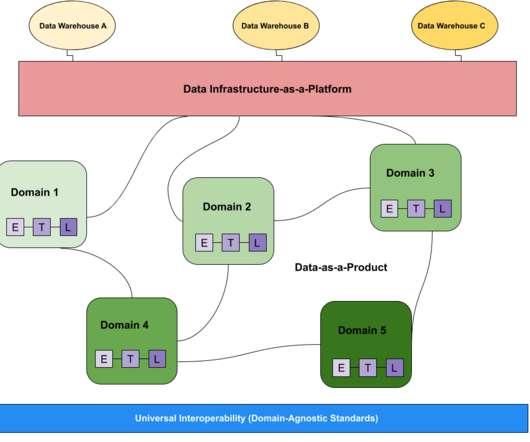
From origin through all points of consumption both on-prem and in the cloud, all data flows need to be controlled in a simple, secure, universal, scalable, and cost-effective way. controlling distribution while also allowing the freedom and flexibility to deliver the data to different services is more critical than ever. .
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build datalakes and ingest raw data extracted from different sources, including structured, semi-structured, and unstructureddata.
Datapipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a DataPipeline? The Importance of a DataPipeline What is an ETL DataPipeline?
Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken datapipelines. images, documents, etc.)
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
Previously, working with these large and complex files would require a unique set of tools, creating data silos. Now, with unstructureddata processing natively supported in Snowflake, we can process netCDF file types, thereby unifying our datapipeline. Mike Tuck, Air Pollution Specialist Why unstructureddata?
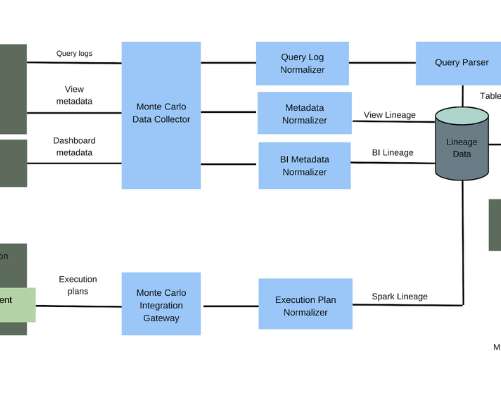
When a datapipeline breaks, data engineers need to immediately understand where the rupture occurred and what has been impacted. Data downtime is costly. Field-level data lineage (not necessarily Spark lineage) with hundreds of connections between objects in upstream and downstream tables.
As a result, here’s a short list of what inspired me to write an amendment to my original 2021 article : Scale Companies, big and small, are starting to reach levels of data scale previously reserved for Netflix, Uber, Spotify and other giants creating unique services with data.
Clusters in Databricks Databricks offers Job clusters for datapipeline processing and warehouse clusters used for the SQL lakehouse. Ideal for real-time analytics, high-performance caching, or machine learning, but data does not persist after instance termination. Job clusters have far more sizing options.
Evolution of DataLake Technologies The datalake ecosystem has matured significantly in 2024, particularly in table formats and storage technologies. Infrastructure Cost Management PayPal achieved remarkable results by leveraging Spark 3 and NVIDIA's GPUs , reducing cloud costs by up to 70% for their big datapipelines.
Companies today have structured and unstructureddata in multiple SaaS applications, databases, etc. Moving their data into a data warehouse/ datalake for analytics can be a challenge. In this article, let us […]
link] Zendesk: dbt at Zendesk The Zendesk team shares their journey of migrating legacy datapipelines to dbt, focusing on making them more reliable, efficient, and scalable. The article also highlights sink-specific improvements and operator-specific enhancements that contribute to the overall performance boost.
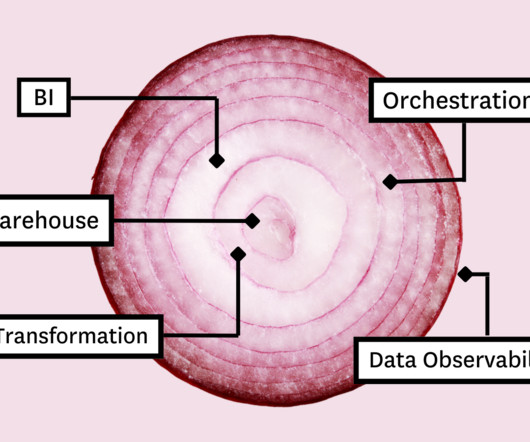
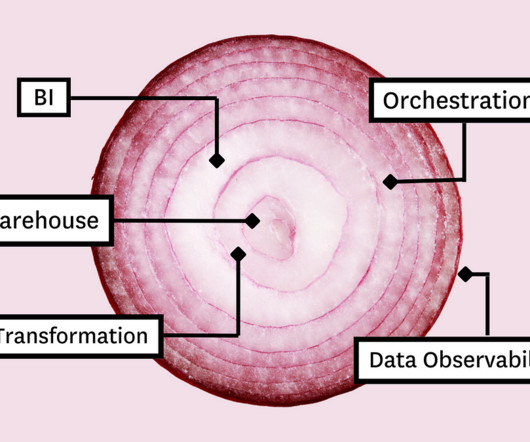
Like bean dip and ogres , layers are the building blocks of the modern data stack. Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the datapipeline. Image courtesy of Databricks.
Datapipelines are messy. Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale data processing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Datalake or warehouse?
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape. Let’s take a closer look.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. . CRM platforms).
Like bean dip and ogres , layers are the building blocks of the modern data stack. Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the datapipeline.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like datapipelines, data storage and retrieval, data orchestrators or infrastructure-as-code.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
From exploratory data analysis (EDA) and data cleansing to data modeling and visualization, the greatest data engineering projects demonstrate the whole data process from start to finish. Datapipeline best practices should be shown in these initiatives. Source Code: Yelp Review Analysis 2.
Depending on the quantity of data flowing through an organization’s pipeline — or the format the data typically takes — the right modern table format can help to make workflows more efficient, increase access, extend functionality, and even offer new opportunities to activate your unstructureddata.
As the data analyst or engineer responsible for managing this data and making it usable, accessible, and trustworthy, rarely a day goes by without having to field some request from your stakeholders. But what happens when the data is wrong? In our opinion, data quality frequently gets a bad rep.
In a nutshell, DataOps engineers are responsible not only for designing and building datapipelines, but iterating on them via automation and collaboration as well. BONUS INTERVIEW QUESTION How would you tackle a datapipeline performance problem? Reliable data starts with your data observability platform.
A person who designs and implements data management , monitoring, security, and privacy utilizing the entire suite of Azure data services to meet an organization's business needs is known as an Azure Data Engineer. The main exam for the Azure data engineer path is DP 203 learning path.
To help organizations realize the full potential of their datalake and lakehouse investments, Monte Carlo, the data observability leader, is proud to announce integrations with Delta Lake and Databricks’ Unity Catalog for full data observability coverage. billion in 2020 to 17.60 billion in 2020 to 17.60
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Over the past decade, Databricks and Apache Spark™ not only revolutionized how organizations store and process their data, but they also expanded what’s possible for data teams by operationalizing datalakes at an unprecedented scale across nearly infinite use cases. billion in 2020 to $17.6
Unstructureddata not ready for analysis: Even when defenders finally collect log data, it’s rarely in a format that’s ready for analysis. Cyber logs are often unstructured or semi-structured, making it difficult to derive insights from them.
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructureddata. Data Engineering Data engineering is a process by which data engineers make data useful.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content