This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source data ingestion and processing framework designed to simplify data management complexities.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
Learn how we build datalake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.
A datalake is essentially a vast digital dumping ground where companies toss all their rawdata, structured or not. An example of a data pipeline structure. But behind the scenes, Uber is also a leader in using data for business decisions, thanks to its optimized datalake.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, rawdata was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
Think of it as the “slow and steady wins the race” approach to dataprocessing. Stream Processing Pattern Now, imagine if instead of waiting to do laundry once a week, you had a magical washing machine that could clean each piece of clothing the moment it got dirty. The data lakehouse has got you covered!
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. Use VDK to build a datalake and merge multiple sources.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Ripple's Journey and Challenges with the Legacy System Our legacy system was once at the forefront of big dataprocessing, but as our operations grew, we faced a tangle of complexities. High maintenance costs and a system that struggled to meet the real-time demands of our data-driven initiatives.
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. How Does AWS Glue Work?
Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale dataprocessing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Batch or stream processing? Datalake or warehouse?
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, datalakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
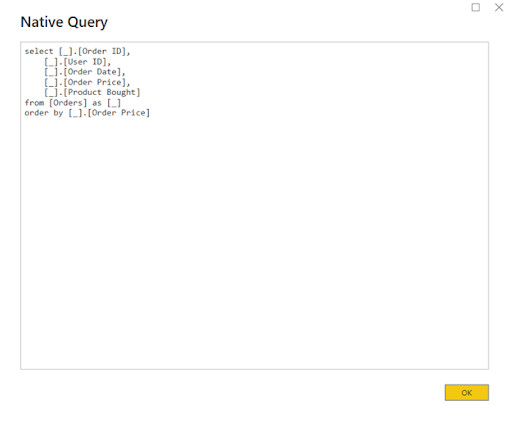
In other words, it acted as an input data source, taking much of the work on dataprocessing and transferring within Power BI. Power Query will automatically execute Query Folding under the following conditions: A data source is an object that can process query requests, just like a database used in most cases.
In the early days, many companies simply used Apache Kafka ® for data ingestion into Hadoop or another datalake. ® , Go, and Python SDKs where an application can use SQL to query rawdata coming from Kafka through an API (but that is a topic for another blog). However, Apache Kafka is more than just messaging.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized dataprocessing with their advanced massively parallel processing (MPP) capabilities and SQL support.
Generally, data pipelines are created to store data in a data warehouse or datalake or provide information directly to the machine learning model development. Keeping data in data warehouses or datalakes helps companies centralize the data for several data-driven initiatives.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of rawdata.
Unstructured data , on the other hand, is unpredictable and has no fixed schema, making it more challenging to analyze. Without a fixed schema, the data can vary in structure and organization. Once the unstructured data has been collected, the next step is to store and process this data effectively.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. How ELT Works The process of ELT can be broken down into the following three stages: 1. What Is ELT? So, what exactly is ELT?
Companies are drowning in a sea of rawdata. As data volumes explode across enterprises, the struggle to manage, integrate, and analyze it is getting real. Thankfully, with serverless data integration solutions like Azure Data Factory (ADF), data engineers can easily orchestrate, integrate, transform, and deliver data at scale.
The key differentiation lies in the transformational steps that a data pipeline includes to make data business-ready. Ultimately, the core function of a pipeline is to take rawdata and turn it into valuable, accessible insights that drive business growth. best suit our processeddata? cleaning, formatting)?
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
This process is typically referred to as ETL and the stages include: Extraction: Collecting rawdata from multiple sources such as databases, APIs, logs, or files. Transformation: Cleaning, enhancing, and converting data for analysis or storage.
Origin The origin of a data pipeline refers to the point of entry of data into the pipeline. This includes the different possible sources of data such as application APIs, social media, relational databases, IoT device sensors, and datalakes.
Challenges of Legacy Data Architectures Some of the main challenges associated with legacy data architectures include: Lack of flexibility: Traditional data architectures are often rigid and inflexible, making it difficult to adapt to changing business needs and incorporate new data sources or technologies.
It is a data integration process with which you first extract raw information (in its original formats) from various sources and load it straight into a central repository such as a cloud data warehouse , a datalake , or a data lakehouse where you transform it into suitable formats for further analysis and reporting.
It’s designed to improve upon the performance and usability challenges of older data storage formats such as Apache Hive and Apache Parquet. Use incremental processing Iceberg supports incremental processing, in other words reading only the data that has changed between two snapshots.
Data from these sources are often ingested into a cloud-based data warehouse or datalake , where they can then be mined for information and insights. Source : Fundamentals of Data Engineering by Joe Reis and Matt Housley.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big dataprocessing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
An Azure Data Engineer is responsible for designing, implementing and managing data solutions on Microsoft Azure. The Azure Data Engineer certification imparts to them a deep understanding of dataprocessing, storage and architecture.
This involves connecting to multiple data sources, using extract, transform, load ( ETL ) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content